Monitoring ES
Overview¶
Deploying IBM Event Streams on OpenShift Cloud Platform (OCP) as the Apache Kafka-based event backbone is a great first step in your Event-Driven Architecture implementation. However, now you must maintain that Kafka cluster and understand the intricate details of what a "healthy" cluster looks like. This tutorial will walk you through some of the initial monitoring scenarios that are available for IBM Event Streams deployed on OCP.
The raw monitoring use cases and capabilities are available from the official IBM Event Streams documentation via the links below: - Monitoring deployment health - Monitoring Kafka cluster health - Monitoring topic health - Monitoring Kafka consumer group lag
This tutorial will focus on a more guided approach to understanding the foundation of Apache Kafka monitoring capabilities provided by IBM Event Streams and the IBM Cloud Pak for Integration. Upon completion of this tutorial, you can extend your own experience through the Advanced Scenarios section to adapt Kafka monitoring capabilites to your project's needs.
Scenario Prereqs¶
OpenShift Container Platform
- This deployment scenario was developed for use on the OpenShift Container Platform, with a minimum version of
4.4.
Cloud Pak for Integration
- This deployment scenario was developed for use with the 2020.2.x release of the IBM Cloud Pak for Integration, installed on OpenShift 4.4.
IBM Event Streams
- This deployment scenario requires a working installation of IBM Event Streams V10.0 or greater, deployed on the Cloud Pak for Integration environment mentioned above.
- For Cloud Pak installation guidance, you can follow the Cloud Pak Playbook installation instructions.
Git
- We will need to clone repositories.
Java
- Java Development Kit (JDK) v1.8+ (Java 8+)
Maven
- The scenario uses Maven v3.6.x
Generate Event Load¶
See now separate note on Starter application
Explore the preconfigured Event Streams Dashboard¶
This section will walk through the default dashboard and user interface available on every IBM Event Streams deployment.
-
Log into the Event Streams Dashboard.
-
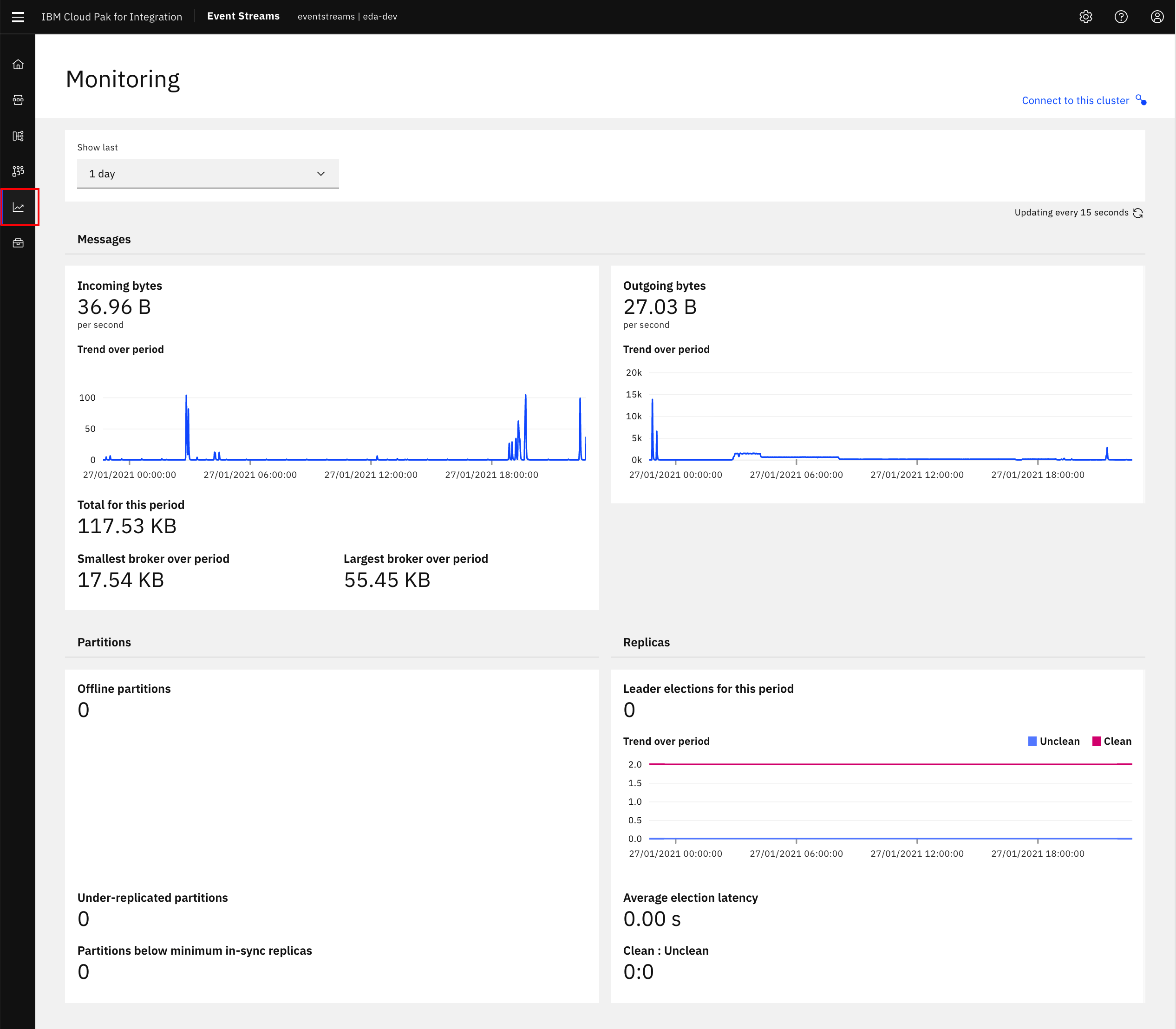
Click the Monitoring tab from the primary navigation menu on the left hand side.
-
From here, you can view information on messages, partitions, and replicas for the past hour, day, week, or month.
-
Click the Topics tab from the primary navigation menu on the left hand side.
