Kafka Producers
Understanding Kafka Producers¶
A producer is a thread safe kafka client API that publishes records to the cluster. It uses buffers, thread pool, and serializers to send data. They are stateless: the consumers is responsible to manage the offsets of the message they read. When the producer connects via the initial bootstrap connection, it gets the metadata about the topic - partition and the leader broker to connect to. The assignment of messages to partition is done following different algorithms: round-robin if there is no key specified, using the hash code of the key, or custom defined.
We recommend reading IBM Event streams producer guidelines to understand how producers work with its configuration parameters.
Design considerations¶
When developing a record producer you need to assess the followings:
- What is the event payload to send? Is is a root aggregate, as defined in domain driven design, with value objects? Does it need to be kept in sequence to be used as event sourcing? or order does not matter? Remember that when order is important, messages need to go to the same topic. When multiple partitions are used, the messages with the same key will go to the same partition to guaranty the order. See related discussions from Martin Kleppmann on confluent web site. Also to be exhaustive, it is possible to get a producer doing retries that could generate duplicate records as acknowledges may take time to come: within a batch of n records, if the producer did not get all the n acknowledges on time, it may resend the batch. This is where 'idempotence' becomes important (see later section).
- Is there a strong requirement to manage the schema definition? If using one topic to manage all events about a business entity, then be sure to support a flexible avro schema.
- What is the expected throughput to send events? Event size * average throughput combined with the expected latency help to compute buffer size. By default, the buffer size is set at 32Mb, but can be configured with
buffer.memoryproperty. (See producer configuration API) - Can the producer batches events together to send them in batch over one send operation? By design kafka producers batch events.
- Is there a risk for loosing communication? Tune the RETRIES_CONFIG and buffer size, and ensure to have at least 3 or even better 5, brokers within the cluster to maintain quorum in case of one failure. The client API is implemented to support reconnection.
-
When deploying kafka on Kubernetes, it is important to proxy the broker URLs with a proxy server outside of kubernetes. The HAProxy needs to scale, and as the kafka traffic may be important, it may make sense to have a dedicated HAProxy for clients to brokers traffic.
-
Assess exactly once delivery requirement. Look at idempotent producer: retries will not introduce duplicate records (see section below).
- Partitions help to scale the consumer processing of messages, but it also helps the producer to be more efficient as it can send message in parallel to different partition.
- Where the event timestamp comes from? Should the producer send operation set it or is it loaded from external data? Remember that
LogAppendTimeis considered to be processing time, andCreateTimeis considered to be event time.
Typical producer code structure¶
The producer code, using java or python API, does the following steps:
- define producer properties
- create a producer instance
- Connect to the bootstrap URL, get a broker leader
- send event records and get resulting metadata.
Producers are thread safe. The send() operation is asynchronous and returns immediately once record has been stored in the buffer of records, and it is possible to add a callback to process the broker acknowledgements.
Here is an example of producer code from the quick start.
Kafka useful Producer APIs¶
Here is a list of common API to use in your producer and consumer code.
- KafkaProducer A Kafka client that publishes records to the Kafka cluster. The send method is asynchronous. A producer is thread safe so we can have per topic to interface.
- ProducerRecord to be published to a topic
- RecordMetadata metadata for a record that has been acknowledged by the server.
Properties to consider¶
The following properties are helpful to tune at each topic and producer and will vary depending on the requirements:
| Properties | Description |
|---|---|
| BOOTSTRAP_SERVERS_CONFIG | A comma-separated list of host:port values for all the brokers deployed. So producer may use any brokers |
| KEY_SERIALIZER_CLASS_CONFIG and VALUE_SERIALIZER_CLASS_CONFIG | convert the keys and values into byte arrays. Using default String serializer should be a good solution for Json payload. For streaming app, use customer serializer. |
| ACKS_CONFIG | specifies the minimum number of acknowledgments from a broker that the producer will wait for before considering a record send completed. Values = all, 0, and 1. 0 is for fire and forget. |
| RETRIES_CONFIG | specifies the number of times to attempt to resend a batch of events. |
| ENABLE_IDEMPOTENCE_CONFIG | Set to true, the number of retries will be maximized, and the acks will be set to All. |
| TRANSACTION_ID | A unique identifier for a producer. In case of multiple producer instances, a same ID will mean a second producers can commit the transaction. Epoch number, linked to the process ID, avoid having two producers doing this commit. If no transaction ID is specified, the transaction will be valid within a single session. |
Advanced producer guidances¶
How to support exactly once delivery¶
Knowing that exactly once delivery is one of the hardest problems to solve in distributed systems, how kafka does it?. Broker can fail or a network may respond slowly while a producer is trying to send events.
