Apache Flink
Warning
Updated 08/20/2022- Work in progress
Why Flink?¶
In classical IT architecture, we can see two types of data processing: transactional and analytics. With 'monolytics' application, the database system serves multiple applications which sometimes access the same database instances and tables. This approach cause problems to support evolution and scaling. Microservice architecture addresses part of those problems by isolating data storage per service.
To get insight from the data, the traditional approach is to develop data warehouse and ETL jobs to copy and transform data from the transactional systems to the warehouse. ETL process extracts data from a transactional database, transforms data into a common representation that might include validation, value normalization, encoding, deduplication, and schema transformation, and finally loads the new record into the target analytical database. They are batches and run periodically.
From the data warehouse, the analysts build queries, metrics, and dashboards / reports to address a specific business question. Massive storage is needed, which uses different protocol such as: NFS, S3, HDFS...
Today, there is a new way to think about data by seeing they are created as continuous streams of events, which can be processed in real time, and serve as the foundation for stateful stream processing application: the analytics move to the real data stream.
We can define three classes of applications implemented with stateful stream processing:
- Event-driven applications: to adopt the reactive manifesto for scaling, resilience, responsive application, leveraging messaging as communication system.
- Data pipeline applications: replace ETL with low latency stream processing.
- Data analytics applications: immediatly act on the data and query live updated reports.
For more real industry use cases content see the Flink Forward web site.
The What¶
Apache Flink (2016) is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink supports batch (data set )and graph (data stream) processing. It is very good at:
- Very low latency processing event time semantics to get consistent and accurate results even in case of out of order events
- Exactly once state consistency
- Millisecond latencies while processing millions of events per second
- Expressive and easy-to-use APIs: map, reduce, join, window, split, and connect.
- SQL support to implement user friendly streaming queries
- Fault tolerance, and high availability: supports worker and master failover, eliminating any single point of failure
- A lot of connectors to integrate with Kafka, Cassandra, Elastic Search, JDBC, S3...
- Support container and deployment on Kubernetes
- Support updating the application code and migrate jobs to different Flink clusters without losing the state of the application
- Also support batch processing
The figure below illustrates those different models combined with Zepellin as a multi purpose notebook to develop data analytic projects on top of Spark, Python or Flink.
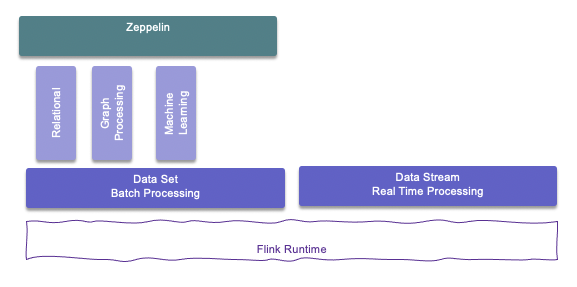
Flink architecture¶
Flink consists of a Job Manager and n Task Managers.
The JobManager controls the execution of a single application. It receives an application for execution and builds a Task Execution Graph from the defined Job Graph. It manages job submission and the job lifecycle then allocates work to Task Managers The Resource Manager manages Task Slots and leverages underlying orchestrator, like Kubernetes or Yarn. A Task slot is the unit of work executed on CPU. The Task Managers execute the actual stream processing logic. There are multiple task managers running in a cluster. The number of slots limits the number of tasks a TaskManager can execute. After it has been started, a TaskManager registers its slots to the ResourceManager
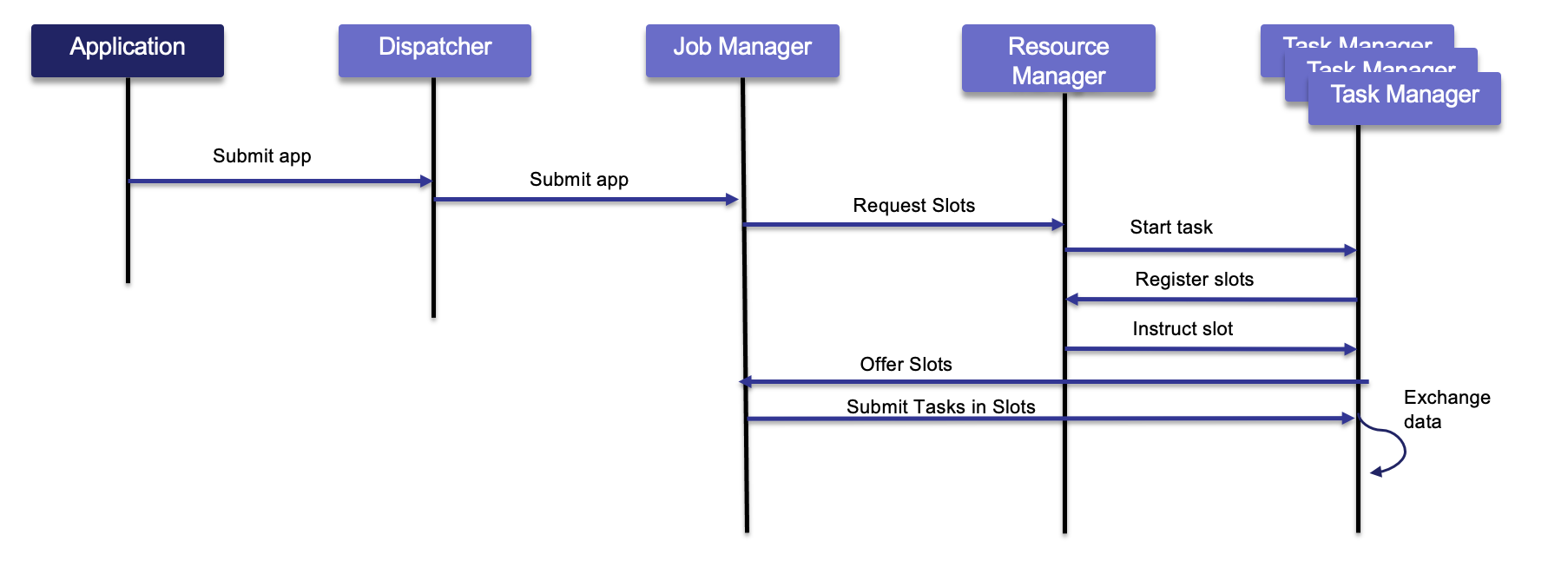
The Disparcher exposes API to submit applications for execution. It hosts the user interface too.