-
Click the name of your topic that you previously created in the Generate Event Load section. This should be in the format of
monitoring-lab-topic-[your-initials]. -
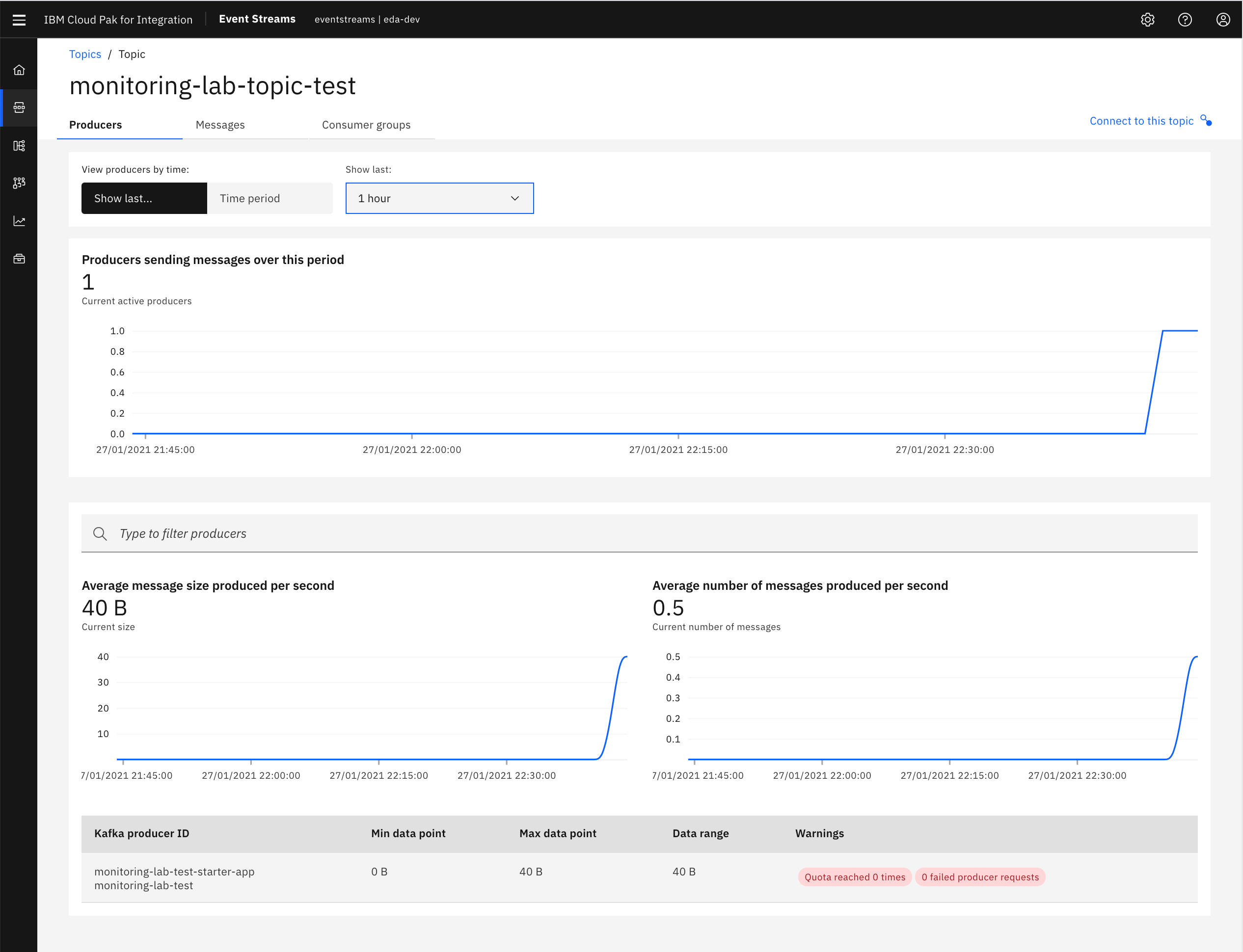
You are presented with a Producers page showing the number of active producers, as well as the average message size produced per second and average number of messages produced per second. You can modify the time window by changing the values in the View producers by time box.
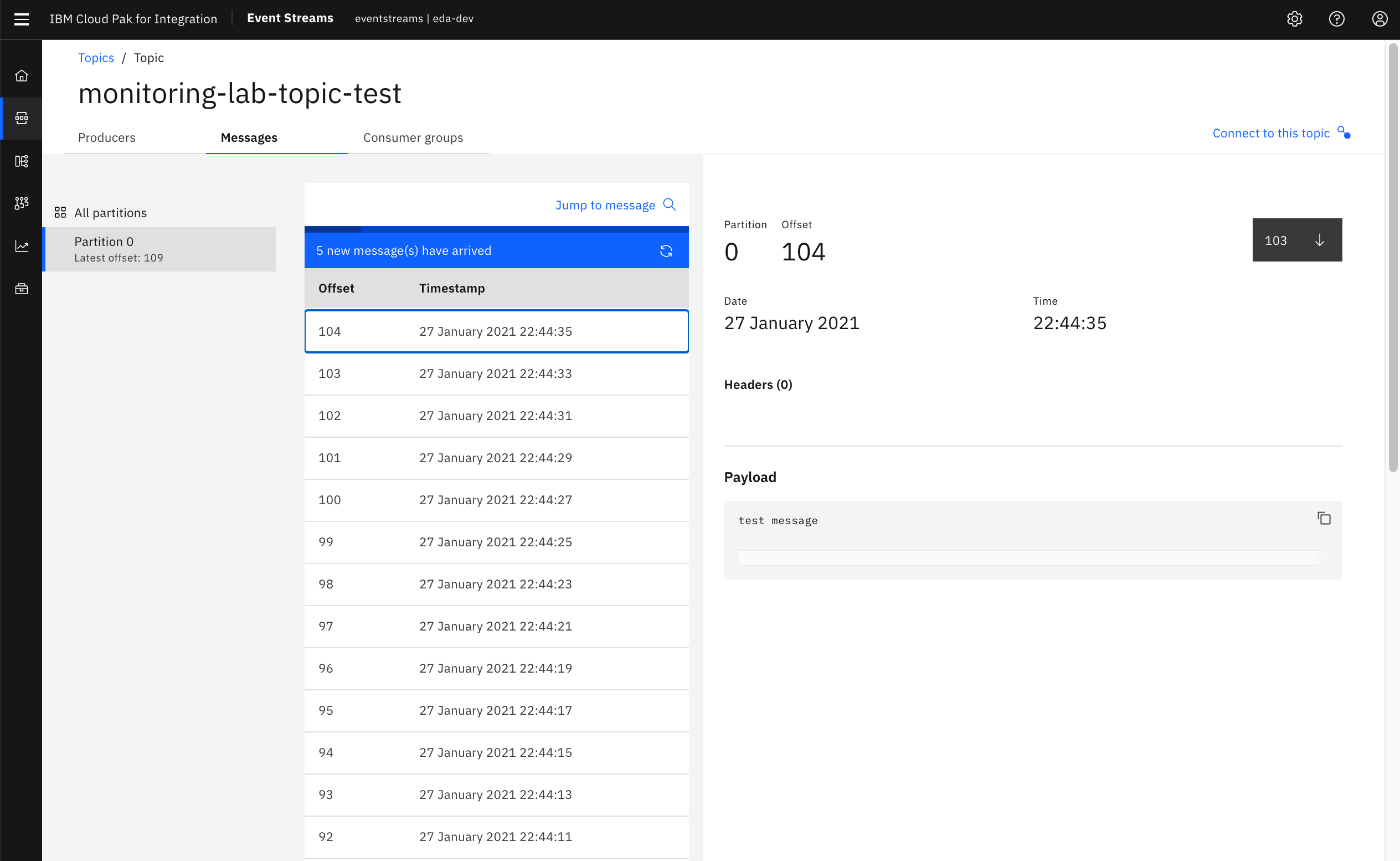
- Click the Messages tab to view all the data and metadata for events stored in the topic. You can view messages across partitions or on specific partitions, as well as jump to specific offsets or timestamps.
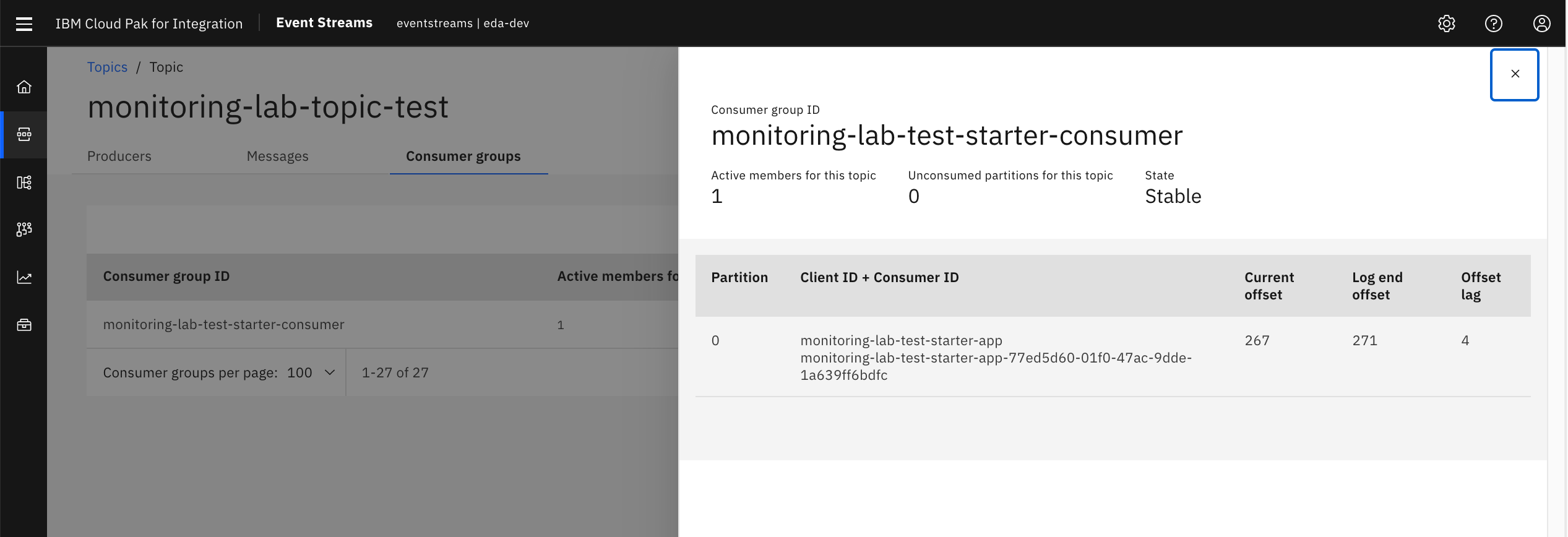
- Click Consumer Groups to be shown the number of consumer groups that have previously registered or are currently registered as consuming from the topic.
