Schema registry ES on Cloud
This documentation aims to be a introductory hands-on lab on IBM Event Streams on IBM Cloud Schema Registry where we will go through the different capabilities of the Schema Registry that is available for IBM Event Streams on IBM Cloud users.
We strongly recommend to complete first the IBM Event Streams on IBM Cloud lab you can find here.
Index¶
Requirements¶
This lab requires the following components to work against:
- An IBM Cloud account.
- An IBM Event Streams instance with the Enterprise plan (Schema Registry is only available to these instance for now) - https://cloud.ibm.com/docs/EventStreams?topic=eventstreams-getting_started
On your development workstation you will need:
- (optional) IBM Cloud CLI - https://cloud.ibm.com/docs/cli?topic=cloud-cli-getting-started
- (optional) IBM CLoud CLI Event Streams plugin - https://cloud.ibm.com/docs/EventStreams?topic=eventstreams-cli#step5_es_cli
- Docker - https://docs.docker.com/get-docker/
- Kafdrop - https://github.com/obsidiandynamics/kafdrop
IBM Event Streams Service Credentials¶
At this point, we want to create the needed service credentials in order to allow other applications, tools, scripts to interact with our IBM Event Streams instance. For doing so, we need to:
-
In your IBM Event Streams instance service page, click on Service credentials on the left hand side menu:
-
Observe, there is no service credentials yet and click on the New credential button on the top right corner:
-
Enter a name for your service, choose Manager role for now and click on Add:
-
You should now see your new service credential and be able to inspect its details if you click on its dropdown arrow on it left:
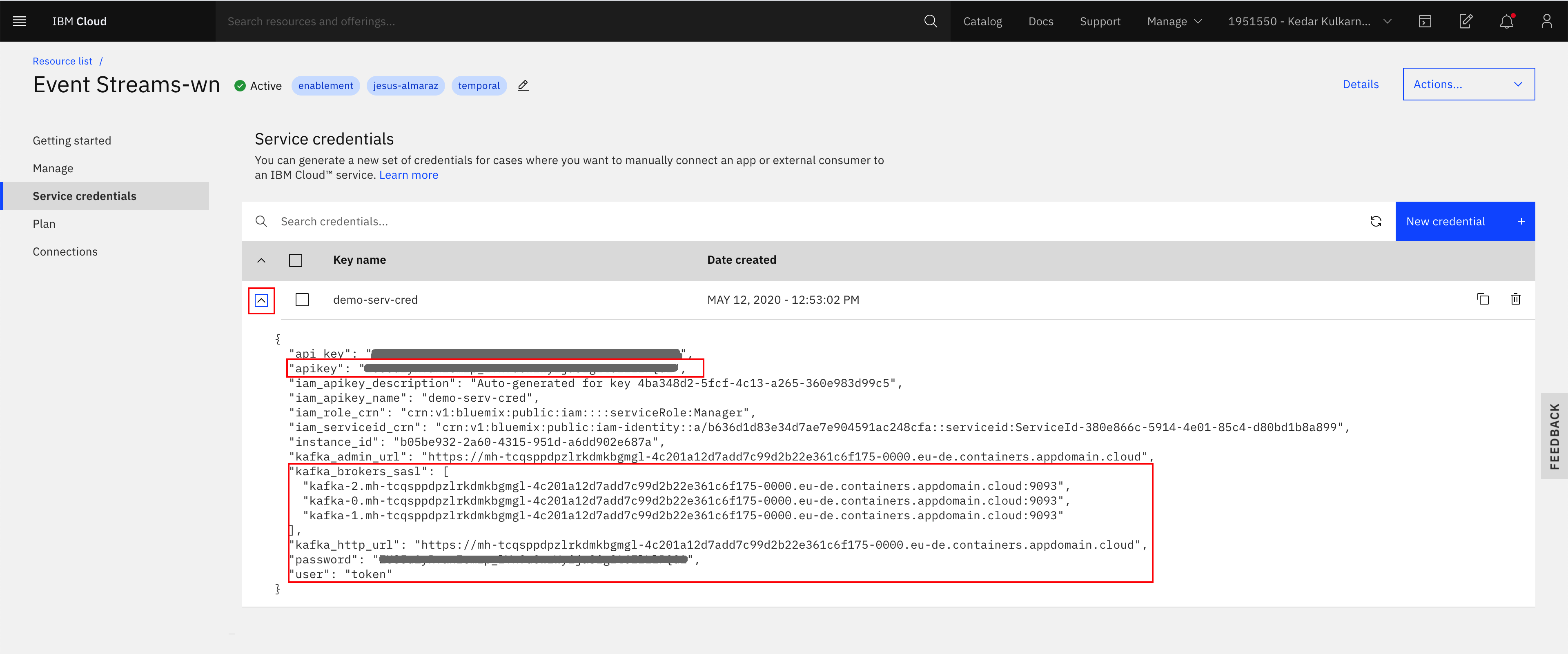
-
We could have created the service credentials using the CLI as well but we leave that as extra homework for students to try on their own. However, we can explore the service credentials using the CLI with
ibmcloud resource service-key <service_credentials_name>:$ ibmcloud resource service-key demo-serv-cred Retrieving service key demo-serv-cred in all resource groups under account Kedar Kulkarni's Account as ALMARAZJ@ie.ibm.com... Name: demo-serv-cred ID: crn:v1:bluemix:public:messagehub:eu-de:a/b636d1d83e34d7ae7e904591ac248cfa:b05be932-2a60-4315-951d-a6dd902e687a:resource-key:4ba348d2-5fcf-4c13-a265-360e983d99c5 Created At: Tue May 12 10:53:02 UTC 2020 State: active Credentials: api_key: ***** apikey: ***** iam_apikey_description: Auto-generated for key 4ba348d2-5fcf-4c13-a265-360e983d99c5 iam_apikey_name: demo-serv-cred iam_role_crn: crn:v1:bluemix:public:iam::::serviceRole:Manager iam_serviceid_crn: crn:v1:bluemix:public:iam-identity::a/b636d1d83e34d7ae7e904591ac248cfa::serviceid:ServiceId-380e866c-5914-4e01-85c4-d80bd1b8a899 instance_id: b05be932-2a60-4315-951d-a6dd902e687a kafka_admin_url: https://mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud kafka_brokers_sasl: [kafka-2.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093 kafka-0.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093 kafka-1.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093] kafka_http_url: https://mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud password: ***** user: token
IMPORTANT: Out of number 4 above, we are going to define the following important environment variables that will be used throughout this lab so please make sure you understand and define these properly
-
KAFKA_BROKERS which should take the value of kafka_brokers_sasl comma separated:
export KAFKA_BROKERS=kafka-2.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-1.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-0.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093 -
KAFKA_APIKEY which should take the value of apikey:
-
URL which should take the value of kafka_http_url:
-
SCHEMA_REGISTRY_URL which should be a combination of the three before in the form of:
https://token:<apikey>@<kafka_http_url>/confluent
INFO: The reason for this "weird" schema registry url configuration is because we are using the Confluent SerDes as we will see in the Python Avro Producer and Python Avro Consumer sections later on. Otherwise, the schema registry url would simply be the same as the kafka_http_url in your service credentials.