Producer can set acknowledge level to control the delivery semantic to ensure not loosing data. The following semantic is supported:
- At least once: means the producer set
ACKS=1and get an acknowledgement message when the message sent, has been written to at least one time in the cluster (assume replicas = 3). If the ack is not received, the producer may retry, which may generate duplicate records in case the broker stops after saving to the topic and before sending back the acknowledgement message. - At most semantic: means the producer will not do retry in case of no acknowledge received. It may create log and compensation, but the message may be lost.
- Exactly once means even if the producer sends the message twice the system will send only one message to the consumer. Once the consumer commits the read offset, it will not receive the message again, even if it restarts. Consumer offset needs to be in sync with produced event.
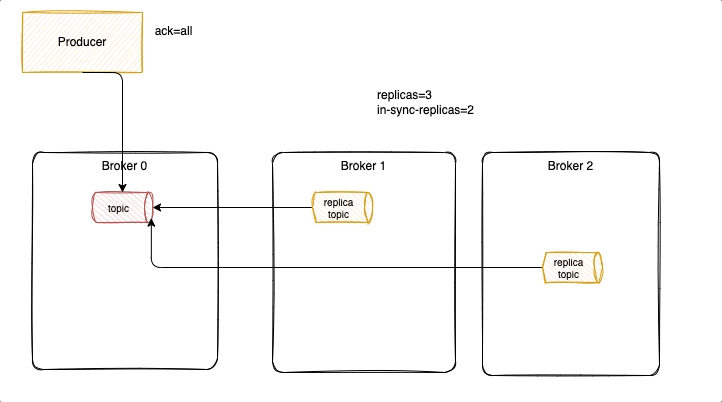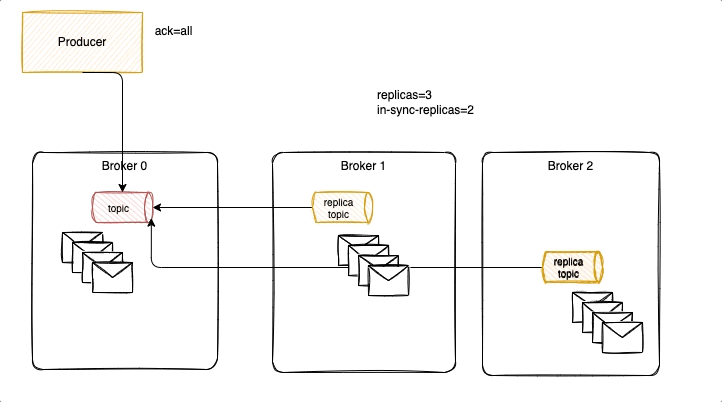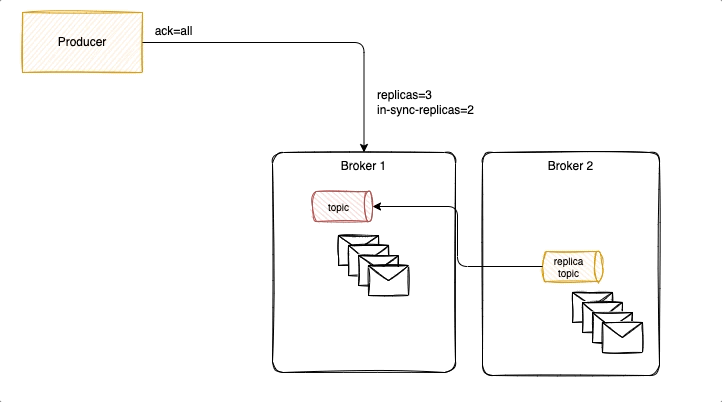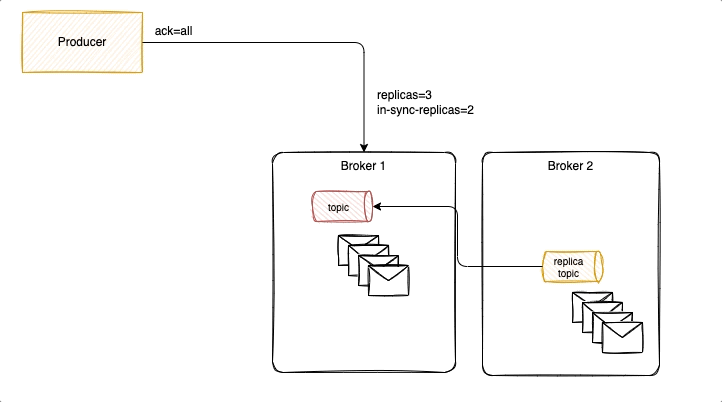
With acks = 1 it is possible to lose messages, as illustrated in the following diagram, where new messages were not replicated yet, and ack was already sent back to the producer. Losing messages will depend if a replica is taking the leader position or not, or if the failed broker goes back online before replicas election but has no fsynch to the disk before the crash.