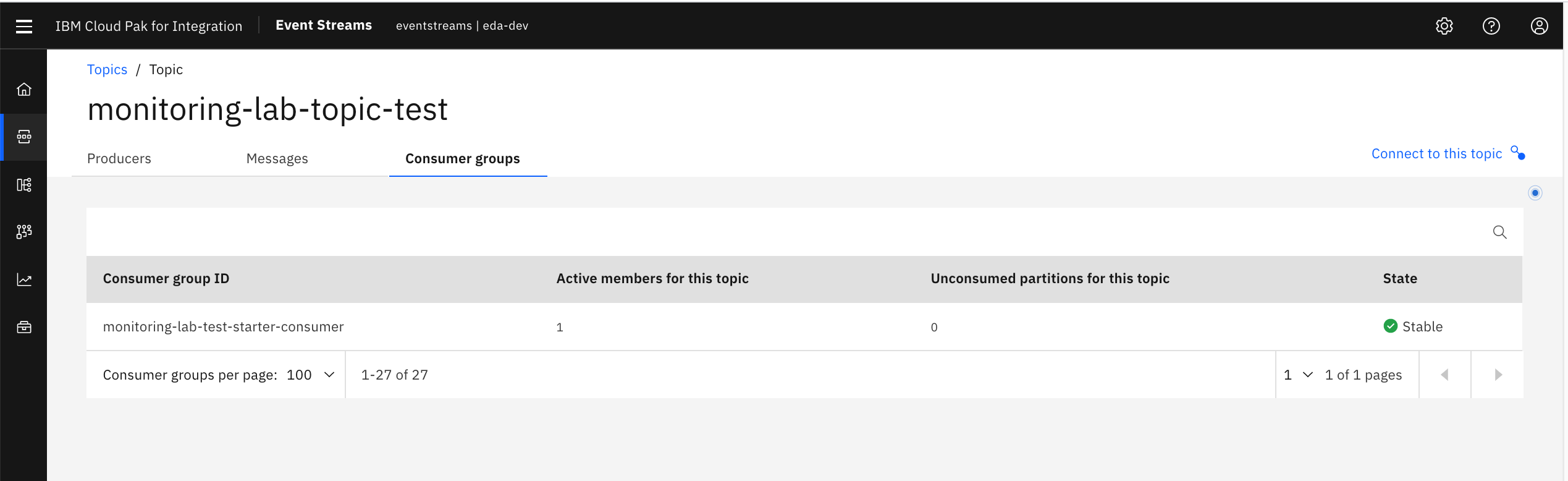
- You are able to see how many active members a consumer group has, as well as have many unconsumed partitions a topic has inside of a consumer group (also known as consumer group lag)- a key metric for driving parallelism in event-driven microservices!
Import Grafana Dashboards¶
This section will walk through the Grafana Dashboard capabilities documented in the official IBM Event Streams documentation.
- Apply the Grafana Dashboard for overall Kafka Health via a
MonitoringDashboardcustom resource:
oc apply -f https://raw.githubusercontent.com/ibm-messaging/event-streams-operator-resources/master/grafana-dashboards/ibm-eventstreams-kafka-health-dashboard.yaml
View Grafana Dashboards¶
To view the newly imported Event Streams Grafana dashboard for overall Kafka Health, follow these steps:
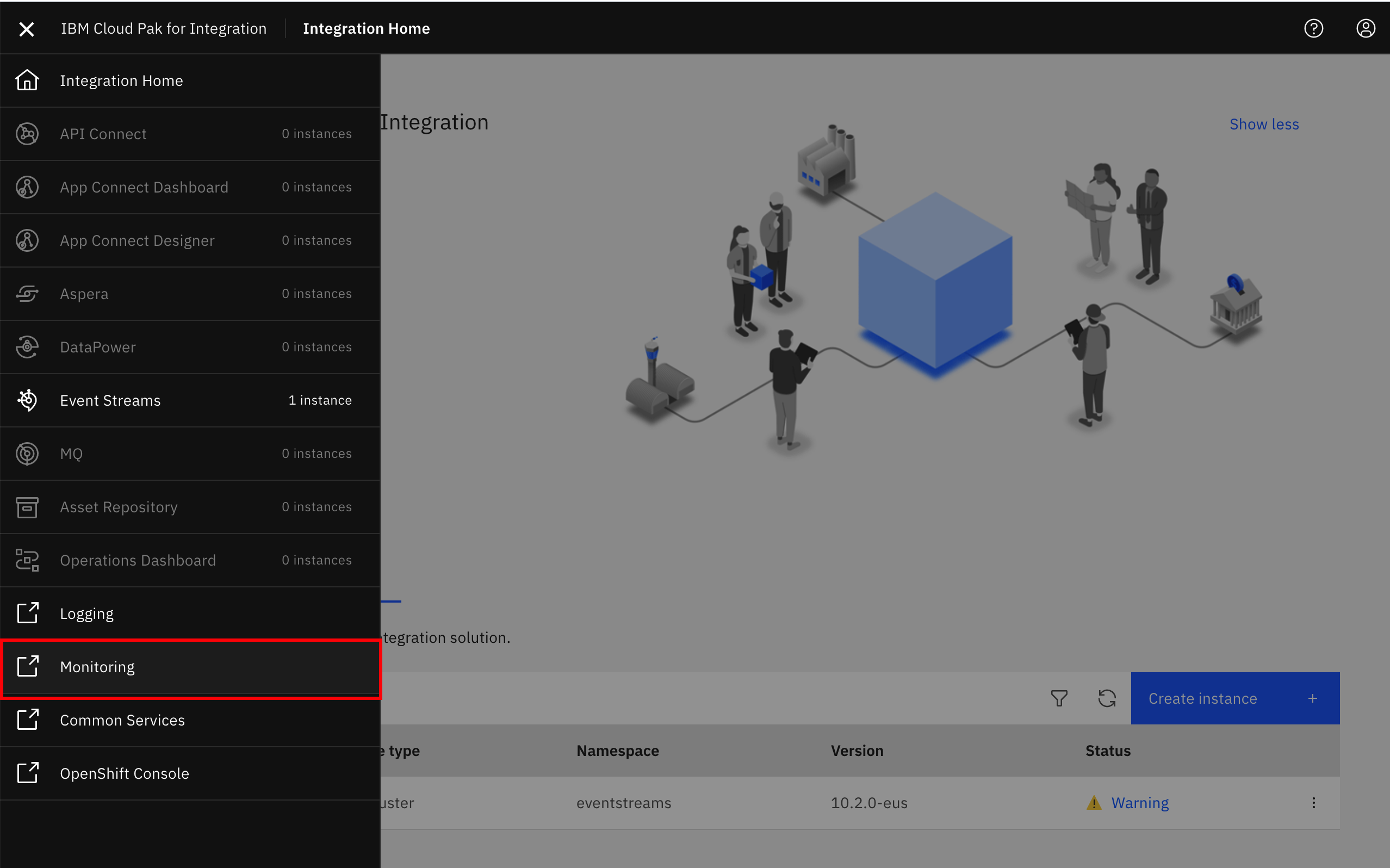
- Navigate to the IBM Cloud Platform Common Services console homepage via
https://cp-console.[cluster-name], click the hamburger icon in the top left and click the Monitoring in the expanded menu to open the Grafana homepage.
