Kafka FAQ
Updated 03/29/2022
Basic questions¶
What is Kafka?¶
- pub/sub middleware to share data between applications
- Open source, started in 2011 by Linkedin
- based on append log to persist immutable records ordered by arrival.
- support data partitioning, distributed brokers, horizontal scaling, low-latency and high throughput.
- producer has no knowledge of consumer
- records stay even after being consumed
- durability with replication to avoid loosing data for high availability
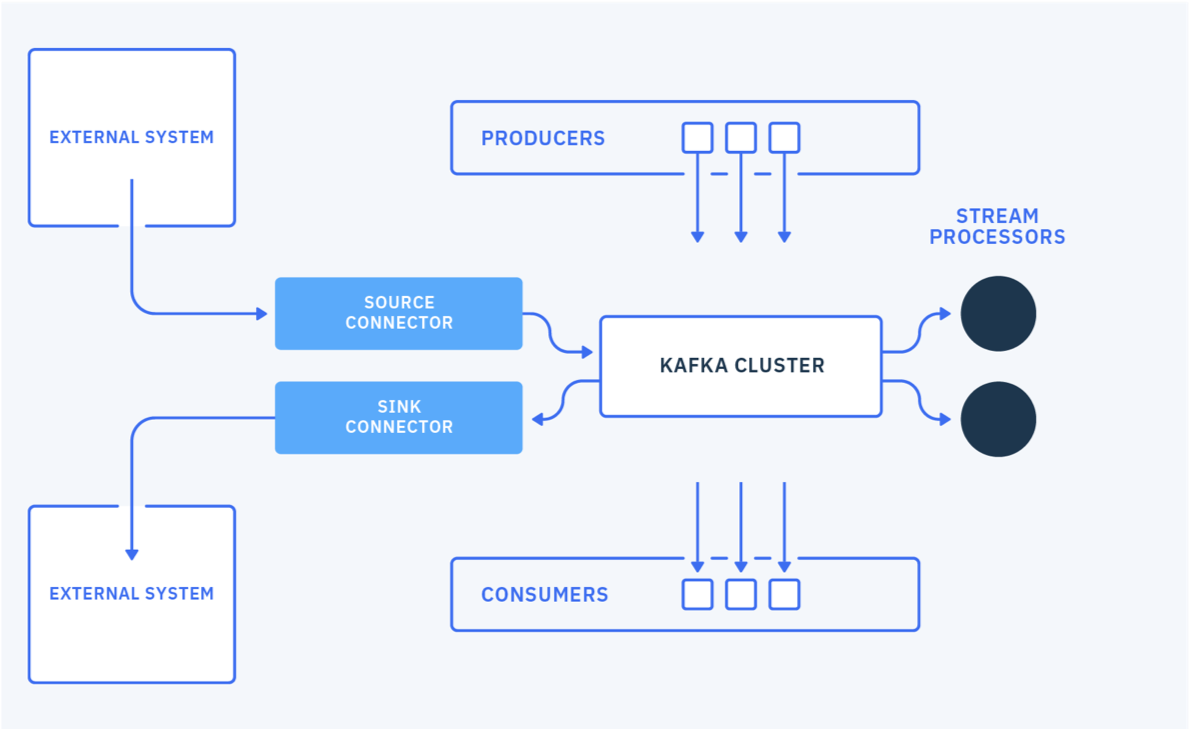
What are the major components?¶
- Topic, consumer, producer, brokers, cluster see this note for deep dive
- Rich API to control the producer semantic, and consumer
- Consumer groups. See this note for detail
- Kafka streams API to support data streaming with stateful operations and stream processing topology
- Kafka connect for source and sink connection to external systems
- Topic replication with Mirror Maker 2
What are major use cases?¶
- Modern data pipeline with buffering to data lake
- Data hub, to continuously expose business entities to event-driven applications and microservices
- Real time analytics with aggregate computation, and complex event processing
- The communication layer for Event-driven, reactive microservice.
Why does Kafka use zookeeper?¶
Kafka as a distributed system using cluster, it needs to keep cluster states, sharing configuration like topic, assess which node is still alive within the cluster, support registering new node added to the cluster, being able to support dynamic restart. Zookeeper is an orchestrator for distributed system, it maintains Kafka cluster integrity, select broker leader...
Zookeeper is also used to manage offset commit, and to the leader selection process.
Version 2.8 starts to get rid of Zookeeper so it uses another algorithm to define partition leadership and cluster health via one broker becoming the cluster controller. See this note on KIP 500
What is a replica?¶
A lit of nodes responsible to participate into the data replication process for a given partition.
It is a critical feature to ensure durability, be able to continue to consume records, or to ensure a certain level of data loss safety is guaranteed when producing records.