Kafdrop¶
Kafdrop is a web UI for viewing Kafka topics and browsing consumer groups. The tool displays information such as brokers, topics, partitions, consumers, and lets you view messages: https://github.com/obsidiandynamics/kafdrop
Kafdrop runs as a Docker container in your wokstation and in order to run it,
-
Set the password value for the sasl.jaas.config property in the kafka.properties file you can find in this repo. The value for password is the api_key/password attributes of your service credentials. If you don't remember how to get this, review that section here
-
Run the Kafdrop Docker container by executing:
(*) After running the above command, you can use the docker container id returned on the screen to debug any possible issue with$ docker run -d --rm -p 9000:9000 \ -e KAFKA_BROKERCONNECT=$KAFKA_BROKERS \ -e KAFKA_PROPERTIES=$(cat kafka.properties | base64) \ -e JVM_OPTS="-Xms32M -Xmx64M" \ -e SERVER_SERVLET_CONTEXTPATH="/" \ obsidiandynamics/kafdropdocker logs -f <container_id>. This container id will be used to stop the Kafdrop container once we have finished. -
You can point your browser to http://localhost:9000/ to access the Kafdrop application:
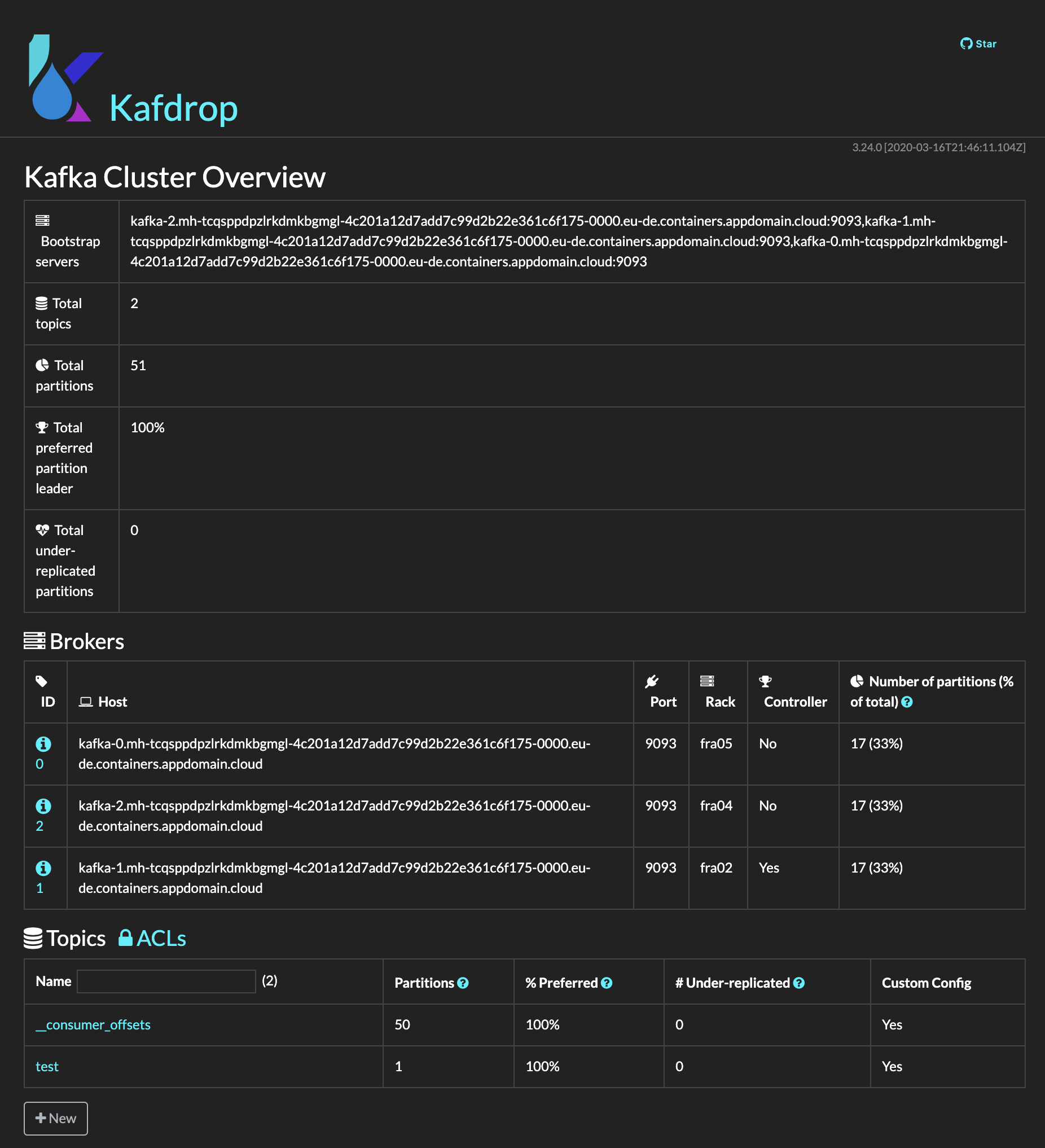
-
You can see the topic details by clicking on the name of that topic:
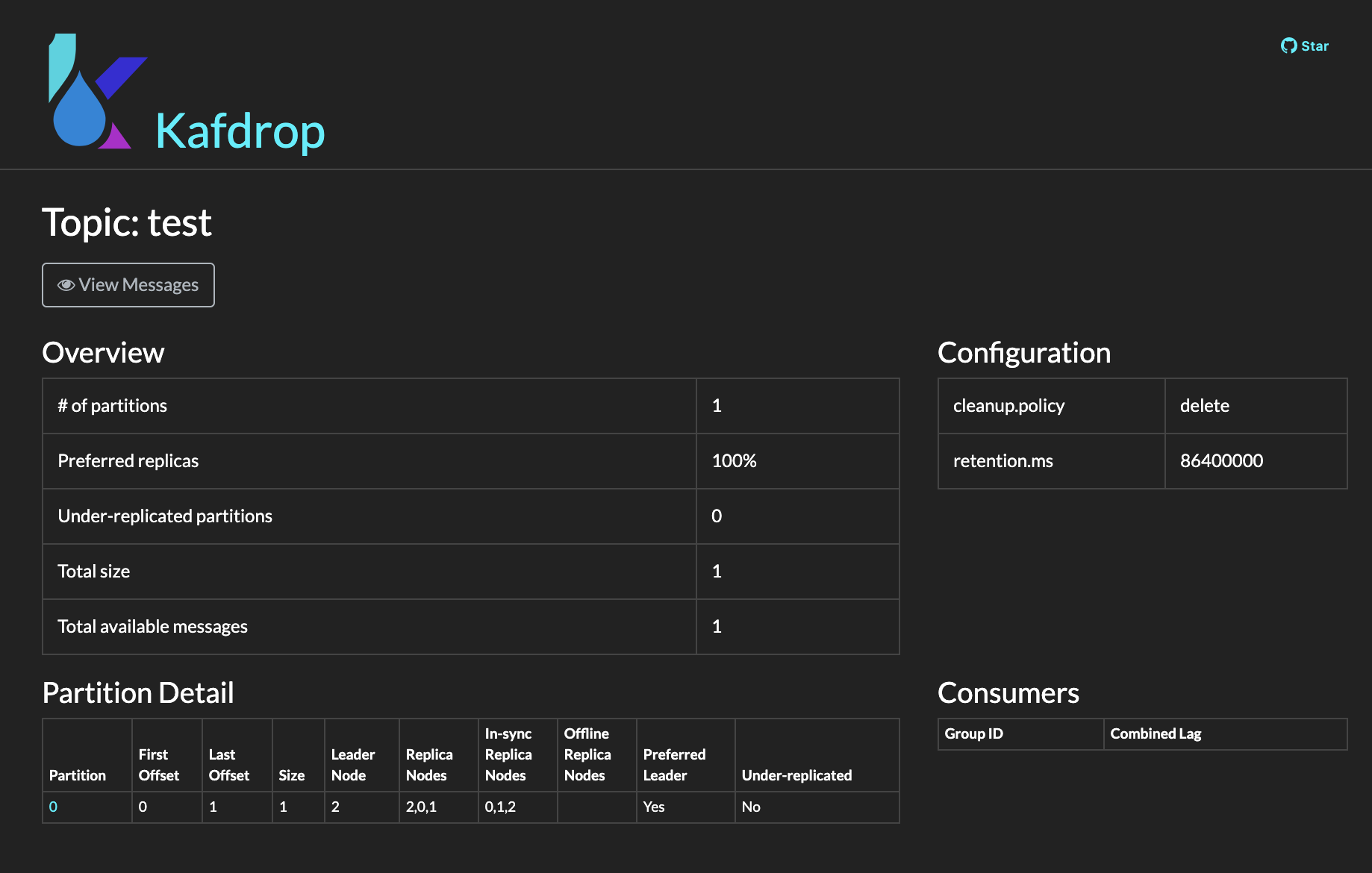
-
You can watch the messages on this topic by clicking on View Messages button under the topic name and configuring the partition, offset and number of messages option that you are presented with in the next screen. Finally, click on View Messages button at the right:
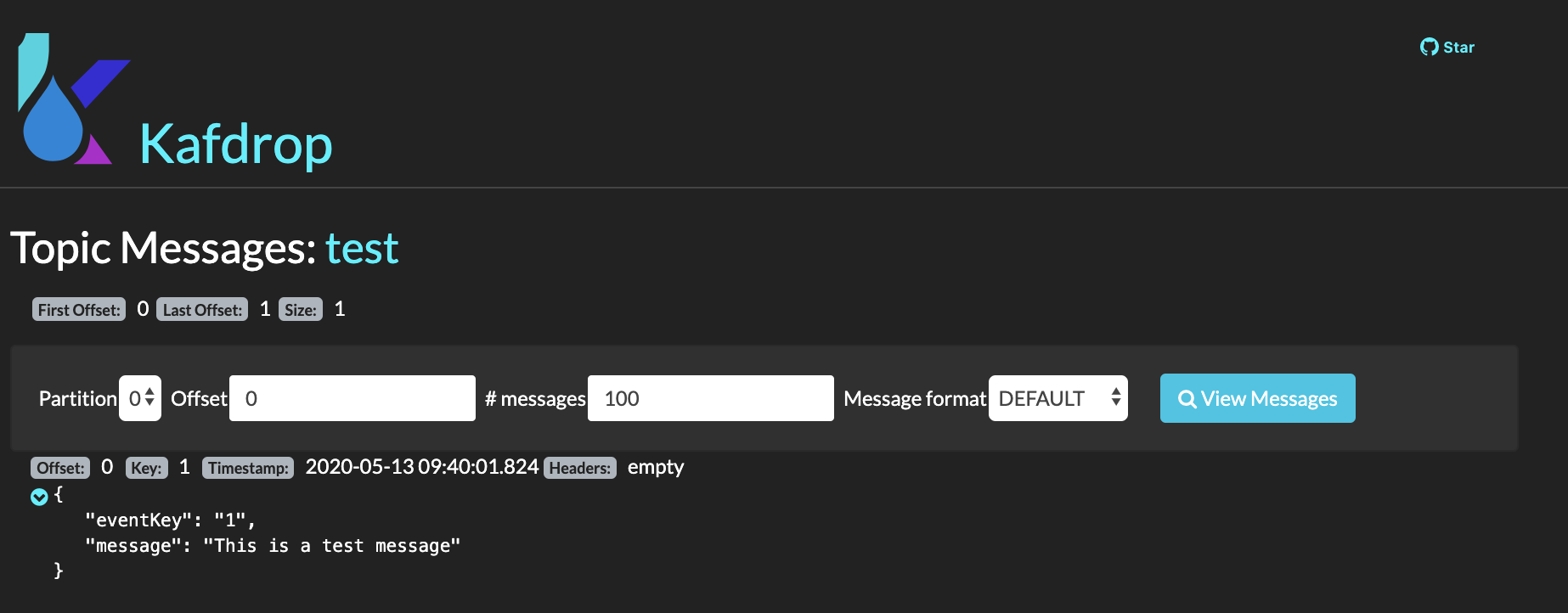
-
To stop the Kafdrop container once you have finsihed the tutorial, simply list the containers running on your workstation, find the container id for your Kafdrop container and stop it:
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ba6c8eaf6a3a ibmcase/python-schema-registry-lab:latest "bash" 31 seconds ago Up 30 seconds keen_neumann bab9cae43f15 obsidiandynamics/kafdrop "/kafdrop.sh" 17 minutes ago Up 17 minutes 0.0.0.0:9000->9000/tcp laughing_dirac $ docker stop bab9cae43f15 bab9cae43f15
Python Demo Environment¶
Given that students' workstations may vary quite a lot, not only on their operating system but also on the tools installed on them and the tools we need for our lab might install differently, we have opted to provide a python demo environment in the form of a Docker container where all the libraries and tools needed are already pre-installed.
Clone¶
In order to build our python demo environment we first need to clone the github repository where the assets live. This github repository is https://github.com/ibm-cloud-architecture/refarch-eda-tools and the specific assets we refer to can be found under the labs/es-cloud-schema-lab folder:
-
Clone the github repository on your workstation on the location of your choice:
$ git clone https://github.com/ibm-cloud-architecture/refarch-eda-tools.git Cloning into 'refarch-eda-tools'... remote: Enumerating objects: 185, done. remote: Counting objects: 100% (185/185), done. remote: Compressing objects: 100% (148/148), done. remote: Total 185 (delta 23), reused 176 (delta 16), pack-reused 0 Receiving objects: 100% (185/185), 6.17 MiB | 4.61 MiB/s, done. Resolving deltas: 100% (23/23), done. -
Change directory into
refarch-eda-tools/labs/es-cloud-schema-labto find the assets we will we working from now on for the python demo environment and few other scripts/applications:$ cd refarch-eda-tools/labs/es-cloud-schema-lab $ ls -all total 240 drwxr-xr-x 9 user staff 288 20 May 19:33 . drwxr-xr-x 3 user staff 96 20 May 19:33 .. -rw-r--r-- 1 user staff 1012 20 May 19:33 Dockerfile -rw-r--r-- 1 user staff 112578 20 May 19:33 README.md drwxr-xr-x 5 user staff 160 20 May 19:33 avro_files drwxr-xr-x 27 user staff 864 20 May 19:33 images drwxr-xr-x 6 user staff 192 20 May 19:33 kafka -rw-r--r-- 1 user staff 286 20 May 19:33 kafka.properties drwxr-xr-x 6 user staff 192 20 May 19:33 src
Build¶
This Docker container can be built by using the Dockerfile provided within this github repository.