- Click the user icon in the bottom left corner to open the user profile page.
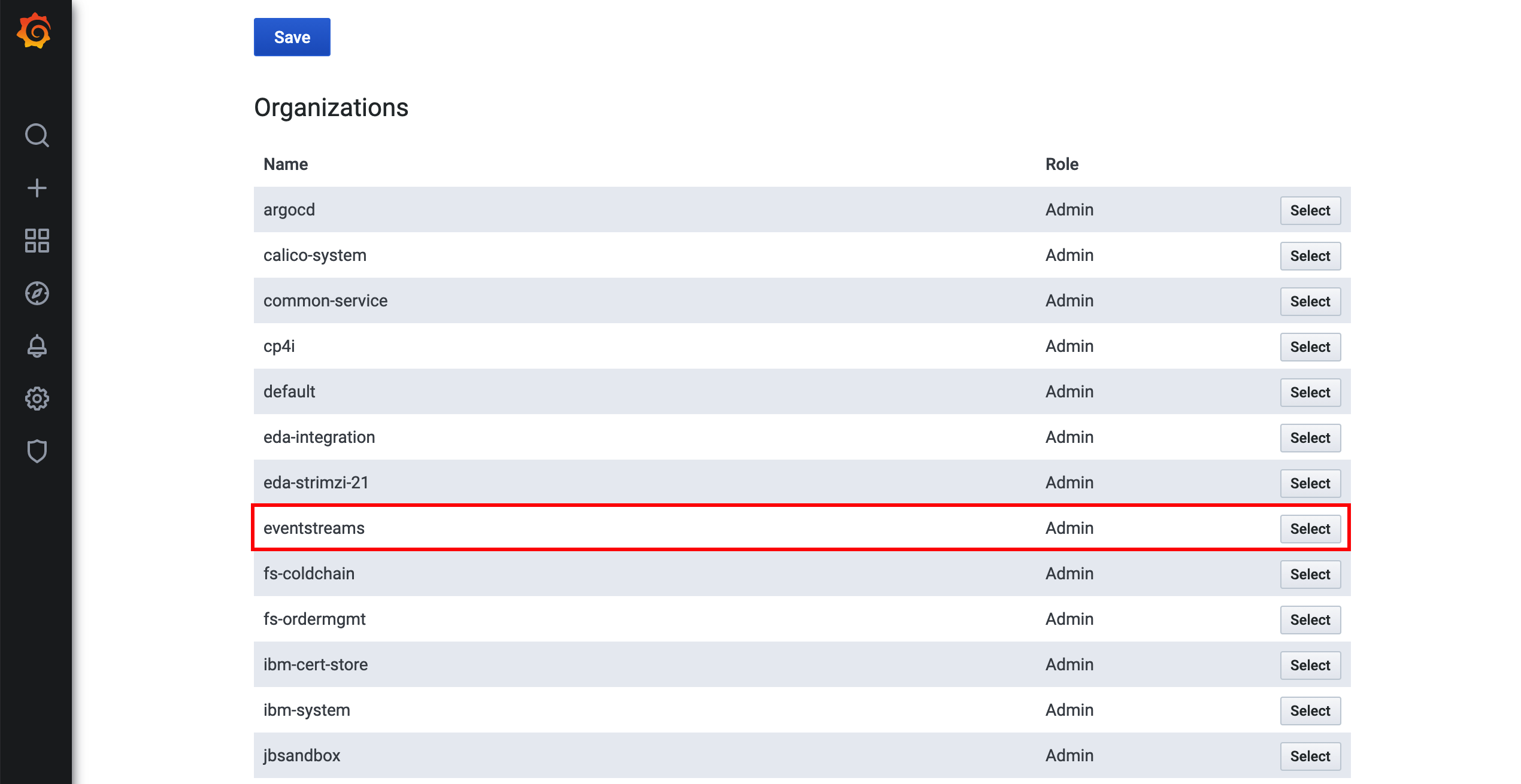
- In the Organizations table, find the namespace where you installed the Event Streams
monitoringdashboardcustom resource (most likely theeventstreams), and switch the user profile to that namespace.
-
Hover over the Dashboards square on the left and click Manage.
-
Click on IBM Event Streams Kafka dashboard in the Dashboard table to view the newly imported resource.
- Using the drop-down selectors at the top, select the following:
- Namespace which has the running instance of your Event Streams deployment,
- Cluster Name for the desired Event Streams cluster
- Topic that matches desired topics for viewing (only topics that have been published to will appear in this list)
- Broker to select individual or multiple brokers in the cluster.
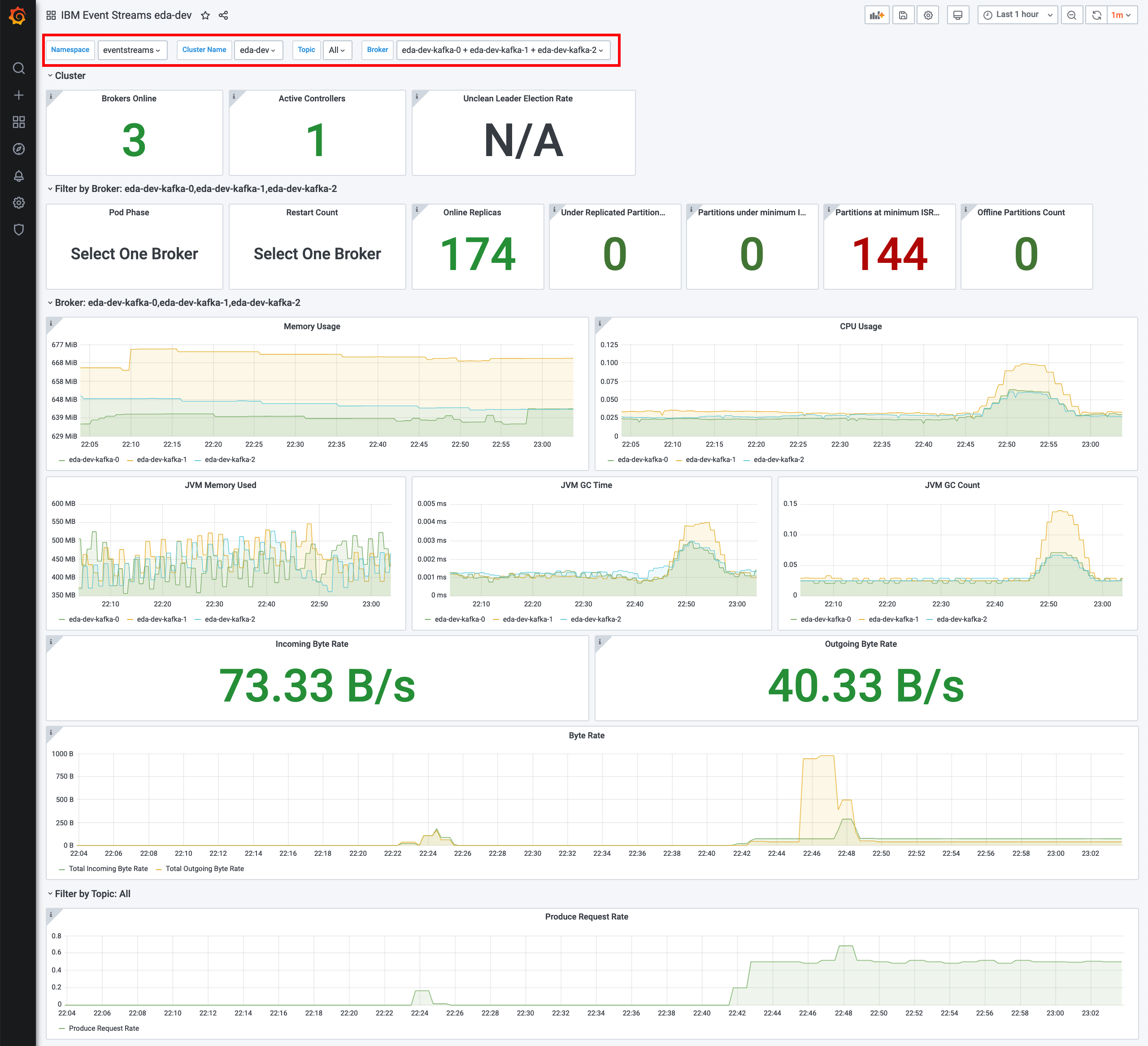
Note: Not all of the metrics that Kafka uses are published to Prometheus by default. The metrics that are published are controlled by a ConfigMap. You can publish metrics by adding them to the ConfigMap.