What are a leader and follower in Kafka?¶
Topic has 1 to many partition, which are append logs. Every partition in Kafka has a server that plays the role of leader. When replication is set in a topic, follower brokers will pull data from the leader to ensure replication, up to the specified replication factor.
If the leader fails, one of the followers needs to take over as the leader’s role. The leader election process involves zookeeper and assess which follower was the most in-synch with the leader.
Leader is the end point for read and write operations on the partition. (Exception is the new feature to read from local follower).
To get the list of In-synch Replication for a given topic the following tool can be used:
What is Offset?¶
A unique identifier of records inside a partition. It is automatically created by the broker, and producer can get it from the broker response.
Consumer uses it to commit its read. It means, in case of consumer restarts, it will read from the last committed offset.
What is a consumer group?¶
It groups consumers of one to many topics. Each partition is consumed by exactly one consumer within each subscribing consumer group.
Consumer group is specified via the group.id consumer's property, and when consumers subscribe to topic(s).
There is a protocol to manage consumers within a group so that partition can be reallocated when a consumer lefts the group. The group leader is responsible to do the partition assignment.
When using the group.instance.id properties, consumer is treated as a static member, which means there will be no partition rebalance when consumer lefts a group for a short time period. When not set the group coordinator (a broker) will allocate ids to group members, and reallocation will occur. For Kafka Streams application it is recommended to use static membership.
Brokers keep offsets until a retention period within which consumer group can lose all its consumers. After that period, offsets are discarded. The consumer group can be deleted manually, or automatically when the last committed offset for that group expires.
When the group coordinator receives an OffsetCommitRequest, it appends the request to a special compacted Kafka topic named __consumer_offsets. Ack from the broker is done once all replicas on this hidden topics are successful.
The tool kafka-consumer-group.sh helps getting details of consumer group:
# Inside a Kafka broker container
bin/kafka-consumer-groups.sh --bootstrap-server kafka:9092 --describe --group order-group --members --verbose
How to support multi-tenancy?¶
Multi-tenant means multiple different groups of application can produce and consumer messages isolated from other. So by constructs, topics and brokers are multi-tenant. Now the control will be at the access control level policy, the use of service account, and naming convention on the topic name. Consumer and producer authenticate themselves using dedicated service account users, with SCRAM user or Mutual TLS user. Each topic can have security policy to control read, write, creation operations.
How client access Kafka cluster metadata?¶
Provide a list of Kafka brokers, minimum two, so the client API will get the metadata once connected to one of the broker.
How to get at most once delivery?¶
Set producer acknowledge level (acks) property to 0 or 1.
How to support exactly once delivery?¶
The goal is to address that if a producer sends a message twice the system will send only one message to the consumer, and once the consumer commits the read offset, it will not receive the message again even if it restarts.
See the section in the producer implementation considerations note.
The consumer needs to always read from its last committed offset.
Also it is important to note that the Kafka Stream API supports exactly once semantics with the config: processing.guarantee=exactly_once. Each task within a read-process-write flow may fail so this setting is important to be sure the right answer is delivered, even in case of task failure, and the process is executed exactly once.
Exactly-once delivery for other destination systems generally requires cooperation with such systems which may be possible by using the offset processing.
Retention time for topic what does it mean?¶
The message sent to a cluster is kept for a max period of time or until a max size is reached. Those topic properties are: retention.ms and retention.bytes. Messages stay in the log even if they are consumed. The oldest messages are marked for deletion or compaction depending of the cleanup policy (delete or compact) set to cleanup.policy topic's parameter.
See the Kafka documentation on topic configuration parameters.
Here is a command to create a topic with specific retention properties:
bin/kafka-configs --zookeeper XX.XX.XX.XX:2181 --entity-type topics --entity-name orders --alter --add-config retention.ms=55000 --add-config retention.byte=100000
But there is also the offsets.retention.minutes property, set at the cluster level to control when the offset information will be deleted. It is defaulted to 1 day, but the max possible value is 7 days. This is to avoid keeping too much information in the broker memory and avoid to miss data when consumers do not run continuously. So consumers need to commit their offset. If the consumer settings define: auto.offset.reset=earliest, the consumer will reprocess all the events each time it restarts, (or skips to the latest if set to latest). When using latest, if the consumers are offline for more than the offsets retention time window, they will lose events.
What are the topic characteristics I need to define during requirements?¶
This is a requirement gathering related question, to understand what need to be done for configuration topic configuration but also consumer and producer configuration, as well as retention strategy.