To build your python demo environment Docker container, execute the following on your workstation:
WARNING:
- Mind the dot at the end of the command.
- Be consistent throughout the lab with the name you give to the Docker container.
Run¶
In order to run the python demo environment Docker container, execute the following on your workstation:
-
Make sure you have declared your
KAFKA_BROKERS,KAFKA_APIKEYandSCHEMA_REGISTRY_URLenvironment variables as explain in the IBM Event Streams Service Credentials section. -
Run the python demo environment container
-
Go to
/tmp/labto find all the assets you will need to complete this lab.
INFO: we have mounted this working directory into the container so any changes to any of the files apply within the container. This is good as we do not need to restart the python demo environment Docker container if we want to do any changes to the files.
Exit¶
Once you are done with the python demo environment container, just execute exit and you will get out of the container and the container will automatically be removed from your system.
Schema Registry¶
INFO: The following documentation about the IBM Event Streams on IBM Cloud Schema registry until the end of this lab is based on the Schema Registry status as of mid May 2020 when this tutorial was developed
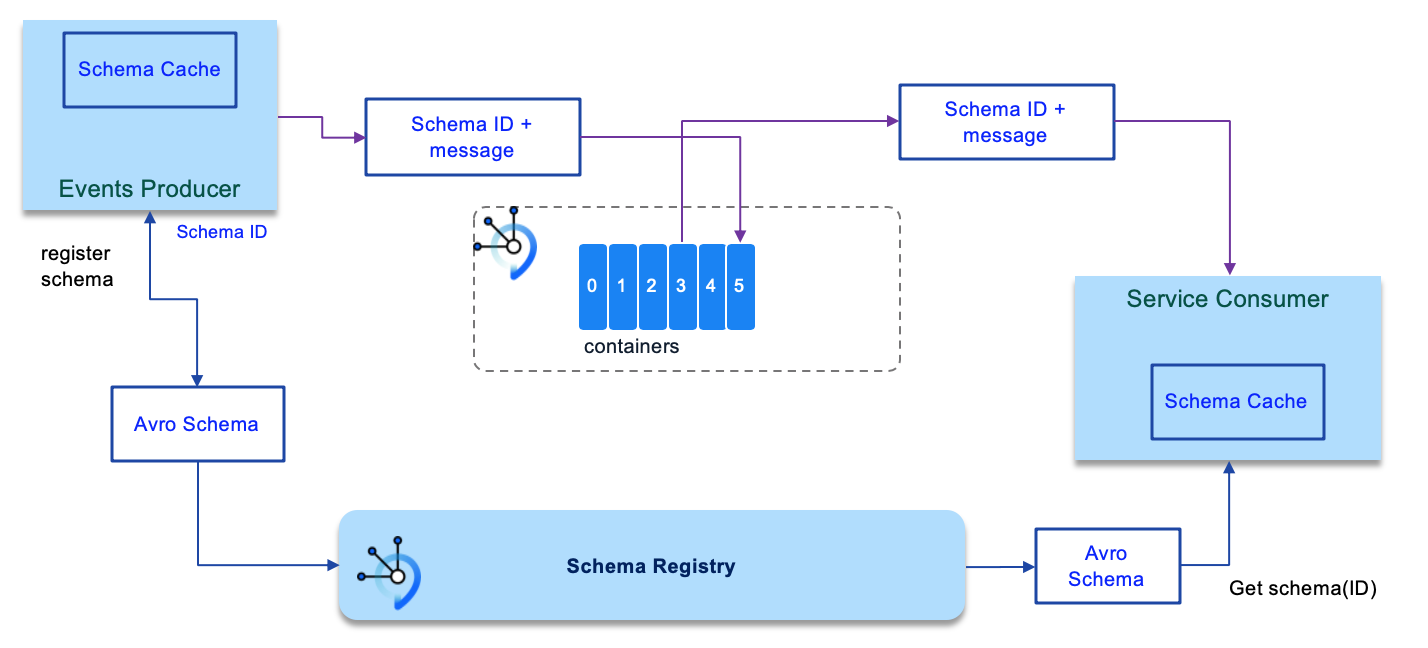
One of the most common technologies used in the industry these days to define, serialize and deserialize messages flowing through your Kafka topics is Apache Avro (https://avro.apache.org/docs/current/). To learn more about Apache Avro, how to define Apache Avro data schemas and more see our documentation here
IBM Event Streams on IBM Cloud development team has developed a Schema Registry to work along your Kafka cluster to provide centralized schema management and compatibility checks as schemas evolve so that the communication between Kafka producers and consumers follow these schemas for consistency or as many like to say, meet the contracts that schemas are.
Overview¶
The schema registry capability is being developed for the IBM Event Streams managed Kafka service running in IBM Cloud. The purpose of the schema registry is to provide a place to store descriptions of the message formats used by your producers and consumers. The benefit of storing these descriptions is that you are able to validate that your producing and consuming applications will correctly inter-operate.
Currently the schema registry is in early access status. This means that a limited function version of the registry is being made available to a small group of users for the purpose of gathering feedback, and rapidly iterating on the design of the registry. Please note that while the schema registry is in early access, there may be occasions when IBM will delete all of the schema data held within the registry.
Current features¶
- Support for creating, listing and deleting schemas via a REST interface
- Support for creating, listing and deleting versions of a schema, via a REST interface
- Support for using schema information in Kafka producer and consumer applications via the Confluent AVRO SerDes
- Support for Apache AVRO as the format used to express schemas
- Support for applying constraints on schema compatibility, either at a global scope, or on a per-schema basis
- Access to schema registry requires authentication and access is controlled via IAM
- Access to individual schemas, and compatibility rules can be controlled via a new IAM schema resource type
- Constraints on maximum schema size (64K), the maximum number of schemas that can be stored in the registry (1000) and the maximum number of versions a schema can have (100)
- SLA of 99.99% availability, consistent with that of the Event Streams service
Current limitations¶
- No caching performed for frequently requested schemas
- Does not publish metrics to Sysdig
- Does not generate Activity Tracker events
- There may be other missing functions that you require. Please let IBM know!
Enabling the Schema Registry¶
Currently the schema registry is not enabled by default and can only be enabled for IBM Event Streams Enterprise plan service instances. To request the enablement of the schema registry, please raise a support ticket here. Ensure that you include the CRN of your Event Streams service instance in the ticket. The CRN of the service instance can be found using the following IBM Cloud CLI command ibmcloud resource service-instance <SERVICENAME> (where SERVICENAME is the name of your Event Streams service instance). For more info on how to get your IBM Event Streams service instance CRN review the Event Streams on Cloud hands on lab.
If you have already enabled the schema registry capability for an Event Streams Enterprise plan service instance, it will automatically receive updates as new capabilities become available.
Accessing the Schema Registry¶
To access the schema registry, you will need the URL of the schema registry as well as a set of credentials that can be used to authenticate with the registry. Both of these pieces of information can be found by inspecting the service credentials for your service. To view these in the UI, click on your service instance, select Service credentials in the left-hand navigation pane, then click on the dropdown arrow next to one of the service credentials name listed in the table. You should see something like this:
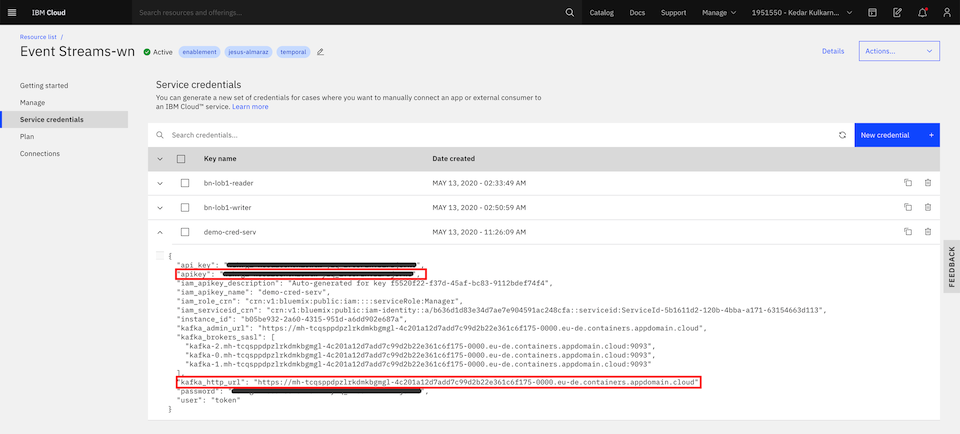
You will need the value of kafka_http_url, which is also the URL of the schema registry, and the value of apikey which you can use as the credential for authenticating with the schema registry.
To check we have appropriate permissions to work with the Schema Registry, we can execute the following command that would actually list the schemas stored in the schema registry in our terminal:
curl -i –u token:<KAFKA_APIKEY> <URL>/artifacts
curl -i -u token:***** https://mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud/artifacts
HTTP/1.1 200 OK
Date: Wed, 13 May 2020 11:38:36 GMT
Content-Type: application/json
Content-Length: 3
Connection: keep-alive
[]
As you can see, no schema is being retrieved which makes sense with the just out of the box schema registry status we are at.
INFO: For easiness executing the following schema registry REST API commands, we recommend you set your kafka_http_url and apikey as URL and KAFKA_APIKEY environment variables respectively as explained in the IBM Event Streams Service Credentials section.
Schemas¶
In this section we will finally get our hands dirty with the IBM Event Steams on IBM Cloud Schema Registry capability by working with Apache Avro schemas and the schema registry.
Create a schema¶
This endpoint is used to store a schema in the registry. The schema data is sent as the body of the post request. An ID for the schema can be included using the X-Registry-ArtifactId request header. If this header is not present in the request, then an ID will be generated. The content type header must be set to application/json.