Create an Alert¶
A monitoring system is only as good as the alerts it can send out, since you're not going to be watching that Grafana dashboard all day and night! This section will walk through the creation of a quick alert rule which will automatically trigger, as well as how to view and silence that alert in the provided Alertmanager interface.
The official Event Streams documentation provides a walkthrough of selecting the desired metrics to monitor, but for our example, we will leverage the kafka_server_replicamanager_partitioncount_value metric as an indicator of topic creation (as the overall partition count will increase when a topic is first created).
- On the command line, create this sample rule which will fire whenever the partition count is over 50 (which is the baseline number of partitions the Event Streams system uses for its internal topic partitions). In order to do this, create
prom-rule-partitions.yamlfile with the following content in it:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
component: icp-prometheus
name: demo-partition-count
spec:
groups:
- name: PartitionCount
rules:
- alert: PartitionCount
expr: kafka_server_replicamanager_partitioncount_value > 50
for: 10s
labels:
severity: critical
annotations:
identifier: 'Partition count'
description: 'There are {{ $value }} partition(s) reported by broker {{ $labels.kafka }}'
- Create the alert rule via the OpenShift CLI:
- You can view the creation and status of your alert via the OpenShift CLI:
https://cp-console.[cluster-name]/prometheus. 
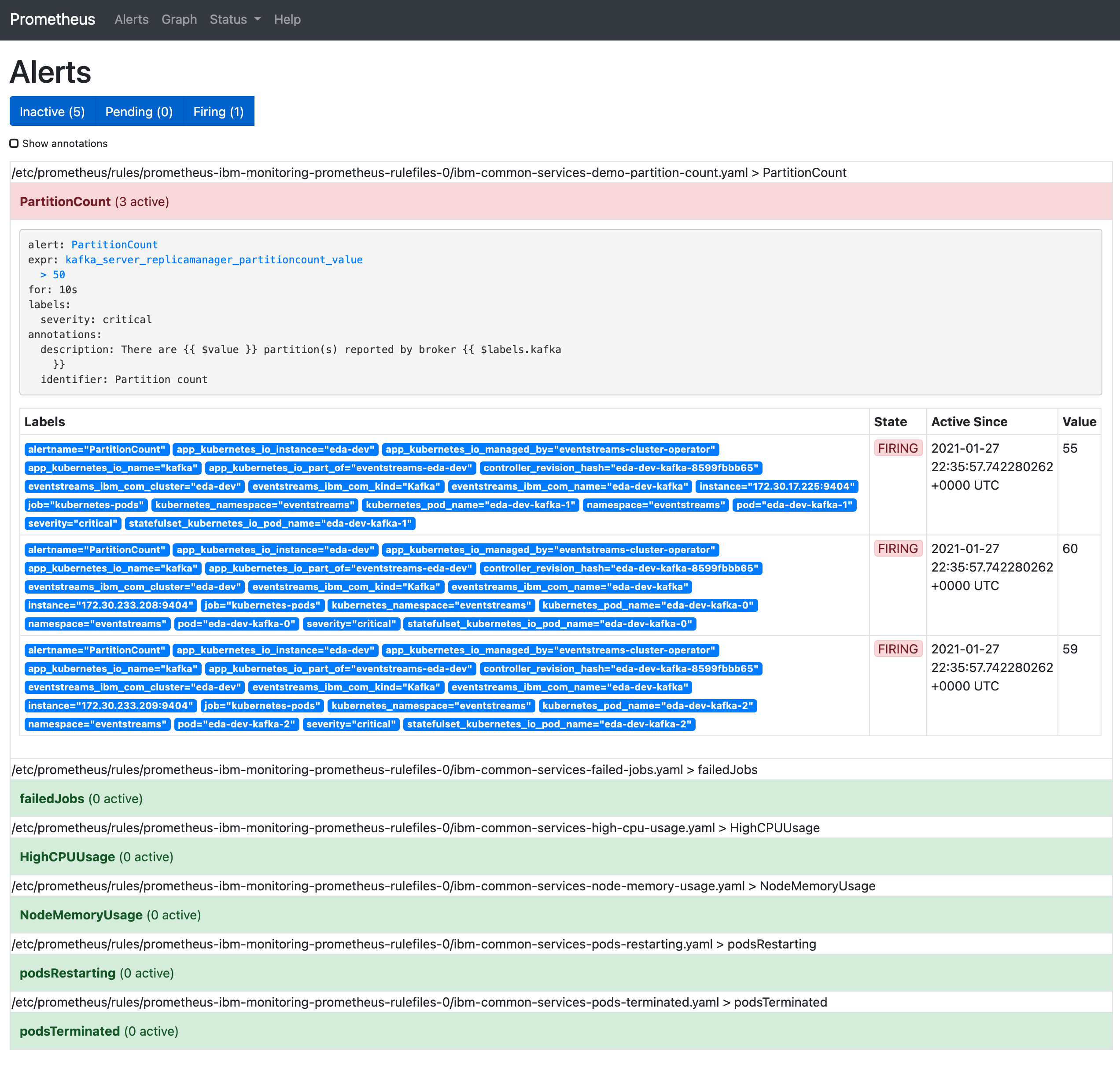
- Click the Alerts button in the header.
- You should see your new PartitionCount rule firing and highlighted in red.
- NOTE: If you do not see your PrometheusRule, you may need to create it in the
ibm-common-servicesnamespace depending upon your OpenShift cluster and Cloud Pak operator configuration. This can be done by supplying the-n ibm-common-servicesflag to theoc apply -f prom-rule-partitions.yamlcommand. - Click on the PartitionCount alert to expand the details and see which components are triggering the alert.
Now that we have created alerts from the monitoring system, you will want a way to manage those alerts. The default Alertmanager component provides a way to manage firing alerts, notifications, and silences. Prometheus is capable of integrating with many notification systems - from Slack to PagerDuty to HipChat to common HTTP webhooks. For further information on the extensibility of Prometheus, you can view the Alerting configuration section of the official docs. For configuring the IBM Cloud Pak Common Services deployed instance of Prometheus, you can view the Configuring Alertmanager section of the official docs.
In this section of the tutorial, you will walk through the Alertmanager interface and silence the previously created alerts.
- Access the default Alertmanager instance via
https://cp-console.apps.[cluster-name]/alertmanager/. - You should see the newly created
PartitionCountalerts listed as firing.