Only one Job Manager is active at a given point of time, and there may be n Task Managers.
There are different deployment models:
- Deploy on executing cluster, this is the session mode. Use session cluster to run multiple jobs: we need a JobManager container.
- Per job mode, spin up a cluster per job submission. More k8s oriented. This provides better resource isolation.
- Application mode creates a cluster per app with the main() function executed on the JobManager. It can include multiple jobs but they run inside the app. It allows for saving the required CPU cycles, but also save the bandwidth required for downloading the dependencies locally.
Flink can run on any common resource manager like Hadoop Yarn, Mesos, or Kubernetes. For development purpose, we can use docker images to deploy a Session or Job cluster.
Batch processing¶
Process all the data in one job with bounded dataset. It is used when we need all the data for assessing trend, develop AI model, and with a focus on throughput instead of latency.
Hadoop was designed to do batch processing. Flink has capability to replace Hadoop map reduce processing.
High Availability¶
With Task managers running in parallel, if one fails the number of available slots drops by the JobManager asks the Resource Manager to get new processing slots. The application's restart strategy determines how often the JobManager restarts the application and how long it waits between restarts.
Flink uses Zookeeper to manage multiple JobManagers and select the leader to control the execution of the streaming application. Application's tasks checkpoints and other states are saved in a remote storage, but metadata are saved in Zookeeper. When a JobManager fails, all tasks that belong to its application are automatically cancelled. A new JobManager that takes over the work by getting information of the storage from Zookeeper, and then restarts the process with the JobManager.
Stream processing concepts¶
In Flink, applications are composed of streaming dataflows that may be transformed by user-defined operators. These dataflows form directed graphs that start with one or more sources, and end in one or more sinks. The data flows between operations. The figure below, from product documentation, summarizes the simple APIs used to develop a data stream processing flow:

src: apache Flink product doc
Stream processing includes a set of functions to transform data, to produce a new output stream. Intermediate steps compute rolling aggregations like min, max, mean, or collect and buffer records in time window to compute metrics on finite set of events. To properly define window operator semantics, we need to determine both how events are assigned to buckets and how often the window produces a result. Flink's streaming model is based on windowing and checkpointing, it uses controlled cyclic dependency graph as its execution engine.
The following figure is showing integration of stream processing runtime with an append log system, like Kafka, with internal local state persistence and continuous checkpoint to remote storage as HA support:
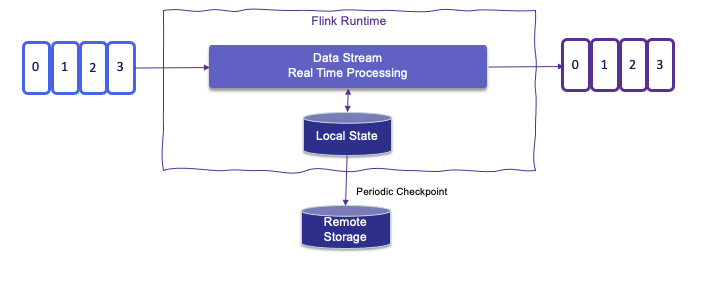
As part of the checkpointing process, Flink saves the 'offset read commit' information of the append log, so in case of a failure, Flink recovers a stateful streaming application by restoring its state from a previous checkpoint and resetting the read position on the append log.
The evolution of microservice is to become more event-driven, which are stateful streaming applications that ingest event streams and process the events with application-specific business logic. This logic can be done in flow defined in Flink and executed in the clustered runtime.