- Number of brokers in the cluster
- retention time and size
- Need for HA, set replicas to number of broker or at least the value of 3, with in-synch replica to 2
- Type of data to transport to assess message size
- Plan to use schema management to control change to the payload definition
- volume per day with peak and average
- Need to do geo replication to other Kafka cluster
- Network filesystem used on the target Kubernetes cluster and current storage class
What are the impacts of having not enough resource for Kafka?¶
The table in this Event Streams product documentation illustrates the resource requirements for a getting started cluster. When resources start to be at stress, then Kafka communication to ZooKeeper and/or other Kafka brokers can suffer resulting in out-of-sync partitions and container restarts perpetuating the issue. Resource constraints is one of the first things we consider when diagnosing ES issues.
Security configuration¶
On Kubernetes, Kafka can be configured with external and internal URLs. With Strimzi internal URLs are using TLS or Plain authentication, then TLS for encryption.
If no authentication property is specified then the listener does not authenticate clients which connect through that listener. The listener will accept all connections without authentication.
- Mutual TLS authentication for internal communication looks like:
To connect any app (producer, consumer) we need a TLS user like:
piVersion: kafka.strimzi.io/v1beta2
kind: KafkaUser
metadata:
name: tls-user
labels:
strimzi.io/cluster: vaccine-kafka
spec:
authentication:
type: tls
Then the following configurations need to be done for each app. For example in Quarkus app, we need to specify where to find the client certificate (for each Kafka TLS user a secret is created with the certificate (ca.crt) and a user password)
oc describe secret tls-user
Data
====
ca.crt: 1164 bytes
user.crt: 1009 bytes
user.key: 1704 bytes
user.p12: 2374 bytes
user.password: 12 bytes
For Java client we need the following security settings, to specify from which secret to get the keystore password and certificate. The certificate will be mounted to /deployments/certs/user.
%prod.kafka.security.protocol=SSL
%prod.kafka.ssl.keystore.location=/deployments/certs/user/user.p12
%prod.kafka.ssl.keystore.type=PKCS12
quarkus.openshift.env.mapping.KAFKA_SSL_KEYSTORE_PASSWORD.from-secret=${KAFKA_USER:tls-user}
quarkus.openshift.env.mapping.KAFKA_SSL_KEYSTORE_PASSWORD.with-key=user.password
quarkus.openshift.mounts.user-cert.path=/deployments/certs/user
quarkus.openshift.secret-volumes.user-cert.secret-name=${KAFKA_USER:tls-user}
# To validate server side certificate we will mount it too with the following declaration
quarkus.openshift.env.mapping.KAFKA_SSL_TRUSTSTORE_PASSWORD.from-secret=${KAFKA_CA_CERT_NAME:kafka-cluster-ca-cert}
quarkus.openshift.env.mapping.KAFKA_SSL_TRUSTSTORE_PASSWORD.with-key=ca.password
quarkus.openshift.mounts.kafka-cert.path=/deployments/certs/server
quarkus.openshift.secret-volumes.kafka-cert.secret-name=${KAFKA_CA_CERT_NAME:kafka-cluster-ca-cert}
For the server side certificate, it will be in a truststore, which is mounted to /deployments/certs/server and from a secret (this secret is created at the cluster level).
Also because we also use TLS for encryption we need:
Mutual TLS authentication is always used for the communication between Kafka brokers and ZooKeeper pods. For mutual, or two-way, authentication, both the server and the client present certificates.
-
SCRAM: (Salted Challenge Response Authentication Mechanism) is an authentication protocol that can establish mutual authentication using passwords. Strimzi can configure Kafka to use SASL (Simple Authentication and Security Layer) SCRAM-SHA-512 to provide authentication on both unencrypted and encrypted client connections.