Creating a schema requires at least both:
- Reader role access to the Event Streams cluster resource type
-
Writer role access to the schema resource that matches the schema being created
-
Create a schema with:
curl -u token:$KAFKA_APIKEY -H 'Content-Type: application/json' -H 'X- Registry-ArtifactId: <SCHEMA_ID>' $URL/artifacts -d '<AVRO_SCHEMA>'$ curl -u token:$KAFKA_APIKEY \ -H 'Content-Type: application/json' \ -H 'X-Registry-ArtifactId: demo-schema' \ $URL/artifacts \ -d '{ "type":"record", "name":"demoSchema", "fields":[ {"name": "eventKey","type":"string"}, {"name": "message","type":"string"}] }' {"id":"demo-schema","type":"AVRO","version":1,"createdBy":"","createdOn":1589371190273,"modifiedBy":"","modifiedOn":1589371190273,"globalId":1} -
Create a few more schemas.
List schemas¶
Listing schemas requires at least:
-
Reader role access to the Event Streams cluster resource type
-
List the schemas and see the ones you have created previously with:
curl -u token:$KAFKA_APIKEY $URL/artifacts
Delete schemas¶
Schemas are deleted from the registry by issuing a DELETE request to the /artifacts/{schema-id} endpoint (where {schema-id} is the ID of the schema). If successful an empty response, and a status code of 204 (no content) is returned.
Deleting a schema requires at least both:
- Reader role access to the Event Streams cluster resource type
-
Manager role access to the schema resource that matches the schema being deleted
-
Delete one (or all) of the schemas you created previously with:
curl -u token:$KAFKA_APIKEY -X DELETE $URL/artifacts/my-schema
Create new schema version¶
To create a new version of a schema, make a POST request to the /artifacts/{schema-id}/versions endpoint, (where {schema-id} is the ID of the schema). The body of the request must contain the new version of the schema.
If the request is successful the new schema version is created as the new latest version of the schema, with an appropriate version number, and a response with status code 200 (OK) and a payload containing metadata describing the new version, (including the version number), is returned.
Creating a new version of a schema requires at least both:
- Reader role access to the Event Streams cluster resource type
-
Writer role access to the schema resource that matches the schema getting a new version
-
Create a new schema:
$ curl -u token:$KAFKA_APIKEY \ -H 'Content-Type: application/json' \ -H 'X-Registry-ArtifactId: version-demo-schema' \ $URL/artifacts \ -d '{"type":"record", "name":"versionDemoSchema", "fields":[ {"name": "eventKey","type":"string"}, {"name": "message","type":"string"}] }' {"id":"version-demo-schema","type":"AVRO","version":1,"createdBy":"","createdOn":1589380529049,"modifiedBy":"","modifiedOn":1589380529049,"globalId":9} -
Add a new attribute to the schema and create a new version for it with:
curl -u token:$KAFKA_APIKEY -H 'Content-Type: application/json' $URL/artifacts/<SCHEMA_ID>/versions -d '<AVRO_SCHEMA'(*) See that the returned JSON object includes the version for the schema and that this has increased$ curl -u token:$KAFKA_APIKEY \ -H 'Content-Type: application/json' \ -H 'X-Registry-ArtifactId: version-demo-schema' \ $URL/artifacts/version-demo-schema/versions \ -d '{"type":"record", "name":"versionDemoSchema", "fields":[ {"name": "eventKey","type":"string"}, {"name": "message","type":"string"}, {"name": "attribute1","type":"string"}]}' {"id":"version-demo-schema","type":"AVRO","version":2,"createdBy":"","createdOn":1589380529049,"modifiedBy":"","modifiedOn":1589380728324,"globalId":10} -
Create yet another new attribute and version for the schema:
$ curl -u token:$KAFKA_APIKEY \ -H 'Content-Type: application/json' \ -H 'X-Registry-ArtifactId: version-demo-schema' \ $URL/artifacts/version-demo-schema/versions \ -d '{"type":"record", "name":"versionDemoSchema", "fields":[ {"name": "eventKey","type":"string"}, {"name": "message","type":"string"}, {"name": "attribute1","type":"string"}, {"name": "attribute2","type":"string"}]}' {"id":"version-demo-schema","type":"AVRO","version":3,"createdBy":"","createdOn":1589380529049,"modifiedBy":"","modifiedOn":1589380955324,"globalId":11}
Get latest version of a schema¶
To retrieve the latest version of a particular schema, make a GET request to the /artifacts/{schema-id} endpoint, (where {schema-id} is the ID of the schema). If successful, the latest version of the schema is returned in the payload of the response.
Getting the latest version of a schema requires at least both:
- Reader role access to the Event Streams cluster resource type
-
Reader role access to the schema resource that matches the schema being retrieved
-
Get the latest version of the schema with:
curl -u token:$KAFKA_APIKEY $URL/artifacts/<SCHEMA_ID>
Get specific version of a schema¶
To retrieve a specific version of a schema, make a GET request to the /artifacts/{schema-id}/versions/{version} endpoint, (where {schema-id} is the ID of the schema, and {version} is the version number of the specific version you need to retrieve). If successful, the specified version of the schema is returned in the payload of the response.
Getting the latest version of a schema requires at least both:
- Reader role access to the Event Streams cluster resource type
-
Reader role access to the schema resource that matches the schema being retrieved
-
Get a specific version of a schema with:
curl -u token:$KAFKA_APIKEY $URL/artifacts/<SCHEMA_ID>/versions/<VERSION_ID>
Listing all versions of a schema¶
To list all versions of a schema currently stored in the registry, make a GET request to the /artifacts/{schema-id}/versions endpoint, (where {schema-id} is the ID of the schema). If successful, a list of all current version numbers for the schema is returned in the payload of the response.
Getting the list of available versions of a schema requires at least both:
- Reader role access to the Event Streams cluster resource type
-
Reader role access to the schema resource that matches the schema being retrieved
-
Get all the versions for a schema with:
curl -u token:$KAFKA_APIKEY $URL/artifacts/<SCHEMA_ID>/versions
Deleting a version of a schema¶
Schema versions are deleted from the registry by issuing a DELETE request to the /artifacts/{schema-id}/versions/{version} endpoint (where {schema-id} is the ID of the schema, and {version} is the version number of the schema version). If successful an empty response, and a status code of 204 (no content) is returned. Deleting the only remaining version of a schema will also delete the schema.
Deleting a schema version requires at least both:
- Reader role access to the Event Streams cluster resource type
-
Manager role access to the schema resource that matches the schema being deleted
-
Delete a version of a schema with:
curl -u token:$KAFKA_APIKEY -X DELETE $URL/artifacts/<SCHEMA_ID>/versions/<VERSION_ID> -
Make sure your specific version has been deleted by listing all the version for that schema:
If you deleted a schema, it will get deleted along with all its versions.
Python Avro Producer¶
In this section we describe the python scripts we will be using in order to be able to produce avro messages to a Kafka topic.
Produce Message¶
The python script that we will use to send an avro message to a Kafka topic is ProduceAvroMessage.py where we have the following:
-
A function to parse the arguments:
-
A function to create the event to be sent:
-
The main where we will:
- Parse the arguments
- Get the Avro schemas for the key and value of the event
- Create the Event to be sent
- Print it out for reference
- Create the Kafka Avro Producer and configure it
- Send the event
if __name__ == '__main__': # Get the Kafka topic name parseArguments() # Get the avro schemas for the message's key and value event_value_schema = getDefaultEventValueSchema(DATA_SCHEMAS) event_key_schema = getDefaultEventKeySchema(DATA_SCHEMAS) # Create the event message_event = createEvent() # Print out the event to be sent print("--- Container event to be published: ---") print(json.loads(message_event)) print("----------------------------------------") # Create the Kafka Avro Producer kafka_producer = KafkaProducer(KAFKA_BROKERS,KAFKA_APIKEY,SCHEMA_REGISTRY_URL) # Prepare the Kafka Avro Producer kafka_producer.prepareProducer("ProduceAvroMessagePython",event_key_schema,event_value_schema) # Publish the event kafka_producer.publishEvent(TOPIC_NAME,message_event,"eventKey")
As you can see, this python code depends on a Kafka Avro Producer and an Avro Utils for loading the Avro schemas which are explained next.
Avro Utils¶
This script, called avroEDAUtils.py, contains some very simple utility functions to be able to load Avro schemas from their avsc files in order to be used by the Kafka Avro Producer.
-
A function to get the key and value Avro schemas for the messages to be sent:
(*) Wheredef getDefaultEventValueSchema(schema_files_location): # Get the default event value data schema known_schemas = avro.schema.Names() default_event_value_schema = LoadAvsc(schema_files_location + "/default_value.avsc", known_schemas) return default_event_value_schema def getDefaultEventKeySchema(schema_files_location): # Get the default event key data schema known_schemas = avro.schema.Names() default_event_key_schema = LoadAvsc(schema_files_location + "/default_key.avsc", known_schemas) return default_event_key_schemaknown_schemasis an Avro schema dictionary where all Avro schemas read get stored in order to be able to read nested Avro schemas afterwards. See the python script in detail for examples of this. -
A function to open a file, read its content as an Avro schema and store it in the Avro schema dictionary:
Kafka Avro Producer¶
This script, called KcAvroProducer.py, will actually be the responsible for creating the Kafka Avro Producer, initialize and configure it and provide the publish method:
-
Initialize and prepare the Kafka Producer
class KafkaProducer: def __init__(self,kafka_brokers = "",kafka_apikey = "",schema_registry_url = ""): self.kafka_brokers = kafka_brokers self.kafka_apikey = kafka_apikey self.schema_registry_url = schema_registry_url def prepareProducer(self,groupID = "pythonproducers",key_schema = "", value_schema = ""): options ={ 'bootstrap.servers': self.kafka_brokers, 'schema.registry.url': self.schema_registry_url, 'group.id': groupID, 'security.protocol': 'SASL_SSL', 'sasl.mechanisms': 'PLAIN', 'sasl.username': 'token', 'sasl.password': self.kafka_apikey } # Print out the configuration print("--- This is the configuration for the producer: ---") print(options) print("---------------------------------------------------") # Create the Avro Producer self.producer = AvroProducer(options,default_key_schema=key_schema,default_value_schema=value_schema) -
Publish method
def publishEvent(self, topicName, value, key): # Produce the Avro message # Important: value DOES NOT come in JSON format from ContainerAvroProducer.py. Therefore, we must convert it to JSON format first self.producer.produce(topic=topicName,value=json.loads(value),key=json.loads(value)[key], callback=self.delivery_report) # Flush self.producer.flush()
Run¶
We will see in the following section Schemas and Messages how to send Avro messages according with their schemas to IBM Event Streams.
Python Avro Consumer¶
In this section we describe the python scripts we will be using in order to be able to consume Avro messages from a Kafka topic.