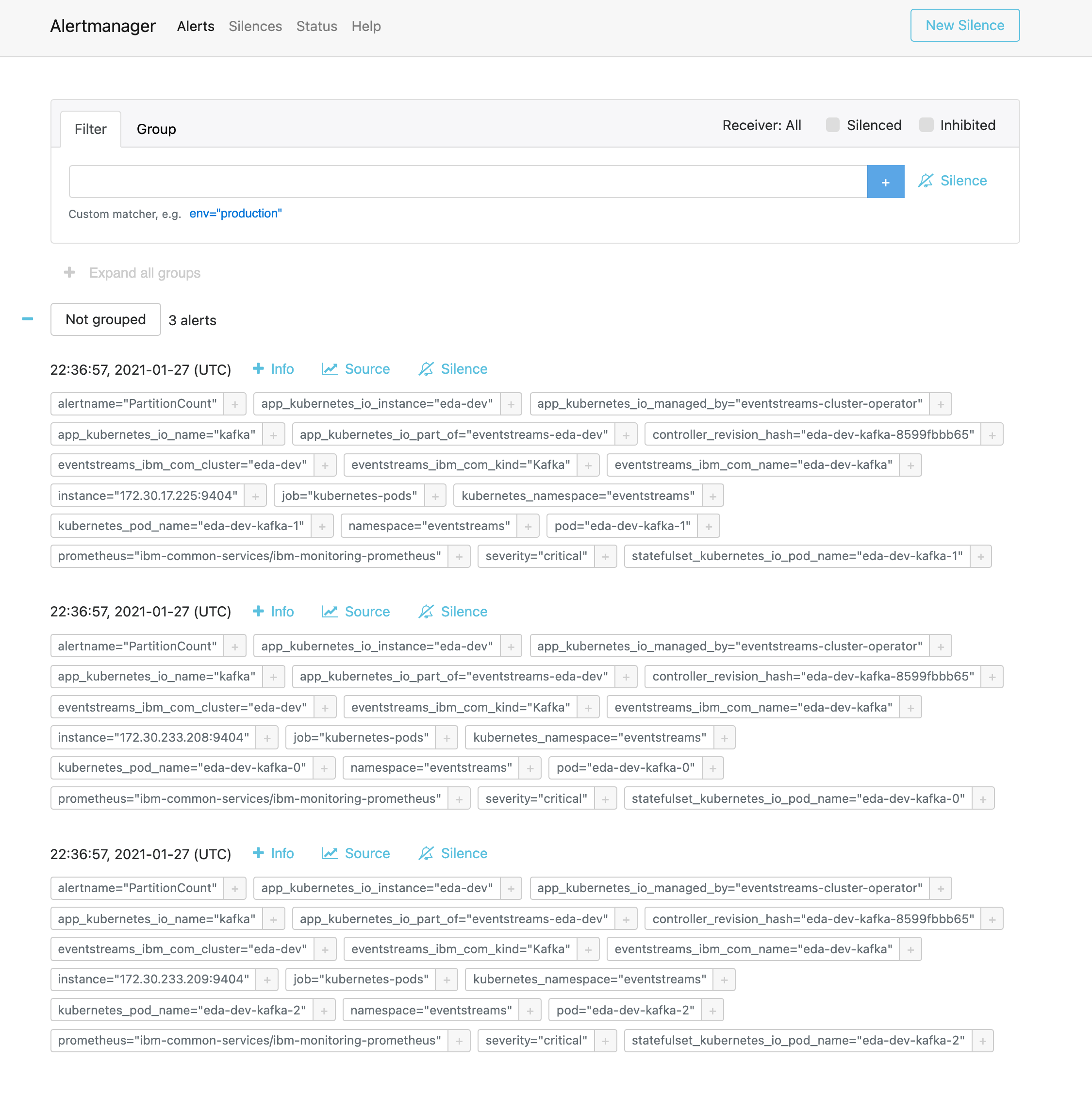
- Click on the Info button for the first alert to see the additional context provided by the alert definition (ie there are more than 50 partitions)
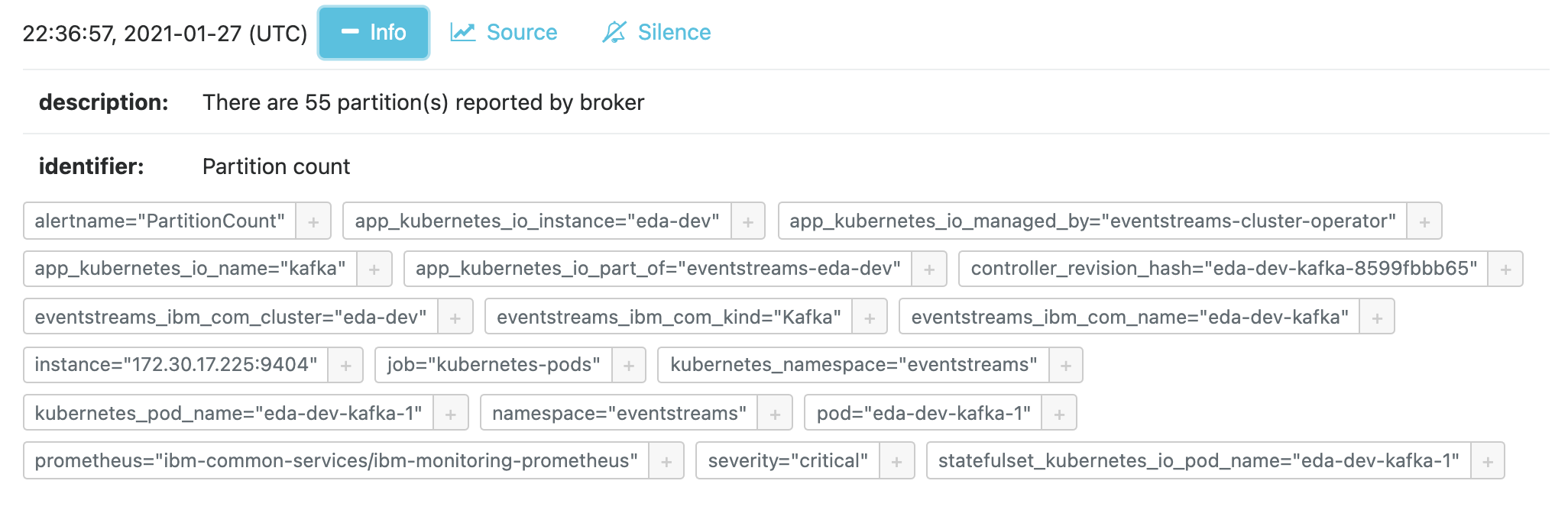
-
As alerts fire and become acknowledged, you can silence them to mark them as known, acknowledged, or resolved. To do this, you create a Silence. Click the Silence button for one of the alerts in the list.
-
You will see a start time, a duration, and an end time by default. This gives you initial control over what you are silencing and for how long.
-
Next, you will see a list of Name and Value pairs that are filled with the information from the alert instance you clicked on.