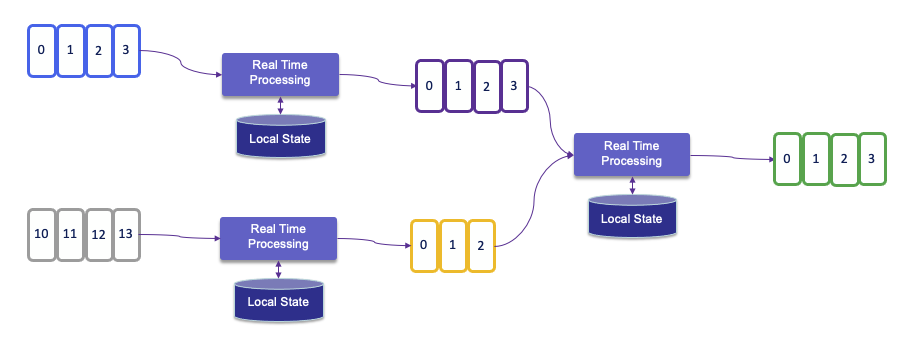
A lot of predefined connectors exist to connect to specific source and sink. Transform operators can be chained. Dataflow can consume from Kafka, Kinesis, Queue, and any data sources. A typical high level view of Flink app is presented in figure below:
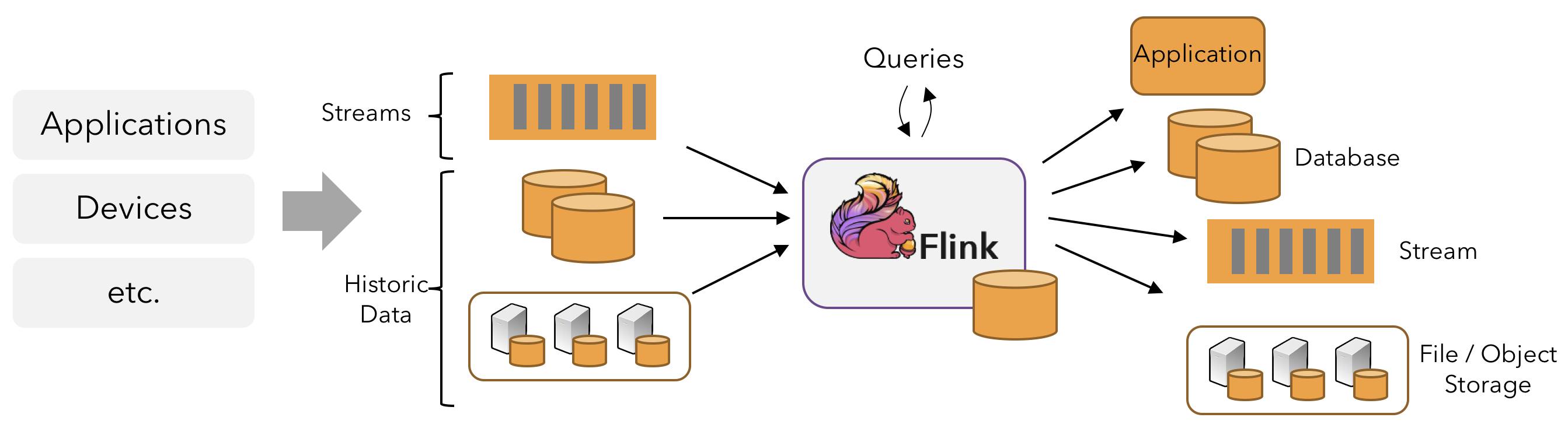
src: apache Flink product doc
Programs in Flink are inherently parallel and distributed. During execution, a stream has one or more stream partitions, and each operator has one or more operator subtasks.

src: apache Flink site
A Flink application, can be stateful, run in parallel on a distributed cluster. The various parallel instances of a given operator will execute independently, in separate threads, and in general will be running on different machines. State is always accessed local, which helps Flink applications achieve high throughput and low-latency. You can choose to keep state on the JVM heap, or if it is too large, saves it in efficiently organized on-disk data structures.
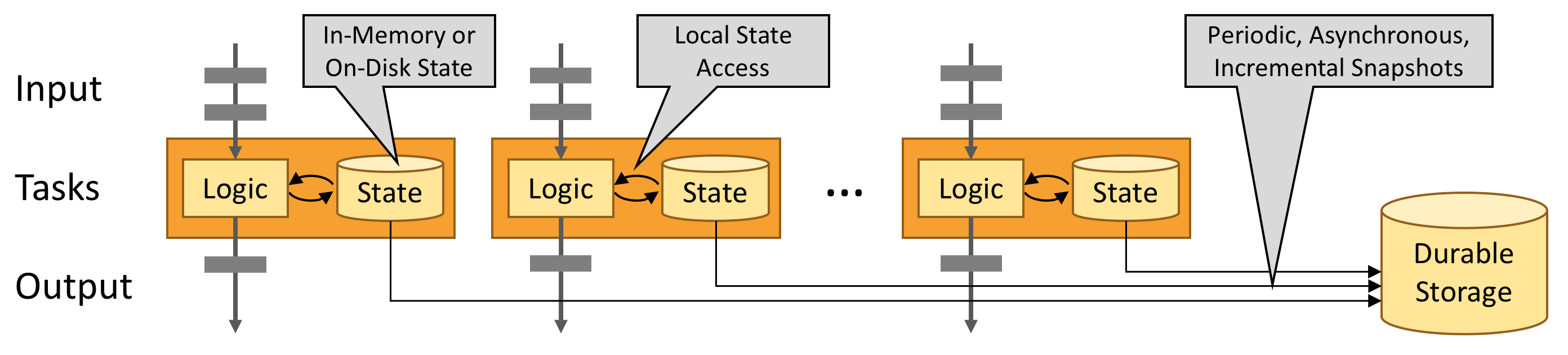
This is the Job Manager component which parallelizes the job and distributes slices of the Data Stream flow, you defined, to the Task Managers for execution. Each parallel slice of your job will be executed in a task slot.