Consume Message¶
The python script that we will use to consume an Avro message from a Kafka topic is ConsumeAvroMessage.py where we have the following:
-
A function to parse arguments:
# Parse arguments to get the container ID to poll for def parseArguments(): global TOPIC_NAME print("The arguments for the script are: " , str(sys.argv)) if len(sys.argv) != 2: print("[ERROR] - The ConsumeAvroMessage.py script expects one arguments: The Kafka topic to events from.") exit(1) TOPIC_NAME = sys.argv[1] -
The main where we will:
- Parse the arguments to get the topic to read from
- Create the Kafka Consumer and configure it
- Poll for next avro message
- Close the Kafka consumer
if __name__ == '__main__': # Parse arguments parseArguments() # Create the Kafka Avro consumer kafka_consumer = KafkaConsumer(KAFKA_BROKERS,KAFKA_APIKEY,TOPIC_NAME,SCHEMA_REGISTRY_URL) # Prepare the consumer kafka_consumer.prepareConsumer() # Consume next Avro event kafka_consumer.pollNextEvent() # Close the Avro consumer kafka_consumer.close()
As you can see, this python code depends on a Kafka Consumer which is explained next.
Kafka Avro Consumer¶
This script, called KcAvroConsumer.py, will actually be the responsible for creating the Kafka Avro Consumer, initialize and configure it and provide the poll next event method:
-
Initialize and prepare the new Kafka consumer:
class KafkaConsumer: def __init__(self, kafka_brokers = "", kafka_apikey = "", topic_name = "", schema_registry_url = "", autocommit = True): self.kafka_brokers = kafka_brokers self.kafka_apikey = kafka_apikey self.topic_name = topic_name self.schema_registry_url = schema_registry_url self.kafka_auto_commit = autocommit # See https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md def prepareConsumer(self, groupID = "pythonconsumers"): options ={ 'bootstrap.servers': self.kafka_brokers, 'group.id': groupID, 'auto.offset.reset': 'earliest', 'schema.registry.url': self.schema_registry_url, 'enable.auto.commit': self.kafka_auto_commit, 'security.protocol': 'SASL_SSL', 'sasl.mechanisms': 'PLAIN', 'sasl.username': 'token', 'sasl.password': self.kafka_apikey } # Print the configuration print("--- This is the configuration for the Avro consumer: ---") print(options) print("---------------------------------------------------") # Create the Avro consumer self.consumer = AvroConsumer(options) # Subscribe to the topic self.consumer.subscribe([self.topic_name]) -
Poll next event method:
# Prints out the message def traceResponse(self, msg): print('@@@ pollNextOrder - {} partition: [{}] at offset {} with key {}:\n\tvalue: {}' .format(msg.topic(), msg.partition(), msg.offset(), msg.key(), msg.value() )) # Polls for next event def pollNextEvent(self): # Poll for messages msg = self.consumer.poll(timeout=10.0) # Validate the returned message if msg is None: print("[INFO] - No new messages on the topic") elif msg.error(): if ("PARTITION_EOF" in msg.error()): print("[INFO] - End of partition") else: print("[ERROR] - Consumer error: {}".format(msg.error())) else: # Print the message msgStr = self.traceResponse(msg)
Run¶
We will see in the following section Schemas and Messages how to consume Avro messages.
Schemas and Messages¶
In this section we are going to see how Schema Registry works when you have an application that produces and consumes messages based on Avro data schemas. The application we are going to use for this is the python scripts presented above in the Python Avro Producer and Python Avro Consumer.
Once again, we are going to run these scripts in the python demo environment we presented earlier in this lab in this section. Please, review that section in order to understand how to run the environment in your local workstation.
-
Make sure you have a newly created topic for this exercise (review the IBM Event Streams on IBM Cloud lab if needed):
-
Make sure you dont have any schema registered (preferably for clarity):
-
Start your python environment with:
Create a message¶
In order to create a message, we execute the ProduceAvroMessage.py within the /tmp/lab/src folder in our python demo environment. This script, as you could see in the Python Avro Producer section, it is sending the event {'eventKey': '1', 'message': 'This is a test message'} according to the schemas defined in default_key.avsc and default_value.avsc for the key and value of the event respectively.
python ProduceAvroMessage.py test
@@@ Executing script: ProduceAvroMessage.py
The arguments for the script are: ['ProduceAvroMessage.py', 'test']
Creating event...
DONE
--- Container event to be published: ---
{'eventKey': '1', 'message': 'This is a test message'}
----------------------------------------
--- This is the configuration for the avro producer: ---
{'bootstrap.servers': 'kafka-2.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-1.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-0.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093', 'schema.registry.url': 'https://token:4uk9gZ-n85a2esMoMZ5wtW-yIq_29o3PrHVBEFBj67N0@mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud/confluent', 'group.id': 'ProduceAvroMessagePython', 'security.protocol': 'SASL_SSL', 'sasl.mechanisms': 'PLAIN', 'sasl.username': 'token', 'sasl.password': '*****'}
---------------------------------------------------
Message delivered to test [0]
We should now have a new message in our test kafka topic. We can check that out using Kafdrop:
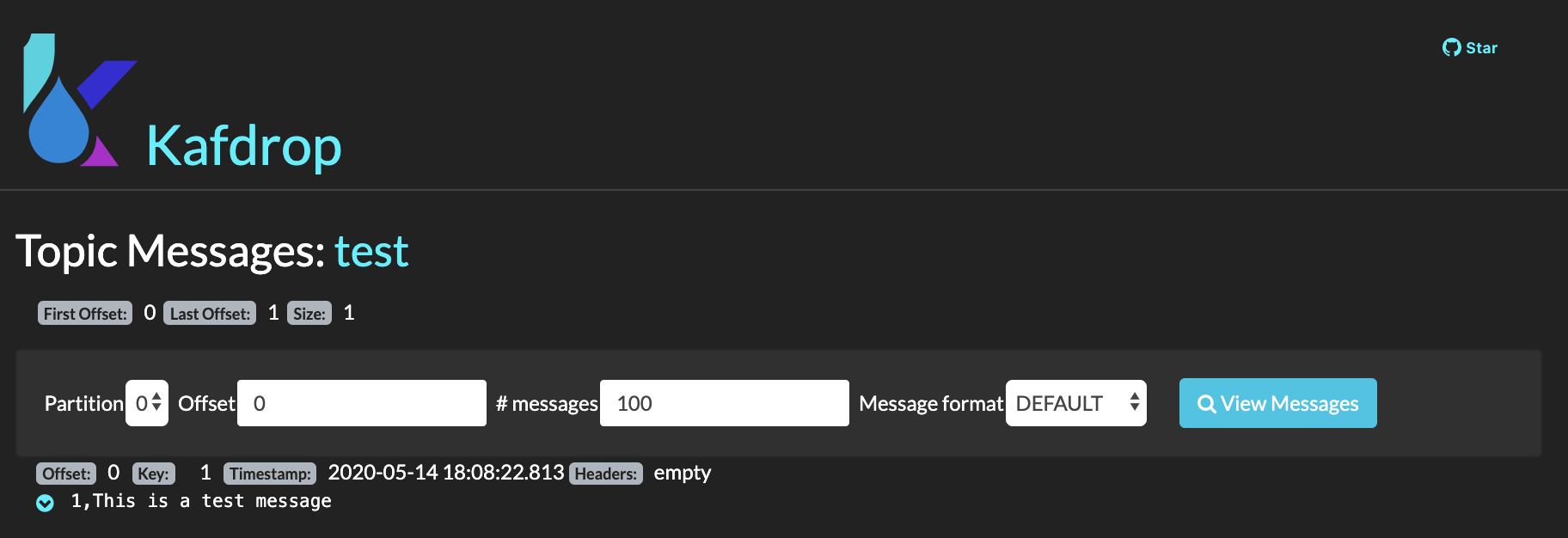
INFO: Mind the message now is not in JSON format as Avro does not repeat every field name with every single record which makes Avro more efficient than JSON for high-volume usage. This is thanks to having Avro schemas.
WARNING: Most of the Avro producer clients, whether it is in Java, Python or many other languages, give users the ability to auto-register a schema automatically with the specified schema registry in its configuration.
If we look know at the schemas our schema registry has:
we see two schemas, test-key and test-value, which in fact correspond to the Avro data schema used for the key (default_key.avsc) and the value (default_value.avsc) of events sent to the test topic in the ProduceAvroMessage.py as explained before sending the message.
To make sure of what we are saying, we can inspect those schemas:
$ curl -s -u token:$KAFKA_APIKEY $URL/artifacts/test-value | jq .
{
"type": "record",
"name": "defaultValue",
"namespace": "ibm.eda.default",
"fields": [
{
"type": "string",
"name": "eventKey",
"doc": "We expect any string as the event key"
},
{
"type": "string",
"name": "message",
"doc": "Any string message"
}
],
"doc": "Default Message's value Avro data schema, composed of the key again and any string message"
}
If I now decided that my events should contain another attribute, I would modify the event value schema (default_value.avsc) to reflect that as well as ProduceAvroMessage.py to send that new attribute in the event it sends:
# python ProduceAvroMessage.py test
@@@ Executing script: ProduceAvroMessage.py
The arguments for the script are: ['ProduceAvroMessage.py', 'test']
Creating event...