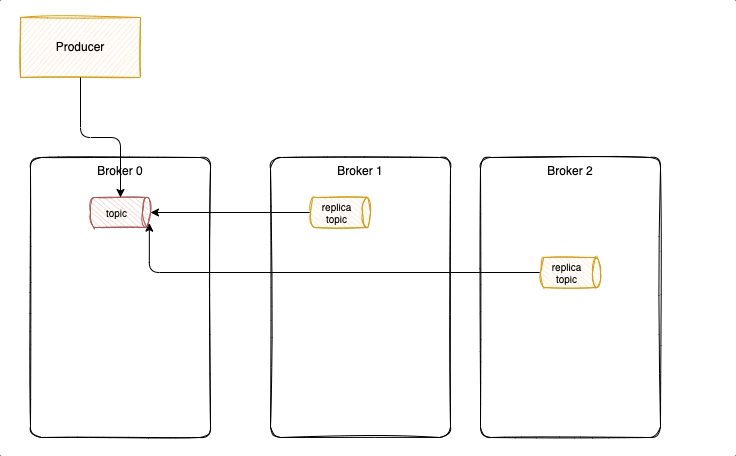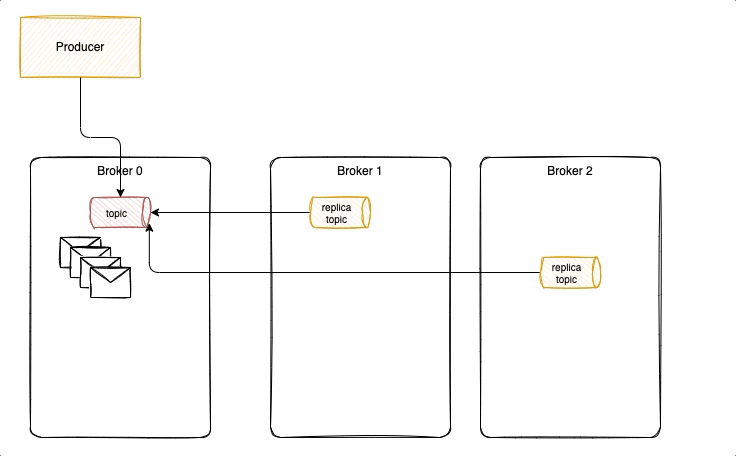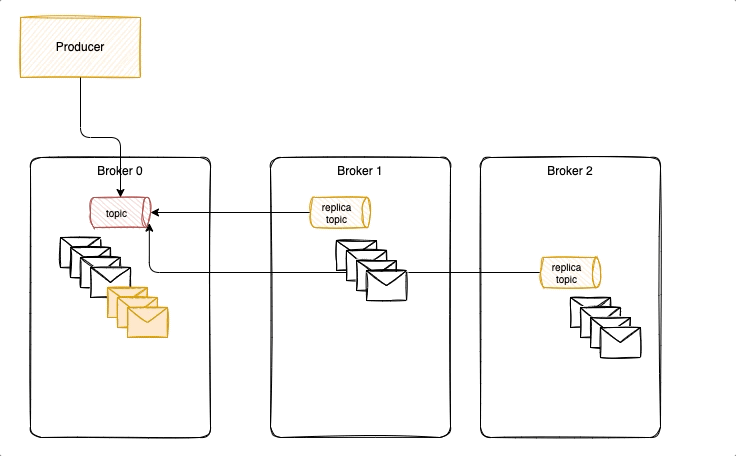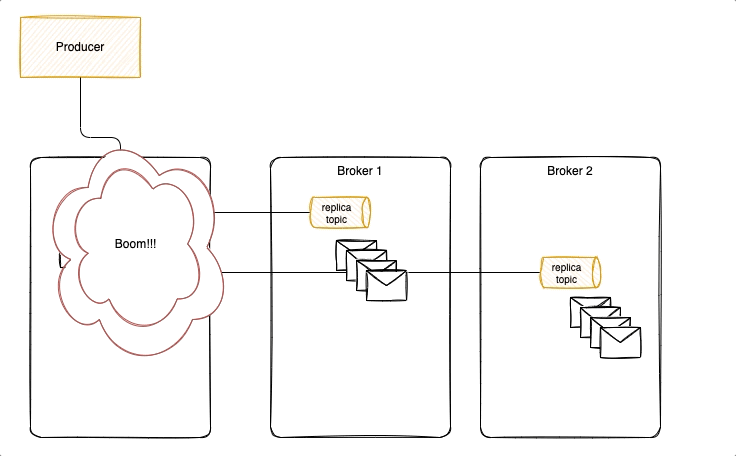
To avoid that we need to have ack=-1, three replicas and in-sync-replica=2. Replicated messages are acknowledged, when broker fails, a new leader is selected with the replicated messagesm it becomes the partition leader and others start to replicate from him. Producer reconnect to the partition leader.
Here is an example of cluster configuration with default set for all topic
Or at the topic level:
kind: KafkaTopic
metadata:
name: rt-store.inventory
namespace: rt-inventory-dev
labels:
eventstreams.ibm.com/cluster: dev
spec:
partitions: 1
replicas: 3
config:
min.insync.replicas: 1
At the best case scenario, with a replica factor set to 3, a broker responding on time to the producer, and with a consumer committing its offset and reading from the last committed offset it is possible to get only one message end to end.
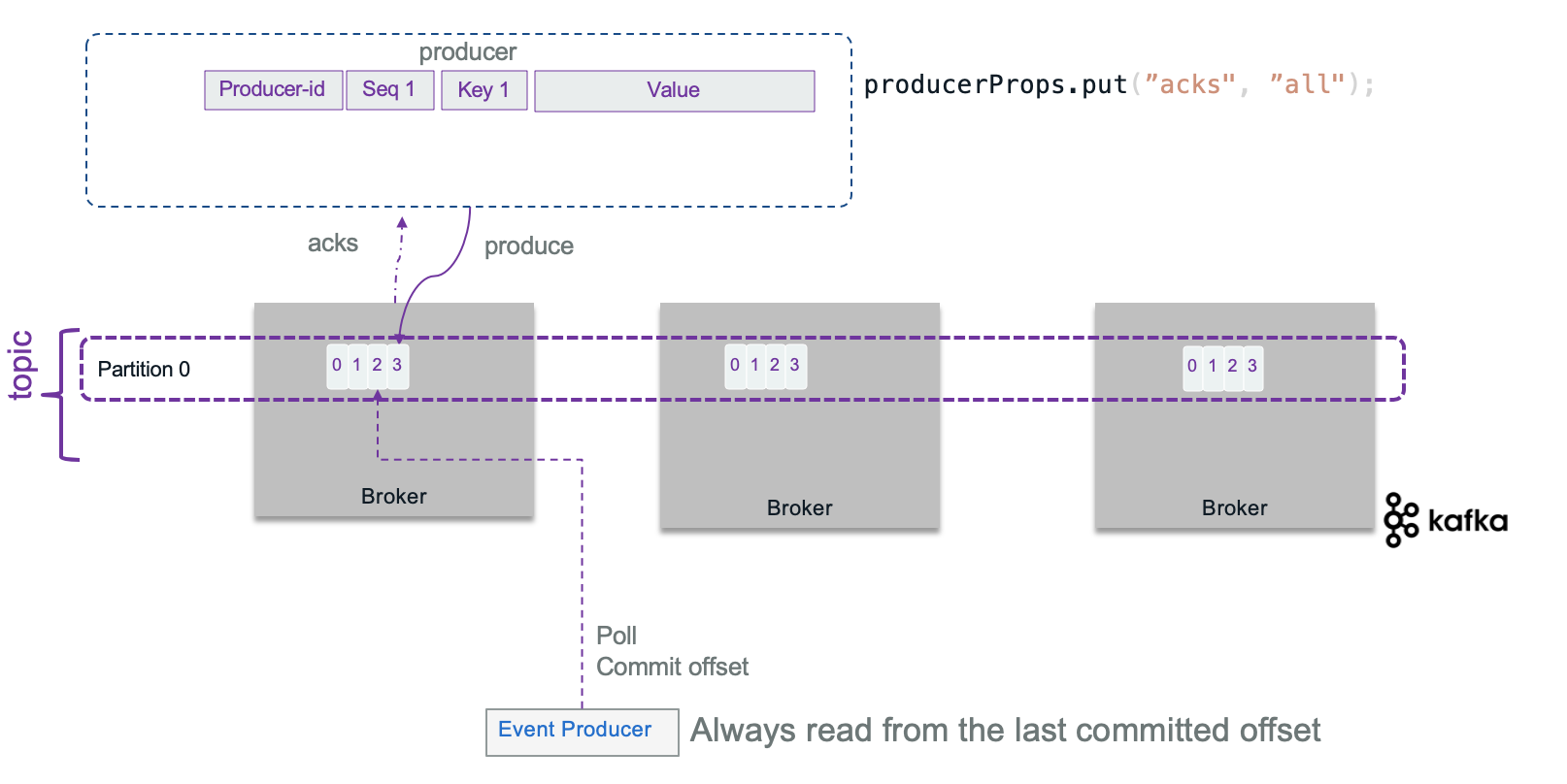
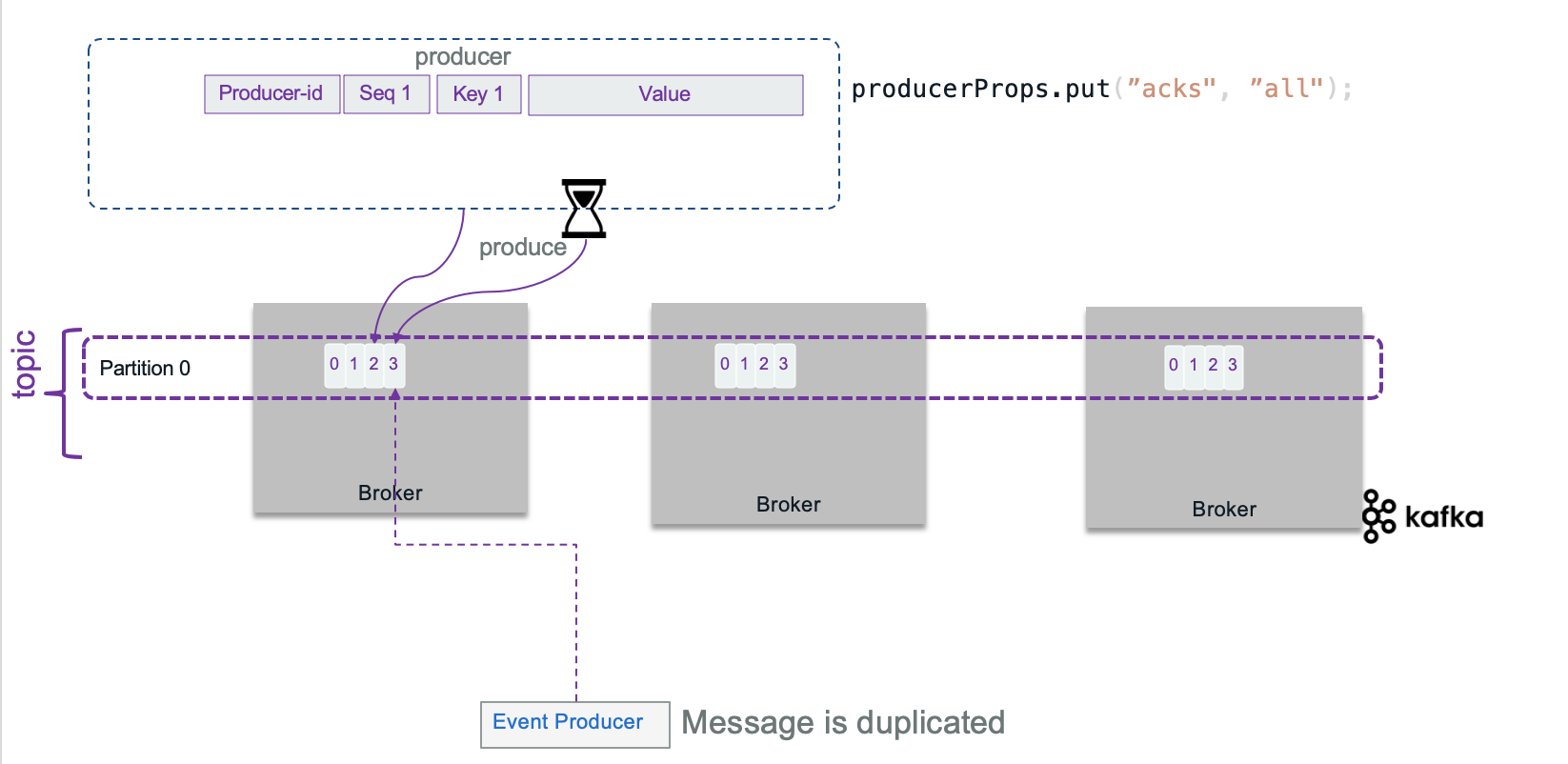