Once Flink is started (for example with the docker image), Flink Dashboard http://localhost:8081/#/overview presents the execution reporting of those components:
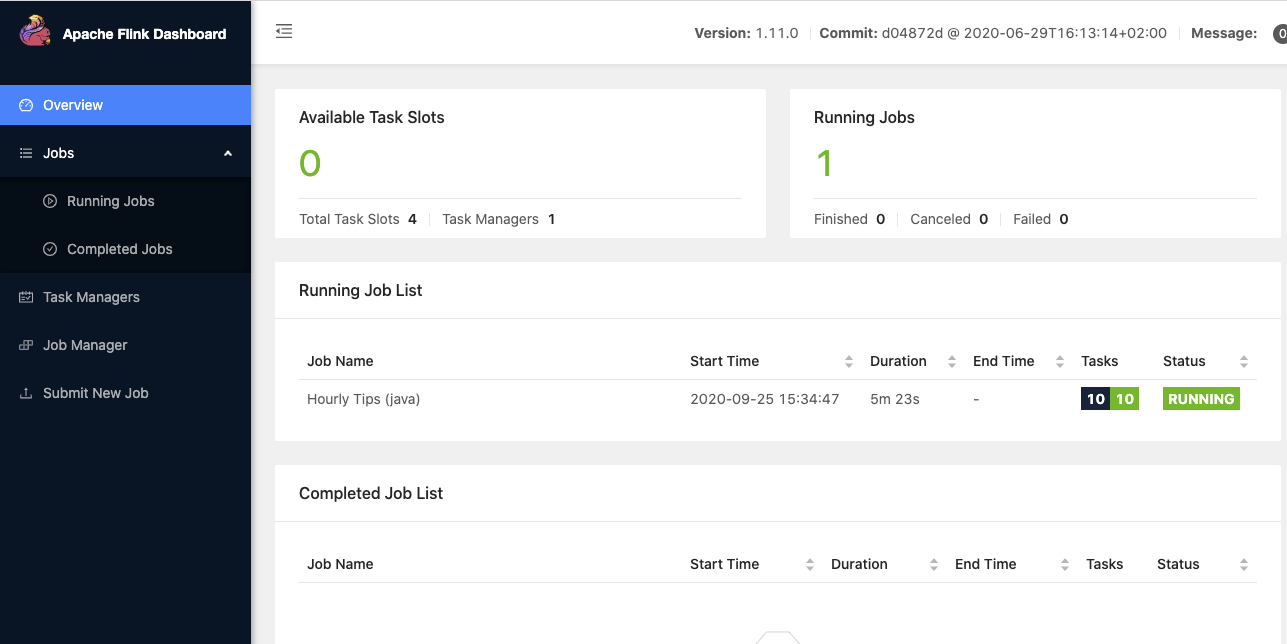
The execution is from one of the training examples, the number of task slot was set to 4, and one job is running.
Spark is not a true real time processing while Flink is. Flink and Spark support batch processing too.
Stateless¶
Some applications support data loss and expect fast recovery times in case of failure and always consuming the latest incoming data. Alerting applications where only low latency alerts are useful, or application where only the last data received is relevant.
When checkpointing is turned off Flink offers no inherent guarantees in case of failures. This means that you can either have data loss or duplicate messages combined always with a loss of application state.
Statefulness¶
When using aggregates or windows operators, states need to be kept. For fault tolerant Flink uses checkpoints and savepoints. Checkpoints represent a snapshot of where the input data stream is with each operator's state. A streaming dataflow can be resumed from a checkpoint while maintaining consistency (exactly-once processing semantics) by restoring the state of the operators and by replaying the records from the point of the checkpoint.
In case of failure of a parallel execution, Flink stops the stream flow, then restarts operators from the last checkpoints. When doing the reallocation of data partition for processing, states are reallocated too. States are saved on distributed file systems. When coupled with Kafka as data source, the committed read offset will be part of the checkpoint data.
Flink uses the concept of Checkpoint Barriers, which represents a separation of records, so records received since the last snapshot are part of the future snapshot. Barrier can be seen as a mark, a tag in the data stream that close a snapshot.
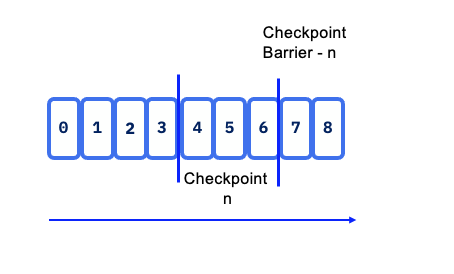
In Kafka, it will be the last committed read offset. The barrier flows with the stream so can be distributed. Once a sink operator (the end of a streaming DAG) has received the barrier n from all of its input streams, it acknowledges that snapshot n to the checkpoint coordinator. After all sinks have acknowledged a snapshot, it is considered completed. Once snapshot n has been completed, the job will never ask the source for records before such snapshot.
State snapshots are save in a state backend (in memory, HDFS, RockDB).
KeyedStream is a key-value store. Key match the key in the stream, state update does not need transaction.
For DataSet (Batch processing) there is no checkpoint, so in case of failure the stream is replayed. When addressing exactly once processing it is very important to consider the following:
- the read from the source
- apply the processing logic like window aggregation
- generate the results to a sink
1 and 2 can be done exactly once, using Flink source connector and checkpointing but generating one unique result to a sink is more complex and is dependant of the target technology.
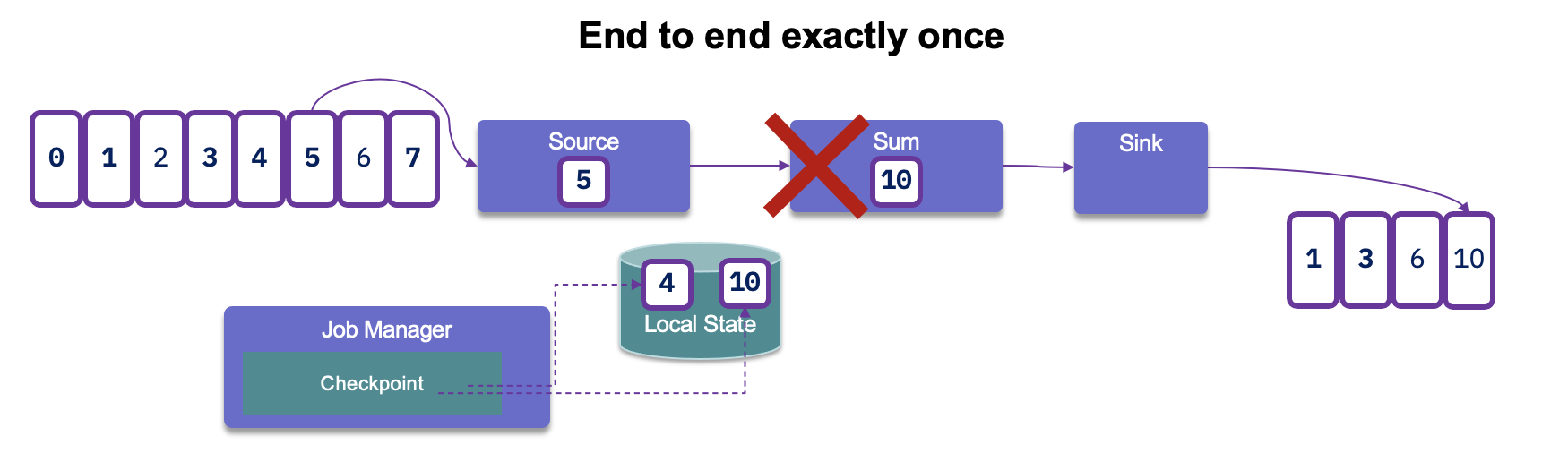
After reading records from Kafka, do the processing and generate results, in case of failure Flink will reload the record from the read offset and may generate duplicate in the Sink.