DONE
--- Container event to be published: ---
{'eventKey': '1', 'message': 'This is a test message', 'anotherAttribute': 'This is another atttribute'}
----------------------------------------
--- This is the configuration for the avro producer: ---
{'bootstrap.servers': 'kafka-2.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-1.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-0.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093', 'schema.registry.url': 'https://token:4uk9gZ-n85a2esMoMZ5wtW-yIq_29o3PrHVBEFBj67N0@mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud/confluent', 'group.id': 'ProduceAvroMessagePython', 'security.protocol': 'SASL_SSL', 'sasl.mechanisms': 'PLAIN', 'sasl.username': 'token', 'sasl.password': '*****'}
---------------------------------------------------
Message delivered to test [0]
I can see that an event with a new attribute has been sent:
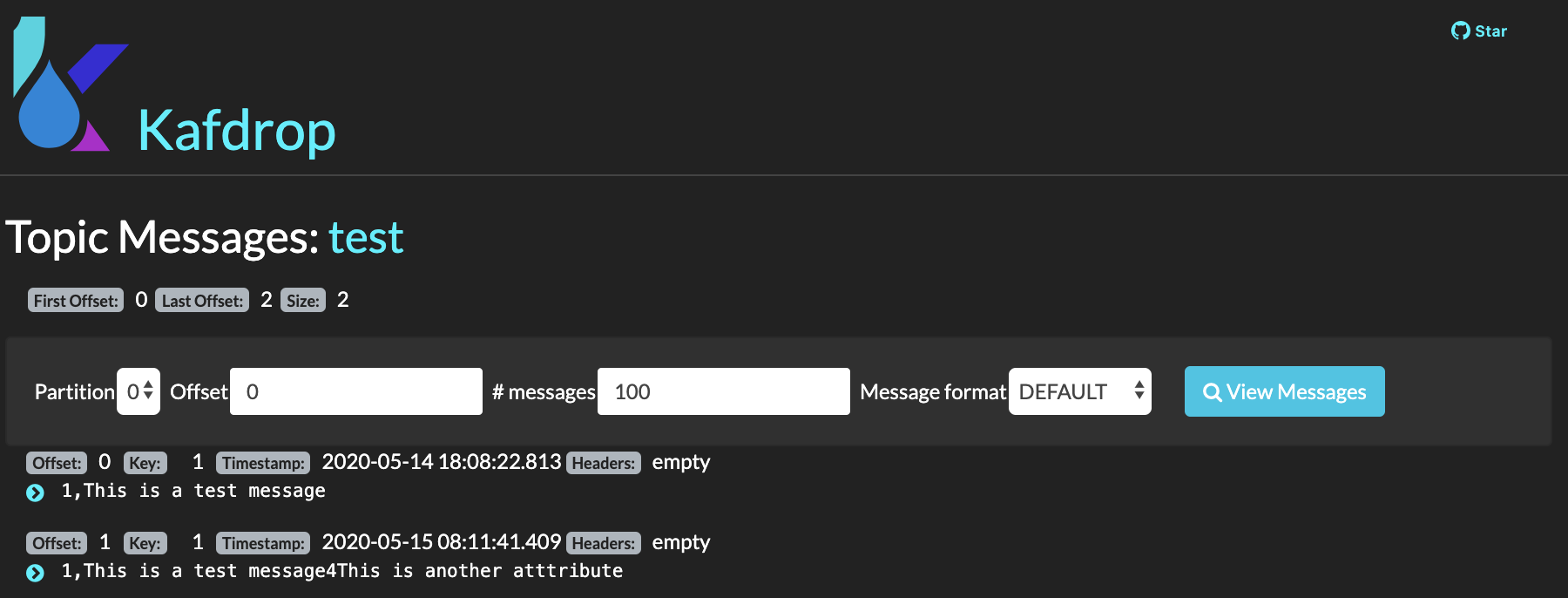
And I can also see that the new shcema has got registered as well as a new version for the already exisiting schema:
$ curl -s -u token:$KAFKA_APIKEY $URL/artifacts/test-value | jq .
{
"type": "record",
"name": "defaultValue",
"namespace": "ibm.eda.default",
"fields": [
{
"type": "string",
"name": "eventKey",
"doc": "We expect any string as the event key"
},
{
"type": "string",
"name": "message",
"doc": "Any string message"
},
{
"type": "string",
"name": "anotherAttribute",
"doc": "Another string attribute for demo"
}
],
"doc": "Default Message's value Avro data schema, composed of the key again and any string message"
}
SECURITY: As some of you may have already thought, having your clients (that is your applications), auto-register the Avro data schemas that are in the end kind of the contracts that your components of your overal solution agree on in order to understand each other and collaborate between them is NOT a good idea. Specially in microservices architectures where you might have hundreds of microservices talking and collaborating among themselsves. We will see in the Security section how we can control schema registration and evolution based on roles at the schema level also.
Create a non-compliant message¶
Now, we are trying to send a non-compliant message according to the Avro data schema we have for our events. Im going to try to send the following event:
{
'eventKey': '1',
'message': 'This is a test message',
'anotherAttribute': 'This is another atttribute',
'yetAnotherAttribute': 'This should fail'
}
and this is the output of that attempt:
# python ProduceAvroMessage.py test
@@@ Executing script: ProduceAvroMessage.py
The arguments for the script are: ['ProduceAvroMessage.py', 'test']
Creating event...
DONE
--- Container event to be published: ---
{'eventKey': '1', 'message': 'This is a test message', 'anotherAttribute': 'This is another atttribute', 'yetAnotherAttribute': 'This should fail'}
----------------------------------------
--- This is the configuration for the avro producer: ---
{'bootstrap.servers': 'kafka-2.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-1.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-0.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093', 'schema.registry.url': 'https://token:4uk9gZ-n85a2esMoMZ5wtW-yIq_29o3PrHVBEFBj67N0@mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud/confluent', 'group.id': 'ProduceAvroMessagePython', 'security.protocol': 'SASL_SSL', 'sasl.mechanisms': 'PLAIN', 'sasl.username': 'token', 'sasl.password': '*****'}
---------------------------------------------------
Traceback (most recent call last):
File "ProduceAvroMessage.py", line 77, in <module>
kp.publishEvent(TOPIC_NAME,message_event,"eventKey")
File "/tmp/lab/kafka/KcAvroProducer.py", line 39, in publishEvent
self.producer.produce(topic=topicName,value=json.loads(value),key=json.loads(value)[key], callback=self.delivery_report)
File "/root/.local/lib/python3.7/site-packages/confluent_kafka/avro/__init__.py", line 99, in produce
value = self._serializer.encode_record_with_schema(topic, value_schema, value)
File "/root/.local/lib/python3.7/site-packages/confluent_kafka/avro/serializer/message_serializer.py", line 118, in encode_record_with_schema
return self.encode_record_with_schema_id(schema_id, record, is_key=is_key)
File "/root/.local/lib/python3.7/site-packages/confluent_kafka/avro/serializer/message_serializer.py", line 152, in encode_record_with_schema_id
writer(record, outf)
File "/root/.local/lib/python3.7/site-packages/confluent_kafka/avro/serializer/message_serializer.py", line 86, in <lambda>
return lambda record, fp: writer.write(record, avro.io.BinaryEncoder(fp))
File "/root/.local/lib/python3.7/site-packages/avro/io.py", line 771, in write
raise AvroTypeException(self.writer_schema, datum)
avro.io.AvroTypeException: The datum {'eventKey': '1', 'message': 'This is a test message', 'anotherAttribute': 'This is another atttribute', 'yetAnotherAttribute': 'This should fail'} is not an example of the schema {
"type": "record",
"name": "defaultValue",
"namespace": "ibm.eda.default",
"fields": [
{
"type": "string",
"name": "eventKey",
"doc": "We expect any string as the event key"
},
{
"type": "string",
"name": "message",
"doc": "Any string message"
},
{
"type": "string",
"name": "anotherAttribute",
"doc": "Another string attribute for demo"
}
],
"doc": "Default Message's value Avro data schema, composed of the key again and any string message"
}
As we can see, the attempt failed as the Avro producer will check the message against the Avro data schema defined for the topic we want to send the message to and yield that this message does not comply.
Therefore, using Avro schemas with IBM Event Streams give us the ability to build our system with robustness protecting downstream data consumers from malformed data, as only valid data will be permitted in the topic.
Consume a message¶
In order to consume a message, we execute the ConsumeAvroMessage.py within the /tmp/lab/src folder in our python demo environment:
# python ConsumeAvroMessage.py test
@@@ Executing script: ConsumeAvroMessage.py
The arguments for the script are: ['ConsumeAvroMessage.py', 'test']
--- This is the configuration for the Avro consumer: ---
{'bootstrap.servers': 'kafka-2.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-1.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-0.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093', 'group.id': 'pythonconsumers', 'auto.offset.reset': 'earliest', 'schema.registry.url': 'https://token:4uk9gZ-n85a2esMoMZ5wtW-yIq_29o3PrHVBEFBj67N0@mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud/confluent', 'enable.auto.commit': True, 'security.protocol': 'SASL_SSL', 'sasl.mechanisms': 'PLAIN', 'sasl.username': 'token', 'sasl.password': '*****'}
---------------------------------------------------
[Message] - Next message consumed from test partition: [0] at offset 0 with key 1:
value: {'eventKey': '1', 'message': 'This is a test message'}
# python ConsumeAvroMessage.py test
@@@ Executing script: ConsumeAvroMessage.py
The arguments for the script are: ['ConsumeAvroMessage.py', 'test']
--- This is the configuration for the Avro consumer: ---
{'bootstrap.servers': 'kafka-2.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-1.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093,kafka-0.mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud:9093', 'group.id': 'pythonconsumers', 'auto.offset.reset': 'earliest', 'schema.registry.url': 'https://token:4uk9gZ-n85a2esMoMZ5wtW-yIq_29o3PrHVBEFBj67N0@mh-tcqsppdpzlrkdmkbgmgl-4c201a12d7add7c99d2b22e361c6f175-0000.eu-de.containers.appdomain.cloud/confluent', 'enable.auto.commit': True, 'security.protocol': 'SASL_SSL', 'sasl.mechanisms': 'PLAIN', 'sasl.username': 'token', 'sasl.password': '*****'}
---------------------------------------------------
[Message] - Next message consumed from test partition: [0] at offset 1 with key 1:
value: {'eventKey': '1', 'message': 'This is a test message', 'anotherAttribute': 'This is another atttribute'}
As you can see, our script was able to read the Avro messages from the test topic and map that back to their original structure thanks to the Avro schemas:
[Message] - Next message consumed from test partition: [0] at offset 0 with key 1:
value: {'eventKey': '1', 'message': 'This is a test message'}
[Message] - Next message consumed from - test partition: [0] at offset 1 with key 1:
value: {'eventKey': '1', 'message': 'This is a test message', 'anotherAttribute': 'This is another atttribute'}
Data Evolution¶
So far we have more or less seen what Avro is, what an Avro data schema is, what a schema registry is and how this all works together. From creating an Avro data schema for your messages/events to comply with to how the schema registry and Avro data schemas work together. And we have also seen the code for doing all this, from the python code to send and receive Avro encoded messages based on their Avro data schemas to the rich API the IBM Event Streams on IBM Cloud schema registry provides to interact with.
However, we have said little about the need for data to evolve. When you design an Event Driven architecture for your application (by applying Event Storming or Domain Driven Design for example), it is very hard to come up with data structures/schemas that will not need to evolve/change in time. That is, your data, like your use or business cases, may need to evolve. As a result, Avro data schemas must be somehow flexible to allow your data to evolve along with your application and use cases.