Sometime the brokers will not send acknowledge in expected time, and the producer may decide to send the records again, generating duplicate...
To avoid duplicate message at the broker level, when acknowledge is set to ALL, the producer can also set idempotence flag: ENABLE_IDEMPOTENCE_CONFIG = true. With the idempotence property, the record sent, has a sequence number and a producer id, so that the broker keeps the last sequence number per producer and per partition. If a message is received with a lower sequence number, it means a producer is doing some retries on record already processed, so the broker will drop it, to avoid having duplicate records per partition. If the id is greater than current id known by the broker, the broker will create an OutOfSequence exception, which may be fatal as records may have been lost.
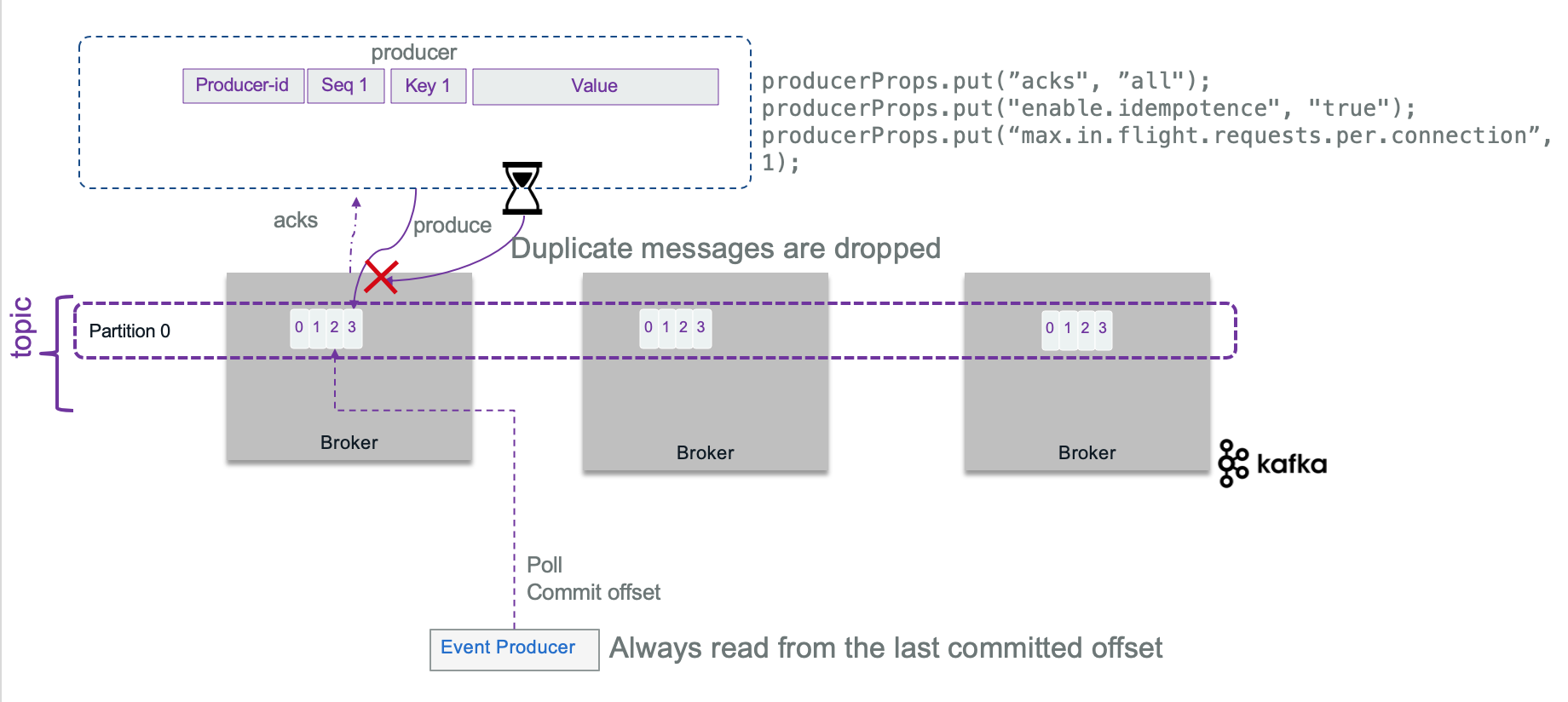
The sequence number is persisted in a log so even in case of broker leader failure, the new leader will have a good view of the states of the system.