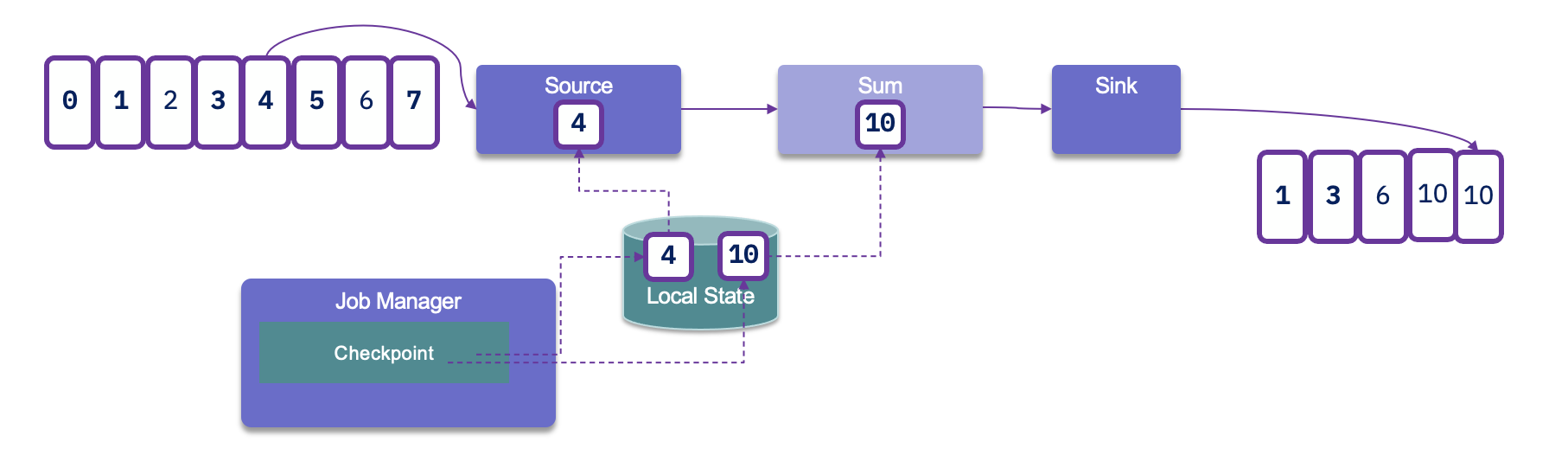
As duplicates will occur, we always need to assess idempotent support from downstream applications. A lot of distributed key-value storages support consistent result event after retries.
To support end-to-end exactly one delivery we need to have a sink that supports transaction and two-phase commit. In case of failure we need to rollback the output generated. It is important to note transactional output impacts latency.
Flink takes checkpoints periodically, like every 10 seconds, which leads to the minimum latency we can expect at the sink level.
For Kafka Sink connector, as kafka producer, we need to set the transactionId, and the delivery type:
new KafkaSinkBuilder<String>()
.setBootstrapServers(bootstrapURL)
.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("store-sol")
With transaction ID, a sequence number is sent by the kafka producer API to the broker, and so the partition leader will be able to remove duplicate retries.
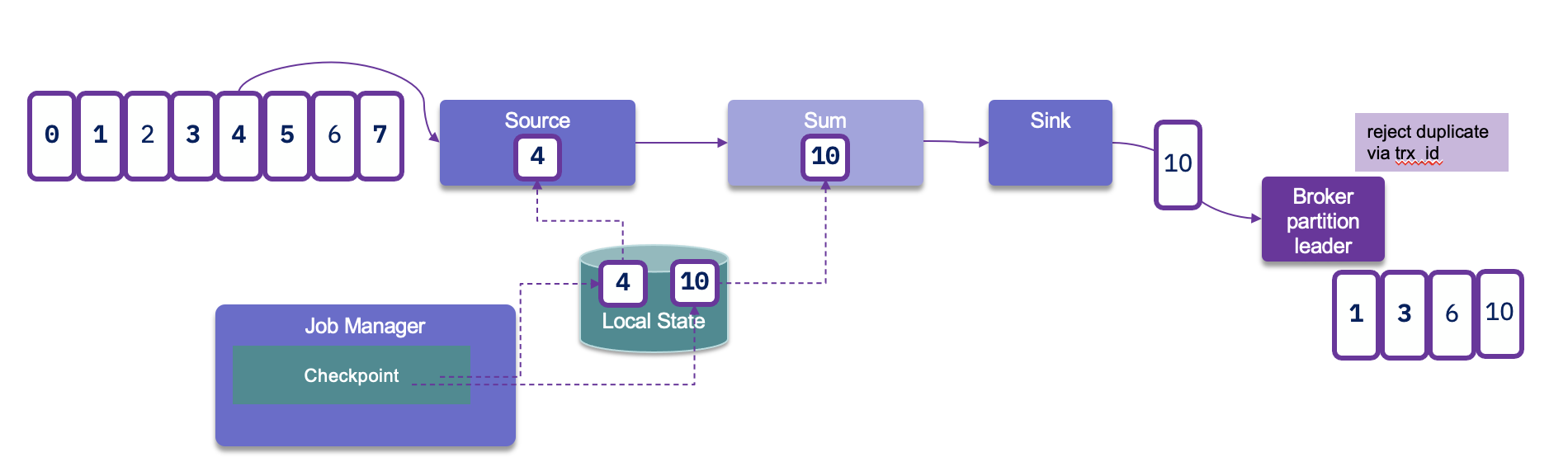
When the checkpointing period is set, we need to also configure transaction.max.timeout.ms of the Kafka broker and transaction.timeout.ms for the producer (sink connector) to a higher timeout than the checkpointing interval plus the max expected Flink downtime. If not the Kafka broker will consider the connection has fail and will remove its state management.