But it is not as easy as adding or removing data that travels in your events/messages or modifying the type of such data. And one of the reasons for this is that Kafka (or any other type of event backbone) is many times used as the source of truth. That is, a place that you can trust as to what has happened. Hence, Kafka will serve as the event source of truth where all the events (that is, data) that happened (which could be bank transactions, communications, etc) will get stored (sometimes up to hundreds of years) and will be able to be replayed if needed. As a result, there must be a data schema management and data schema evolution put in place that allow the compatibility of old and new data schemas and, in fact, old and new data at the end of the day.
The IBM Event Streams on IBM Cloud schema registry supports enforcing compatibility rules when creating a new version of a schema. If a request is made to create a new schema version that does not conform to the required compatibility rule, then the registry will reject the request. The following rules are supported:
| Compatibility | Tested against | Descrition |
|---|---|---|
| NONE | N/A | No compatibility checking is performed when a new schema version is created |
| BACKWARD | Latest version of the schema | A new version of the schema can omit fields that are present in the existing version of the schema. A new version of the schema can add optional fields that are not present in the existing version of the schema. |
| BACKWARD_TRANSITIVE | All versions of the schema | Same as above |
| FORWARD | Latest version of the schema | A new version of the schema can add fields that are not present in the existing version of the schema. A new version of the schema can omit optional fields that are present in the existing version of the schema. |
| FORWARD_TRANSITIVE | All versions of the schema | Same as above |
| FULL | Latest version of the schema | A new version of the schema can add optional fields that are not present in the existing version of the schema. A new version of the schema can omit optional fields that are present in the existing version of the schema. |
| FULL_TRANSITIVE | All versions of the schema | Same as above |
These rules can be applied at two scopes:
- At a global scope, which is the default that
- At a per-schema level. If a per-schema level rule is defined, then this overrides the global default for the particular schema.
By default, the registry has a global compatibility rule setting of NONE. Per-schema level rules must be defined otherwise the schema will default to using the global setting.
Rules¶
In this section we are going to see how to interact with the schema registry in order to alter the compatibility rules both at the global and per-schema level.
Get the current value of a global rule¶
The current value of a global rule is retrieved by issuing a GET request to the /rules/{rule-type} endpoint, (where {rule-type} is the type of global rule to be retrieved - currently the only supported type is COMPATIBILITY). If the request is successful then the current rule configuration is returned in the payload of the response, together with a status code of 200 (OK).
Getting global rule configuration requires at least:
-
Reader role access to the Event Streams cluster resource type
-
Get the current value for the
COMPATIBILITYglobal rule withcurl -u token:$KAFKA_APIKEY $URL/rules/COMPATIBILITY
As already explained, the default out of the box global compatibility rule for IBM Event Streams on IBM Cloud schema registry is NONE.
Update a global rule¶
Global compatibility rules can be updated by issuing a PUT request to the /rules/{rule-type} endpoint, (where {rule-type} identifies the type of global rule to be updated - currently the only supported type is COMPATIBILITY), with the new rule configuration in the body of the request. If the request is successful then the newly updated rule config is returned in the payload of the response, together with a status code of 200 (OK).
Updating a global rule configuration requires at least:
-
Manager role access to the Event Streams cluster resource type
-
Update the compatibility globar rule from NONE to FORWARD with:
1. Verify it has been changed:curl -u token:$KAFKA_APIKEY –X PUT $URL/rules/COMPATIBILITY -d '{"type":"COMPATIBILITY","config":"<COMPATIBILITY_MODE>"}'
Get a per-schema rule¶
To retrieve the current value of a type of rule being applied to a specific schema, a GET request is made to the /artifacts/{schema-id}/rules/{rule-type} endpoint, (where {schema-id} is the ID of the schema, and {rule-type} is the type of global rule to be retrieved - currently the only supported type is COMPATIBILITY). If the request is successful then the current rule value is returned in the payload of the response, together with a status code of 200 (OK).
Getting per-schema rules requires at least:
- Reader role access to the Event Streams cluster resource type
-
Reader role access to the schema resource to which the rule applies
-
Get the compatibility rule for our
test-valueschema with:curl -u token:$KAFKA_APIKEY $URL/artifacts/<YOUR_SCHEMA_ID>/rules/COMPATIBILITYwhich makes sense as we have not yet created a compatibility rule for the$ curl -u token:$KAFKA_APIKEY $URL/artifacts/test-value/rules/COMPATIBILITY {"error_code":404,"message":"no compatibility rule exists for artifact 'test-value'"}test-valueschema
Create a per-schema rule¶
Rules can be applied to a specific schema, overriding any global rules which have been set, by making a POST request to the /artifacts/{schema-id}/rules endpoint, (where {schema-id} is the ID of the schema), with the type and value of the new rule contained in the body of the request, (currently the only supported type is COMPATIBILITY). If successful an empty response, and a status code of 204 (no content) is returned.
Creating per-schema rules requires at least:
- Reader role access to the Event Streams cluster resource type
-
Manager role access to the schema resource for which the rule will apply
-
Create a compatibility rule for our
test-valueschema with:curl -u token:$KAFKA_APIKEY $URL/artifacts/<YOUR_SCHEMA_ID>/rules -d '{"type":"COMPATIBILITY","config":"<COMPATIBILITY_MODE>"}' -
Make sure this compatibility rules has been created:
Update a per-schema rule¶
The rules applied to a specific schema are modified by making a PUT request to the /artifacts/{schema-id}/rules/{rule-type} endpoint, (where {schema-id} is the ID of the schema, and {rule-type} is the type of global rule to be retrieved - currently the only supported type is COMPATIBILITY). If the request is successful then the newly updated rule config is returned in the payload of the response, together with a status code of 200 (OK).
Updating a per-schema rule requires at least:
- Reader role access to the Event Streams cluster resource type
-
Manager role access to the schema resource to which the rule applies
-
Update the compatibility rule we have for our schema
test-valuewith:curl -u token:$KAFKA_APIKEY –X PUT $URL/artifacts/<YOUR_SCHEMA_ID>/rules/COMPATIBILITY -d '{"type":"COMPATIBILITY","config":"<COMPATIBILITY_MODE>"}' -
Make sure the compatibility mode for our
test-valueschema is as expected:
Delete a per-schema rule¶
The rules applied to a specific schema are deleted by making a DELETE request to the /artifacts/{schema-id}/rules/{rule-type} endpoint, (where {schema-id} is the ID of the schema, and {rule-type} is the type of global rule to be retrieved - currently the only supported type is COMPATIBILITY). If the request is successful then an empty response is returned, with a status code of 204 (no content).
Deleting a per-schema rule requires at least:
- Reader role access to the Event Streams cluster resource type
-
Manager role access to the schema resource to which the rule applies
-
Delete the compatibility rule we have for our
test-valueschema with:curl -u token:$KAFKA_APIKEY –X DELETE $URL/artifacts/<YOUR_SCHEMA_ID>/rules/COMPATIBILITY -
Make sure there is no compatibility rule for our
test-valueschema now:
Evolve your schemas¶
In this section, we are going to review the different compatibility modes for our Avro data schemas to evolve (hence our data). For simplicity though, we are going to to review only the following types of schema compatibility and at the global level:
- None
- Backward
- Forward
- Full
None¶
First of all, set the compatibility mode to backwards at the global level (for simplicity):
$ curl -u token:$KAFKA_APIKEY -X PUT $URL/rules/COMPATIBILITY -d '{"type":"COMPATIBILITY","config":"NONE"}'
{"type":"COMPATIBILITY","config":"NONE"}
This compatibility rule does not perform any compatibility check at all when a new schema version is created.
That is, if we use the test-value schema we've used through this tutorial, and try to register a completely different schema like:
{
"namespace": "ibm.eda.default",
"doc": "New Default Message's value Avro data schema, completely different than its predecesors to demonstrate None compatibility",
"type":"record",
"name":"defaultValue",
"fields":[
{
"name": "anAttribute",
"type":"int",
"doc": "an attribute that is an integer"
},
{
"name": "anotherAttribute",
"type":"long",
"doc": "Just a long number"
}
]
}
it should work:
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: test-value' \
$URL/artifacts/test-value/versions \
-d '{ "namespace": "ibm.eda.default",
"doc": "New Default Message value Avro data schema, completely different than its predecesors to demonstrate None compatibility",
"type":"record",
"name":"defaultValue",
"fields":[
{"name": "anAttribute","type":"int","doc": "an attribute that is an integer"},
{"name": "anotherAttribute","type":"long","doc": "Just a long number"}]}'
{"id":"test-value","type":"AVRO","version":3,"createdBy":"","createdOn":1589479701588,"modifiedBy":"","modifiedOn":1589551226293,"globalId":23}
As we can see, now the schema for the test topic will enforce that events coming into the topic are formed by an integer and a long number.
New Schema¶
For the following compatibility modes, we are going to use a new schema to describe a person. It will be called demo-schema and will looks like this:
{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{
"name" : "name",
"type" : "string"
},
{
"name" : "age",
"type" : "int"
},
{
"name" : "gender",
"type" : "string"
}
]
}
-
Register the schema:
$ curl -u token:$KAFKA_APIKEY \ -H 'Content-Type: application/json' \ -H 'X-Registry-ArtifactId: demo-schema' \ $URL/artifacts \ -d '{ "namespace": "schema.compatibility.test", "name": "person", "type": "record", "fields" : [ {"name" : "name", "type" : "string"}, {"name" : "age", "type" : "int"}, {"name" : "gender", "type" : "string"}]}' {"id":"demo-schema","type":"AVRO","version":1,"createdBy":"","createdOn":1589553367867,"modifiedBy":"","modifiedOn":1589553367867,"globalId":24}
Backward¶
First of all, set the compatibility mode to backwards at the global level (for simplicity):
$ curl -u token:$KAFKA_APIKEY -X PUT $URL/rules/COMPATIBILITY -d '{"type":"COMPATIBILITY","config":"BACKWARD"}'
{"type":"COMPATIBILITY","config":"BACKWARD"}
Now, What if we decide to change the data schema to add a new attribute such as place of birth? That is, the new schema would look like:
{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{
"name" : "name",
"type" : "string"
},
{
"name" : "age",
"type" : "int"
},
{
"name" : "gender",
"type" : "string"
},
{
"name" : "place_of_birth",
"type" : "string"
}
]
}
If we try to create a new version for our demo-schema to include the place_of_birth attribute with the compatibility mode set to backwards, we will get the following:
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "age", "type" : "int"},
{"name" : "gender", "type" : "string"},
{"name" : "place_of_birth","type" : "string"}]}'
{"error_code":409,"message":"Schema failed compatibility check with version ID: demo-schema, schema not backward compatible: reader's 'record' schema named 'schema.compatibility.test.person' contains a field named 'place_of_birth' that does not match any field in the corresponding writer's schema. The reader's schema does not specify a default value for this field"}
We see we get an error that says that the new schema version we are trying to register for our demo-schema is not backward compatible because "reader's 'record' schema named 'schema.compatibility.test.person' contains a field named 'place_of_birth' that does not match any field in the corresponding writer's schema. The reader's schema does not specify a default value for this field"
As the reason above explains, backward compatibility means that consumers using the new schema can read data produced with the last schema. As it stands at the moment, this is not satisfied since the consumer with the newer version expects the attribute place_of_birth.