The replication mechanism guarantees that, when a message is written to the leader replica, it will be replicated to all available replicas. As soon as you want to get acknowledge of all replicates, it is obvious to set idempotence to true. It does not impact performance.
To add to this discussion, as topic may have multiple partitions, idempotent producers do not provide guarantees for writes across multiple Topic-Partition. For that Kafka supports atomic writes to all partitions, so that all records are saved or none of them are visible to consumers. This transaction control is done by using the producer transactional API, and a transacitional protocol with coordinator and control message. Here is an example of such configuration that can be done in a producer constructor method:
producerProps.put("enable.idempotence", "true");
producerProps.put("transactional.id", "prod-1");
kafkaProducer.initTransactions()
initTransactions() registers the producer with the broker as one that can use transaction, identifying it by its transactional.id and a sequence number, or epoch. Epoch is used to avoid an old producer to commit a transaction while a new producer instance was created for that and continues its work.
Kafka streams with consume-process-produce loop requires transaction and exactly once. Even commiting its read offset is part of the transaction. So Producer API has a sendOffsetsToTransaction method.
See the KIP 98 for details.
In case of multiple partitions, the broker will store a list of all updated partitions for a given transaction.
To support transaction a transaction coordinator keeps its states into an internal topic (TransactionLog). Control messages are added to the main topic but never exposed to the 'user', so that consumers have the knowledge if a transaction is committed or not.
See the code in order command microservice.
The consumer is also interested to configure the reading of the transactional messages by defining the isolation level. Consumer waits to read transactional messages until the associated transaction has been committed. Here is an example of consumer code and configuration
consumerProps.put("enable.auto.commit", "false");
consumerProps.put("isolation.level", "read_committed");
With read_committed, no message that was written to the input topic in the same transaction will be read by this consumer until message replicas are all written.
In consume-process-produce loop, producer commits its offset with code, and specifies the last offset to read.
offsetsToCommit.put(partition, new OffsetAndMetadata(offset + 1))
producer.sendOffsetsToTransaction(offsetsToCommit, "consumer-group-id");
The producer then commits the transaction.
try {
kafkaProducer.beginTransaction();
ProducerRecord<String, String> record = new ProducerRecord<>(ApplicationConfig.ORDER_COMMAND_TOPIC, key, value);
Future<RecordMetadata> send = kafkaProducer.send(record, callBackFunction);
kafkaProducer.commitTransaction();
} catch (KafkaException e){
kafkaProducer.abortTransaction();
}
There is an interesting article from the Baeldung team about exactly once processing in kafka with code example which we have re-used to implement the order processing in our Reefer Container Shipment reference application and explained here
Code Examples¶
- Order management with CQRS in Java
- EDA quickstart Quarkus Producer API
- Springboot with kafka template
- Event driven microservice template