State management¶
- All data maintained by a task and used to compute the results of a function belong to the state of the task.
- While processing the data, the task can read and update its state and compute its result based on its input data and state.
- State management includes address very large states, and no state is lost in case of failures.
- Each operator needs to register its state.
- Operator State is scoped to an operator task: all records processed by the same parallel task have access to the same state
- Keyed state is maintained and accessed with respect to a key defined in the records of an operator’s input stream. Flink maintains one state instance per key value and Flink partitions all records with the same key to the operator task that maintains the state for this key. The key-value map is sharded across all parallel tasks:
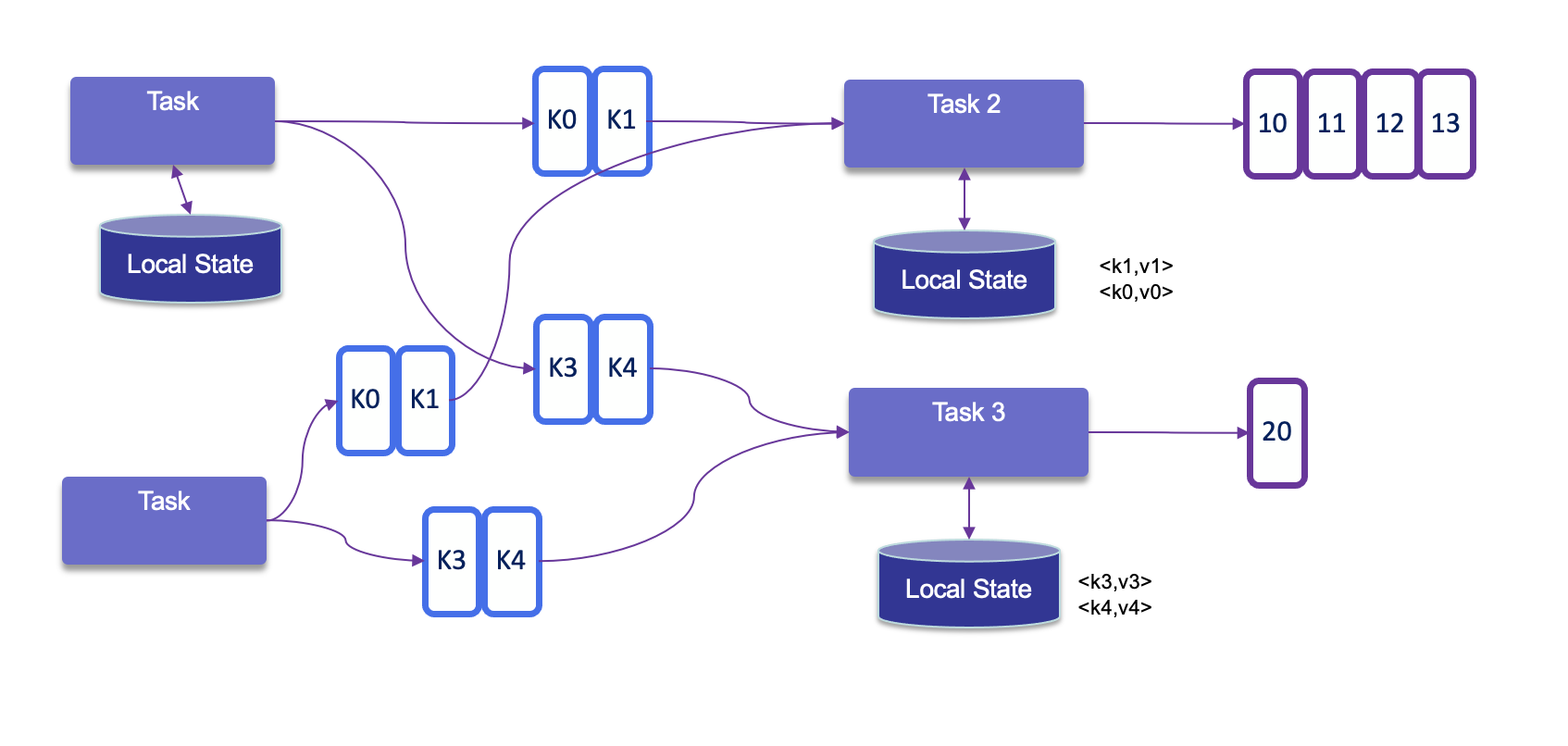
- Each task maintains its state locally to improve latency. For small state, the state backends will use JVM heap, but for larger state RocksDB is used. A state backend takes care of checkpointing the state of a task to a remote and persistent storage.
- With stateful distributed processing, scaling stateful operators, enforces state repartitioning and assigning to more or fewer parallel tasks. Keys are organized in key-groups, and key groups are assigned to tasks. Operators with operator list state are scaled by redistributing the list entries. Operators with operator union list state are scaled by broadcasting the full list of state entries to each task.