As the error explanation above also suggests, in order to include a new attribute in our schema when we have backward compatibility mode enabled, we need to provide a default value for it so that the consumer uses it when reading messages produced with the older version of the schema that will not include the newer attribute. That is, we need our newer schema version to be like:
{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{
"name" : "name",
"type" : "string"
},
{
"name" : "age",
"type" : "int"
},
{
"name" : "gender",
"type" : "string"
},
{
"name" : "place_of_birth",
"type" : "string",
"default": "nonDefined"
}
]
}
so that the consumer will use nonDefined as the value for place_of_birth whenever it consumes messages produced with the older shcema version that do not include the attribute.
Let's check:
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "age", "type" : "int"},
{"name" : "gender", "type" : "string"},
{"name" : "place_of_birth","type" : "string","default": "nonDefined"}]}'
{"id":"demo-schema","type":"AVRO","version":2,"createdBy":"","createdOn":1589553367867,"modifiedBy":"","modifiedOn":1589556982143,"globalId":27}
Effectively, we have just evolved our Avro data demo-schema schema to include a new attribute called place_of_birth.
Now, how about if we wanted to delete an attribute in our schema? Let's try to remove the gender attribute:
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "age", "type" : "int"},
{"name" : "place_of_birth","type" : "string","default": "nonDefined"}]}'
{"id":"demo-schema","type":"AVRO","version":3,"createdBy":"","createdOn":1589553367867,"modifiedBy":"","modifiedOn":1589557152931,"globalId":28}
It worked. The resaon for this is that the consumer reading messages with the newer schema that does not contain the gender attribute, will simply ignore/drop all those attributes in the old person events/messages that are not defined in the newer data schema and just take in those that are defined. In this case, if it reads messages produced with the older data schema that come with the gender attribute, it will simply drop it.
Forward¶
First of all, set the compatibility mode to forward at the global level (for simplicity):
$ curl -u token:$KAFKA_APIKEY -X PUT $URL/rules/COMPATIBILITY -d '{"type":"COMPATIBILITY","config":"FORWARD"}'
{"type":"COMPATIBILITY","config":"FORWARD"}
Now, how about removing an attribute when the compatibility type configured is set to FORWARD? Let's try to remove the age attribute:
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "place_of_birth","type" : "string","default": "nonDefined"}]}'
{"error_code":409,"message":"Schema failed compatibility check with version ID: demo-schema, schema not forward compatible: reader's 'record' schema named 'schema.compatibility.test.person' contains a field named 'age' that does not match any field in the corresponding writer's schema. The reader's schema does not specify a default value for this field"}
As the error above explains, the problem we have when we want to remove an attribute from our Avro data schema with the compatibility mode set to forward is that the producer will be sending messages without the removed attribute (age in our case) while the consumer will be reading messages with the older Avro data schema that expects such attribute, which is what the forward compatibility required: forward compatibility means that data produced with a new schema can be read by consumers using the last schema.
What can we do to have a schema that allows the producer to send messages that do not contain an attribute that the consumer expects?
The trick here is to first register an "intermediate" data schema that adds a default value to the attibute we want to remove from the schema (age in our case). This way, the "intermediate" data schema will become the older data schema for the consumers so when we register the new schema without the attribute we wanted to remove and produce data according to it (that is, without the age attribute) afterwards, the consumers will not complain since they will have in the schema they use (the "intermediate" schema) a default value for that attribute. And they will use that default value when reading messages without the age attribute.
That is, our intermediate schema will be:
{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{
"name" : "name",
"type" : "string"
},
{
"name" : "age",
"type" : "int",
"default": 0,
},
{
"name" : "place_of_birth",
"type" : "string",
"default": "nonDefined"
}
]
}
If we try to register that new version of our demo-schema schema:
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "age", "type" : "int", "default": 0},
{"name" : "place_of_birth","type" : "string", "default": "nonDefined"}]}'
{"id":"demo-schema","type":"AVRO","version":4,"createdBy":"","createdOn":1589553367867,"modifiedBy":"","modifiedOn":1589560847136,"globalId":30}
we see we succeed since we are simply adding a default value for the newer schema. This intermediate schema, will become now the older schema at the consumer side but will still be forward compatible with the newer schema at the producer side because it now has a default value for age. Let's try now to add a new version of our demo-schema schema without the age attribute:
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "place_of_birth","type" : "string", "default": "nonDefined"}]}'
{"id":"demo-schema","type":"AVRO","version":5,"createdBy":"","createdOn":1589553367867,"modifiedBy":"","modifiedOn":1589561057270,"globalId":31}
tada! we succeeded. As we said, the older schema now at the consumer side has a default value for age so the new messages produced with the newer schema coming without the age attribute can be successfully read by the consumer using the default value.
How about adding a new attribute when the compatibility mode is set to forward? Let's try to add the attribute siblings to denote the number of borthers and sisters a person might have:
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "place_of_birth","type" : "string", "default": "nonDefined"},
{"name" : "siblings", "type" : "int"}]}'
{"id":"demo-schema","type":"AVRO","version":6,"createdBy":"","createdOn":1589553367867,"modifiedBy":"","modifiedOn":1589561302428,"globalId":32}
Contrary to what happened when addign a new attribute to an Avro data schema when the compatibility mode is set to backward, adding an attribute to an Avro data schema when the compatibility mode is set to forward is not a problem because the new attributes coming with the messages that the consumer does not expect based on the older Avro data schema it uses will simply get dropped/skipped.
Full¶
First of all, set the compatibility mode to full at the global level (for simplicity):
$ curl -u token:$KAFKA_APIKEY -X PUT $URL/rules/COMPATIBILITY -d '{"type":"COMPATIBILITY","config":"FULL"}'
{"type":"COMPATIBILITY","config":"FULL"}
Full compatibility means data schemas are both backward and forward compatible. Data schemas evolve in a fully compatible way: old data can be read with the new data schema, and new data can also be read with the last data schema.
In some data formats, such as JSON, there are no full-compatible changes. Every modification is either only forward or only backward compatible. But in other data formats, like Avro, you can define fields with default values. In that case adding or removing a field with a default value is a fully compatible change.
So let's see if we can delete the place_of_birth attribute (the only attribute in our data schema that defines a default value):
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "siblings", "type" : "int"}]}'
{"id":"demo-schema","type":"AVRO","version":7,"createdBy":"","createdOn":1589553367867,"modifiedBy":"","modifiedOn":1589562453126,"globalId":33}
It seems it works. But how about removing an attribute that does not have a default value? Well, we need to do the trick of the "intermediate" schema again where we first add a default for that attribute and register the schema to later register a newer schema where we remove that attibute.
Let's see adding a new attribute called height (remember we need to add a default value for it because of the full compatibility mode):
$ curl -u token:$KAFKA_APIKEY \
-H 'Content-Type: application/json' \
-H 'X-Registry-ArtifactId: demo-schema' \
$URL/artifacts/demo-schema/versions \
-d '{
"namespace": "schema.compatibility.test",
"name": "person",
"type": "record",
"fields" : [
{"name" : "name", "type" : "string"},
{"name" : "siblings", "type" : "int"},
{"name" : "height", "type" : "int", "default": 0}]}'
{"id":"demo-schema","type":"AVRO","version":8,"createdBy":"","createdOn":1589553367867,"modifiedBy":"","modifiedOn":1589562591316,"globalId":34}
We see it also works. Now we know how a data schema can evolve when full compatibility is required.
As a final exercise, check how many times we have evolve our demo-schema schema for the compatibility rules:
Security¶
As we have already mentioned during the this tutorial, we need to pay attention to the permissions we give to users, groups, applications (and thefore the clients they used to interact with IBM Event Streams on IBM Cloud), etc since we dont want everyone and everything to be, for instance, creating or deleting schemas or updating the compatibility modes for schema evolution.
As a result, the IBM Event Streams on IBM Cloud schema registry introduces a new IAM resource type: schema. This can be used as part of a CRN to identify a particular schema. For example:
-
A CRN that names a specific schema (test-schema), for a particular instance of an Event Streams service:
crn:v1:bluemix:public:messagehub:us-south:a/6db1b0d0b5c54ee5c201552547febcd8:91191e31-5642-4f2d-936f-647332dce3ae:schema:test-schema -
A CRN that describes all of the schemas for a particular instance of the Event Streams service:
crn:v1:bluemix:public:messagehub:us-south:a/6db1b0d0b5c54ee5c201552547febcd8:91191e31-5642-4f2d-936f-647332dce3ae:schema: -
While not directly related to the addition of the schema resource type, it is also worth noting that it is possible to apply policies to a CRN describing a particular Event Streams instance. For example, policies granted at the scope of this CRN would affect all resources (topics, schemas, etc.) belonging to the cluster:
crn:v1:bluemix:public:messagehub:us-south:a/6db1b0d0b5c54ee5c201552547febcd8:91191e31-5642-4f2d-936f-647332dce3ae::
With the addition of the new schema IAM resource type it is possible to create policies that control access using varying degrees of granularity, for example:
- a specific schema
- a set of schemas selected via a wildcard expression
- all of the schemas stored by an instance of IBM Event Streams
- all of the schemas stored by all of the instances of IBM Event Streams in an account
Please, review the security documentation you can find here in order to understand how to create the policies for assigning specific permissions at the differentt levels of a cloud resource (that is, at the level of any Event Streams, a specific Event Streams instance but all topics, etc).
Schema security role mapping¶
| Action | Event Streams cluster resource | Schema resource |
|---|---|---|
| Create schema | Read | Write |
| List schemas | Read | Read |
| Delete schema | Read | Manager |
| Create schema version | Read | Write |
| Get latest schema version | Read | Read |
| Get specific schema version | Read | Read |
| List all schema versions | Read | Read |
| Delete a schema version | Read | Manager |
Compatibilitty rules security role mapping¶
| Action | Event Streams cluster resource | Schema resource |
|---|---|---|
| Update global rule | Manager | - |
| Get global rule | Read | - |
| Create per schema rule | Read | Manager |
| Get per schema rule | Read | Read |
| Update per schema rule | Read | Manager |
| Delete per schema rule | Read | Manager |