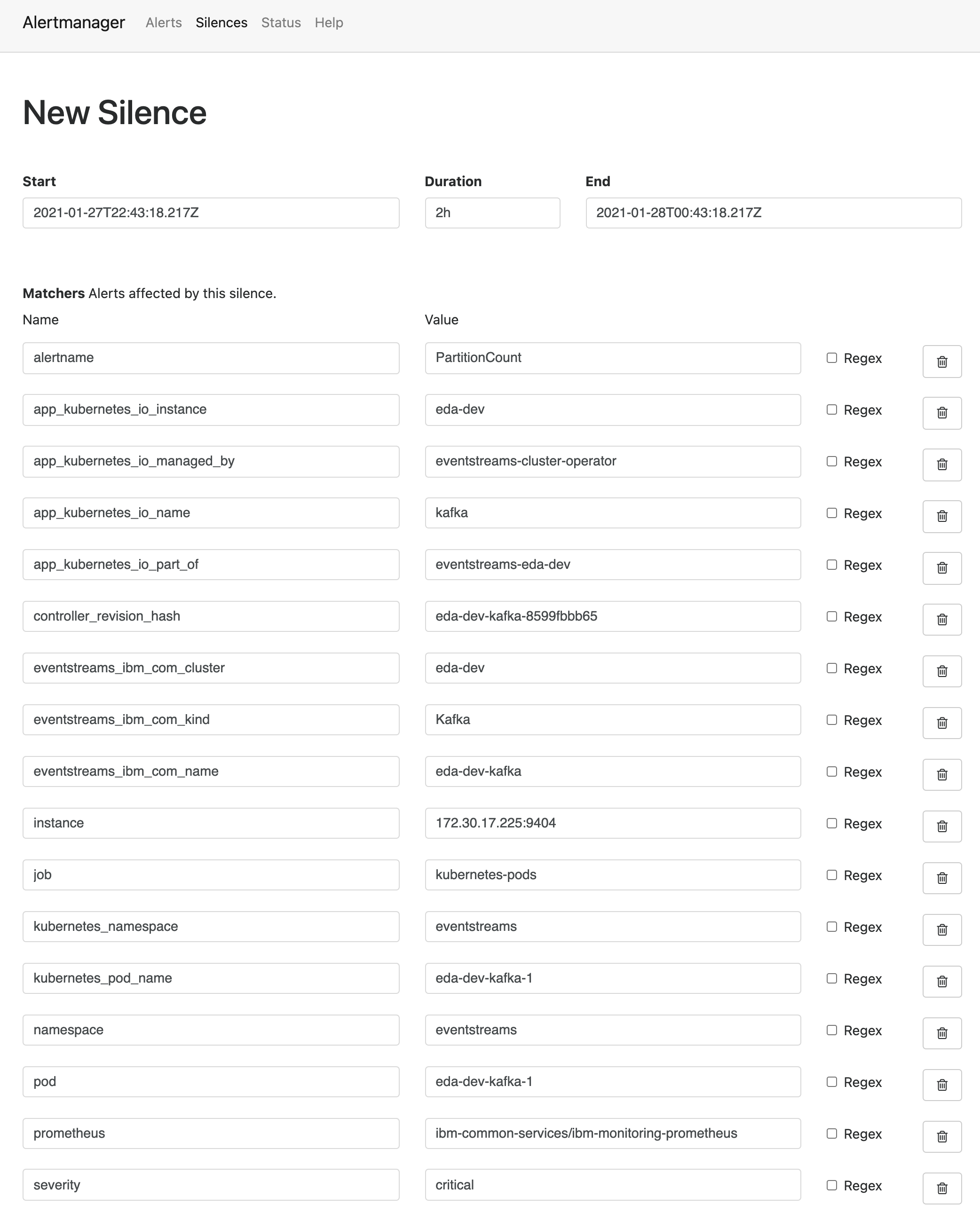
- Delete the elements in the Matchers list until only the following items are left. This will allow for a robust capture of all the PartitionCount alerts for the same Event Streams cluster.
alertnameapp_kubernetes_io_instanceapp_kubernetes_io_part_of-
kubernetes_namespace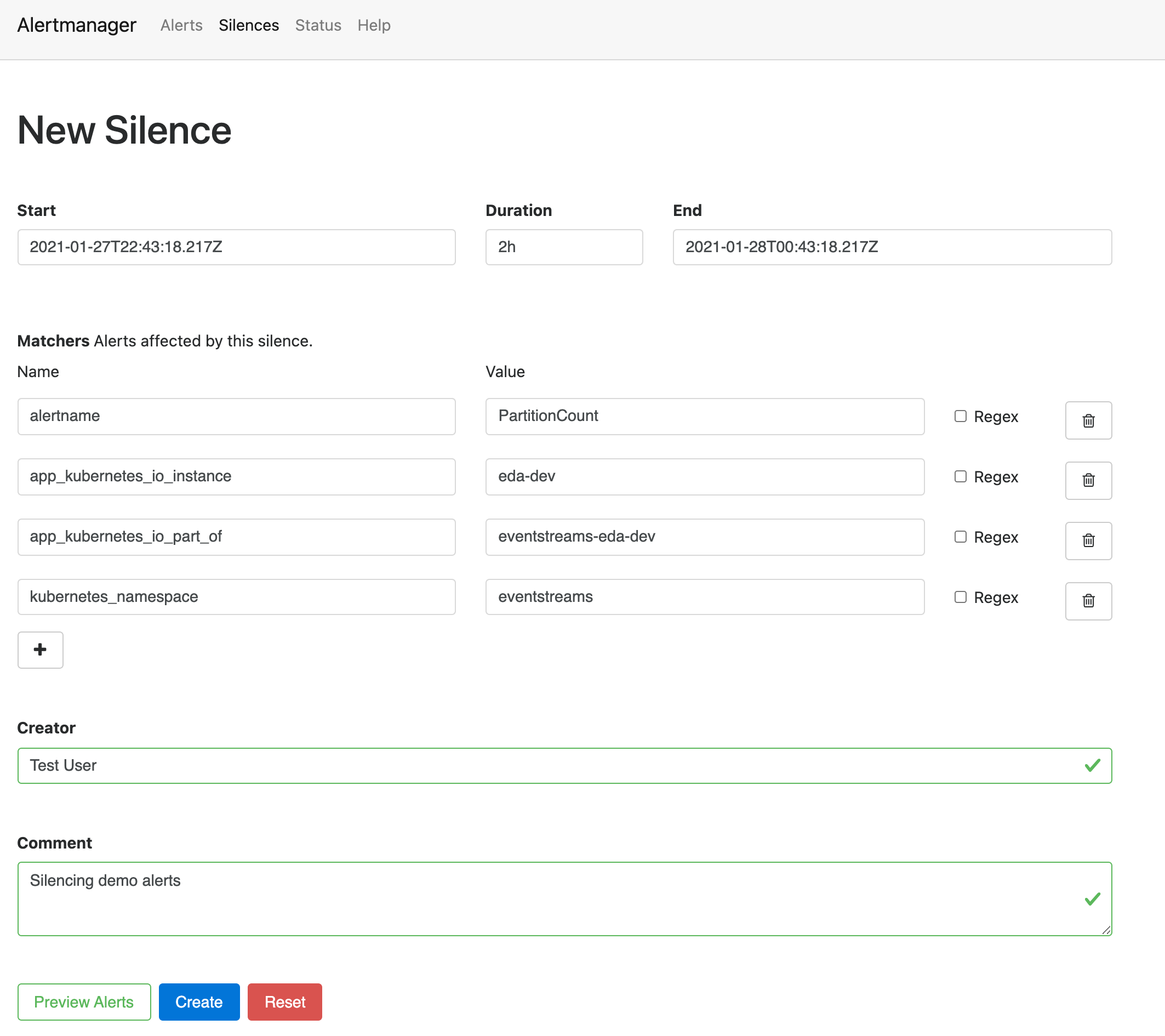
-
Your username should already be filled in for the Creator, so enter a Comment of "Silencing demo alerts" and click Preview Alerts.