Flink uses Checkpointing to periodically store the state of the various stream processing operators on durable storage.
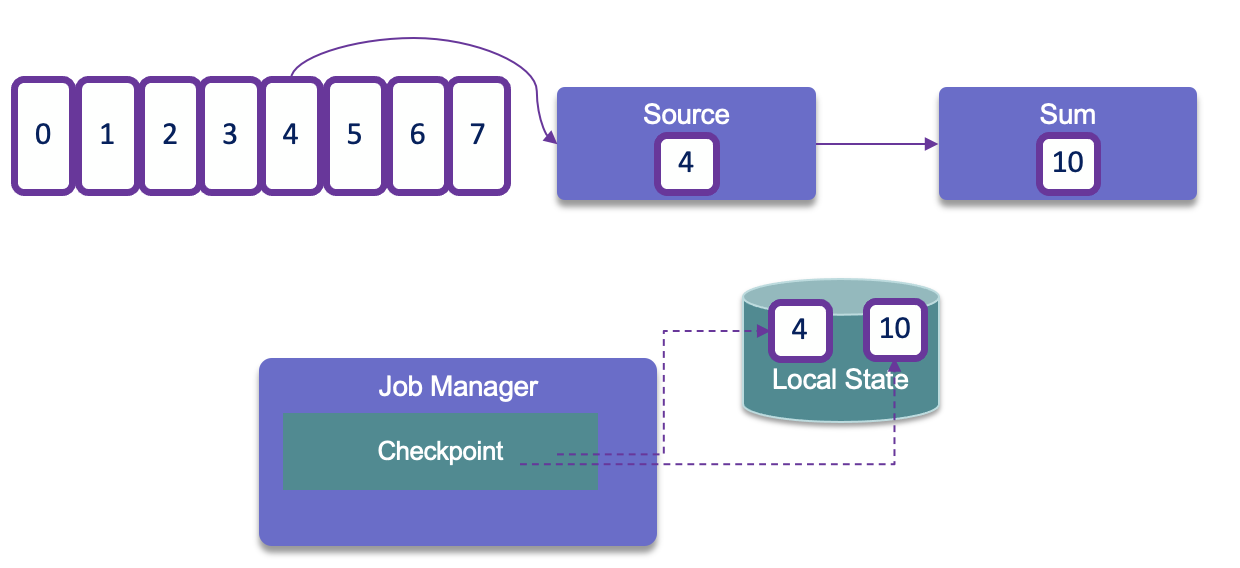
When recovering from a failure, the stream processing job can resume from the latest checkpoint.
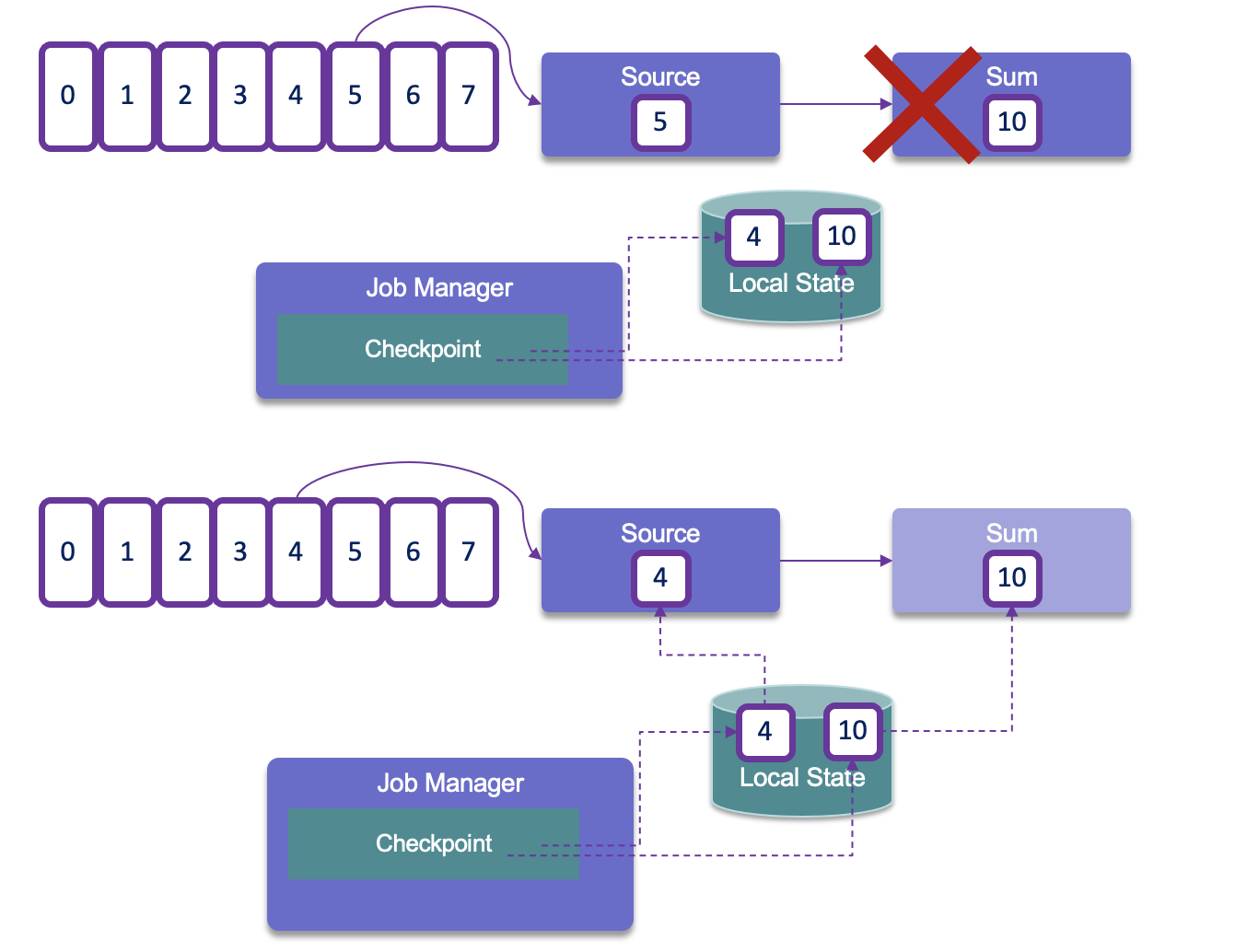
Checkpointing is coordinated by the Job Manager, it knows the location of the latest completed checkpoint which will get important later on. This checkpointing and recovery mechanism can provide exactly-once consistency for application state, given that all operators checkpoint and restore all of their states and that all input streams are reset to the position up to which they were consumed when the checkpoint was taken. This will work perfectly with Kafka, but not with sockets or queues where messages are lost once consumed. Therefore exactly-once state consistency can be ensured only if all input streams are from resettable data sources.
During the recovery and depending on the sink operators of an application, some result records might be emitted multiple times to downstream systems.
Windowing¶
Windows are buckets within a Stream and can be defined with times, or count of elements.
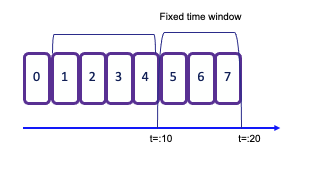
- Tumbling window assign events into nonoverlapping buckets of fixed size. When the window border is passed, all the events are sent to an evaluation function for processing. Count-based tumbling windows define how many events are collected before triggering evaluation. Time based timbling window define time interval of n seconds. Amount of the data vary in a window.
.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(2)))
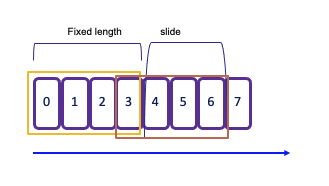
- Sliding window: same but windows can overlap. An event might belong to multiple buckets. So there is a
window sliding timeparameter:.keyBy(...).window(SlidingProcessingTimeWindows.of(Time.seconds(2), Time.seconds(1)))
- Session window: Starts when the data stream processes records and stop when there is inactivity, so the timer set this threshold:
.keyBy(...).window(ProcessingTimeSessionWindows.withGap(Time.seconds(5))). The operator creates one window for each data element received.
-
Global window: one window per key and never close. The processing is done with Trigger:
KeyStream can help to run in parallel, each window will have the same key.
Time is central to the stream processing, and the time is a parameter of the flow / environment and can take different meanings:
ProcessingTime= system time of the machine executing the task: best performance and low latencyEventTime= the time at the source level, embedded in the record. Deliver consistent and deterministic results regardless of orderIngestionTime= time when getting into Flink.
See example TumblingWindowOnSale.java and to test it, do the following:
# Start the SaleDataServer that starts a server on socket 9181 and will read the avg.txt file and send each line to the socket
java -cp target/my-flink-1.0.0-SNAPSHOT.jar jbcodeforce.sale.SaleDataServer
# inside the job manager container start with
`flink run -d -c jbcodeforce.windows.TumblingWindowOnSale /home/my-flink/target/my-flink-1.0.0-SNAPSHOT.jar`.
# The job creates the data/profitPerMonthWindowed.txt file with accumulated sale and number of record in a 2 seconds tumbling time window
(June,Bat,Category5,154,6)
(August,PC,Category5,74,2)
(July,Television,Category1,50,1)
(June,Tablet,Category2,142,5)
(July,Steamer,Category5,123,6)
...
Trigger¶
Trigger determines when a window is ready to be processed. All windows have default trigger. For example tumbling window has a 2s trigger. Global window has explicit trigger. We can implement our own triggers by implementing the Trigger interface with different methods to implement: onElement(..), onEventTime(...), onProcessingTime(...)
Default triggers:
- EventTimeTrigger: fires based upon progress of event time
- ProcessingTimeTrigger: fires based upon progress of processing time
- CountTrigger: fires when # of element in a window > parameter
- PurgingTrigger
Eviction¶
Evictor is used to remove elements from a window after the trigger fires and before or after the window function is applied. The logic to remove is app specific.
The predefined evictors: CountEvictor, DeltaEvictor and TimeEvictor.
Watermark¶
Watermark is the mechanism to keep how the event time has progressed: with windowing operator, event time stamp is used, but windows are defined on elapse time, for example, 10 minutes, so watermark helps to track te point of time where no more delayed events will arrive. The Flink API expects a WatermarkStrategy that contains both a TimestampAssigner and WatermarkGenerator. A TimestampAssigner is a simple function that extracts a field from an event. A number of common strategies are available out of the box as static methods on WatermarkStrategy, so reference to the documentation and examples.
Watermark is crucial for out of order events, and when dealing with multi sources. Kafka topic partitions can be a challenge without watermark. With IoT device and network latency, it is possible to get an event with an earlier timestamp, while the operator has already processed such event timestamp from other sources.
It is possible to configure to accept late events, with the allowed lateness time by which element can be late before being dropped. Flink keeps a state of Window until the allowed lateness time expires.
Resources¶
- Product documentation.
- Official training
- Base docker image is: https://hub.docker.com/_/flink
- Flink docker setup and the docker-compose files in this repo.
- FAQ
- Cloudera flink stateful tutorial: very good example for inventory transaction and queries on item considered as stream
- Building real-time dashboard applications with Apache Flink, Elasticsearch, and Kibana
- Udemy Apache Flink a real time hands-on: do not recommend this one !.