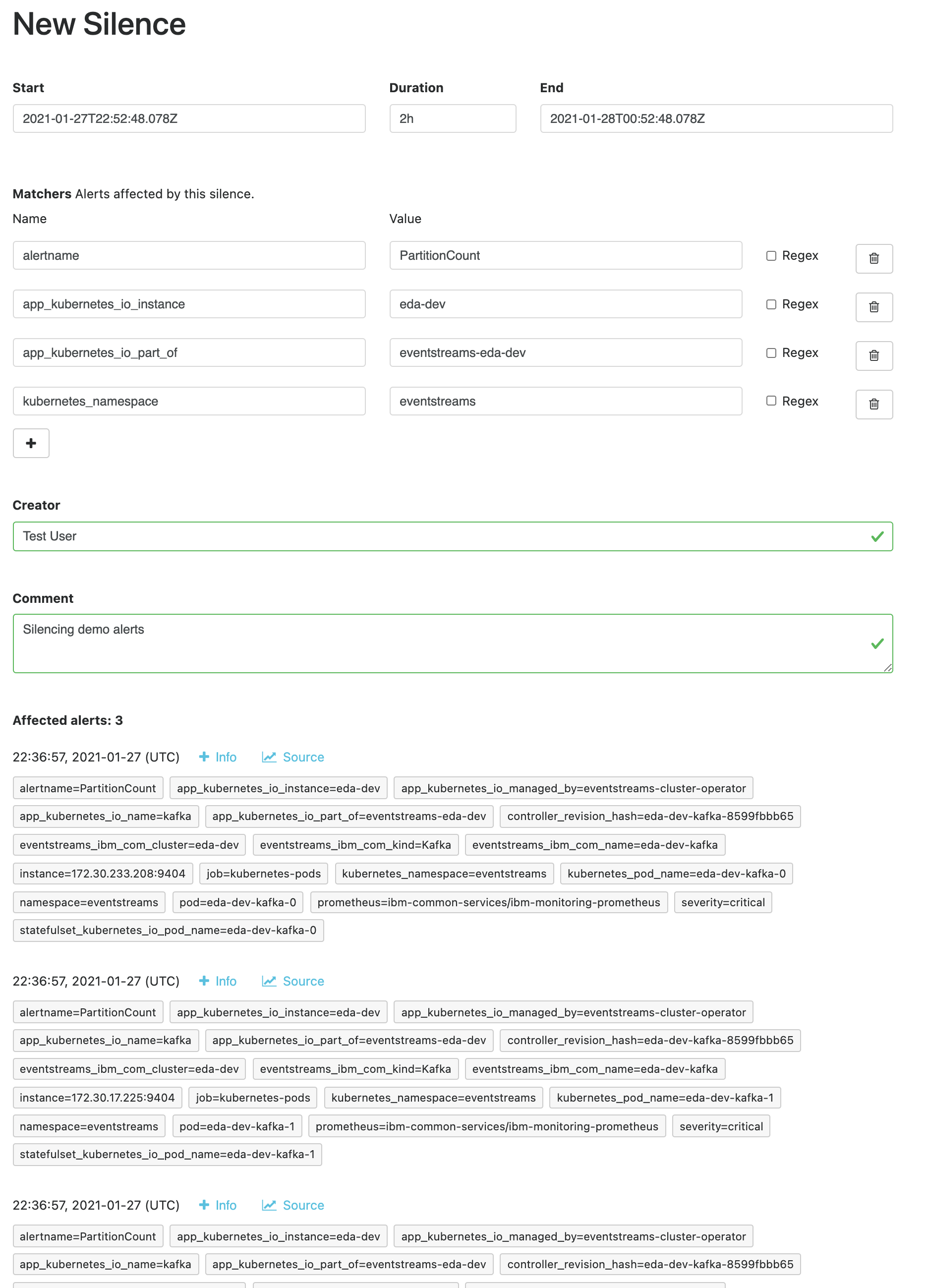
-
Once the affected number of alerts matches the same number of PartitionCount alerts that were listed as firing in Prometheus, click Create.
-
Clicking on the Alerts tab in the header, you will now see those alerts are silenced - meaning you acknowledged them.
- To make them visible again prior to the expiration of the created Silence, click on the Silences tab from the header. This page lists all the Active, Pending, and Expired silences in the system. You can view, edit, and expire any active Silence to again have the alerts show up in Alertmanager or anywhere else Prometheus is sending notifications.
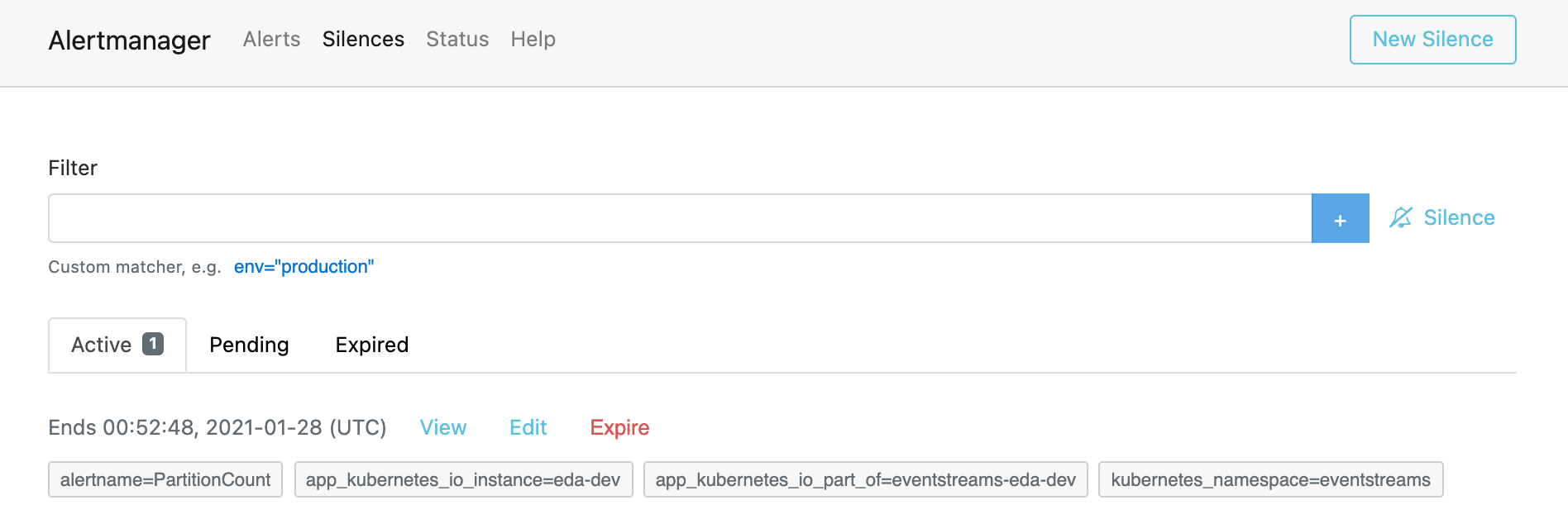
Next Steps¶
External Monitoring Tools¶
IBM Event Streams supports additional monitoring capabilities with third-party monitoring tools via a connection to the clusters JMX port on the Kafka brokers.
You must first configure your IBM Event Streams instance for specific access by these external monitoring tools.
You can then follow along with the tutorials defined in the official IBM Event Streams documentation to monitor Event Streams with tools such as Datadog and Splunk.
Advanced Scenarios¶
As shown in this tutorial, IBM Event Streams provides a robust default set of monitoring metrics which are available to use right out of the box. However, you will most likely need to define custom metrics or extend existing metrics for use in custom dashboards or reporting processes. The following links (in order of recommended usage) discuss additional monitoring capabilities, technologies, and endpoints that are supported with IBM Event Streams to extend your custom monitoring solution as needed:
-
Kafka Exporter - You can use Event Streams to export metrics to Prometheus. These metrics are otherwise only accessible through the Kafka command line tools and allow per-topic metrics, such as consumer group lag, to be colleced.
-
JMX Exporter - You can use Event Streams to collect JMX metrics from Kafka brokers, ZooKeeper nodes, and Kafka Connect nodes, and export them to Prometheus via the Prometheus JMX Exporter.
-
JmxTrans - JmxTrans can be used to push JMX metrics from Kafka brokers to external applications or databases.
Additional Reading¶
- Monitoring Kafka via official Apache Kafka documentation
- Monitoring Kafka performance metrics via Datadog
- How to Monitor Kafka via Server Density
- OpenShift Day 2 Monitoring via IBM Cloud Paks Playbook
- Monitoring Kafka cluster health via IBM Event Streams documentation
- Configuring the monitoring stack via Red Hat OpenShift documentation
- Examining cluster metrics via Red Hat OpenShift documentation