- The listener declaration:
- Need a scram-user:
Then the app properties need to have:
security.protocol=SASL_SSL
%prod.quarkus.openshift.env.mapping.KAFKA_SSL_TRUSTSTORE_PASSWORD.from-secret=${KAFKA_CA_CERT_NAME:kafka-cluster-ca-cert}
%prod.quarkus.openshift.env.mapping.KAFKA_SSL_TRUSTSTORE_PASSWORD.with-key=ca.password
%prod.quarkus.openshift.env.mapping.KAFKA_SCRAM_PWD.from-secret=${KAFKA_USER:scram-user}
%prod.quarkus.openshift.env.mapping.KAFKA_SCRAM_PWD.with-key=password
%prod.quarkus.openshift.mounts.kafka-cert.path=/deployments/certs/server
%prod.quarkus.openshift.secret-volumes.kafka-cert.secret-name=${KAFKA_CA_CERT_NAME:kafka-cluster-ca-cert}
Verify consumer connection¶
Here is an example of TLS authentication for Event streams
ConsumerConfig values:
bootstrap.servers = [eda-dev-kafka-bootstrap.eventstreams.svc:9093]
check.crcs = true
client.dns.lookup = default
client.id = cold-chain-agent-c2c11228-d876-4db2-a16a-ea7826e358d2-StreamThread-1-restore-consumer
client.rack =
connections.max.idle.ms = 540000
default.api.timeout.ms = 60000
enable.auto.commit = false
exclude.internal.topics = true
fetch.max.bytes = 52428800
fetch.max.wait.ms = 500
fetch.min.bytes = 1
group.id = null
group.instance.id = null
heartbeat.interval.ms = 3000
interceptor.classes = []
internal.leave.group.on.close = false
isolation.level = read_uncommitted
key.deserializer = class org.apache.kafka.common.serialization.ByteArrayDeserializer
sasl.client.callback.handler.class = null
sasl.jaas.config = null
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.login.callback.handler.class = null
sasl.login.class = null
sasl.login.refresh.buffer.seconds = 300
sasl.login.refresh.min.period.seconds = 60
sasl.login.refresh.window.factor = 0.8
sasl.login.refresh.window.jitter = 0.05
sasl.mechanism = GSSAPI
security.protocol = SSL
security.providers = null
send.buffer.bytes = 131072
session.timeout.ms = 10000
ssl.cipher.suites = null
ssl.enabled.protocols = [TLSv1.2]
ssl.endpoint.identification.algorithm = https
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = /deployments/certs/user/user.p12
ssl.keystore.password = [hidden]
ssl.keystore.type = PKCS12
ssl.protocol = TLSv1.2
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = /deployments/certs/server/ca.p12
ssl.truststore.password = [hidden]
ssl.truststore.type = PKCS12
value.deserializer = class org.apache.kafka.common.serialization.ByteArrayDeserializer
What Security support in Kafka¶
- Encrypt data in transit between producer and Kafka brokers
- Client authentication
- Client authorization
How to protect data at rest?¶
- Use encrypted file system for each brokers
- Encrypt data at the producer level, using some API, and then decode at the consumer level. The data in the appeld log will be encrypted.
More advanced concepts¶
What is range partition assignment strategy?¶
There are multiple partition assignment strategy for a consumer, part of a consumer group , to get its partition to fetch data from. Members of the consumer group subscribe to the topics they are interested in and forward their subscriptions to a Kafka broker serving as the group coordinator. The coordinator selects one member to perform the group assignment and propagates the subscriptions of all members to it. Then assign(Cluster, GroupSubscription) is called to perform the assignment and the results are forwarded back to each respective members.
Range assignor works on a per-topic basis: it lays out the available partitions in numeric order and the consumers in lexicographic order, and assign partition to each consumer so partition with the same id will be in the same consumer: topic-1-part-0 and topic-2-part-0 will be processed by consumer-0
What is sticky assignor?¶
The CooperativeStickyAssignor helps supporting incremental cooperative rebalancing to the clients' group protocol, which allows consumers to keep all of their assigned partitions during a rebalance and at the end revoke only those which must be migrated to another consumer for overall cluster balance.
The goal is to reduce unnecessary downtime due to unnecessary partition migration, by leveraging the sticky assignor which link consumer to partition id. See KIP 429 for details.
How to get an homogeneous distribution of message to partitions?¶
Design the message key and hash coding for even distributed. Or implement a customer partitioner by implementing the Partitioner interface.
How to ensure efficient join between two topics?¶
Need to use co-partitioning, which means having the same key in both topic, the same number of partitions and the same producer partitioner, which most likely should be the default one that uses the following formula: partition = hash(key) % numPartitions.
What is transaction in Kafka?¶
Producer can use transaction begin, commit and rollback API while publishing events to a multi partition topic. This is done by setting a unique transactionId as part of its configuration (with idempotence and min inflight record set to 1). Either all messages are successfully written or none of them are.
There are some producer exception to consider to abort the transaction: any KafkaException for sure, but also OutOfSequenceTx which may happen when the PID is greater than the last one seen by the producer.
See explanations here.
And the KIP 98
What is the high watermark?¶
The high watermark offset is the offset of the last message that was successfully copied to all of the log’s replicas. A consumer can only read up to the high watermark offset to prevent reading un-replicated messages.
What should we do for queue full exception or timeout exception on producer?¶
The brokers are running behind, so we need to add more brokers and redistribute partitions.
How to send large messages?¶
We can set some properties at the broker, topic, consumer and producer level:
- Broker: consider the message.max.bytes and replica.fetch.max.bytes
- Consumer: max.partition.fetch.bytes. Records are fetched in batches by the consumer, so this properties gives the max amount of data per partition the server will return. Default 1 Megabyte
How to maximize throughput?¶
For producer if you want to maximize throughput over low latency, set batch.size and linger.ms to higher value. Linger delay producer, it will wait for up to the given delay to allow other records to be sent so that the sends can be batched together.
Why Kafka Stream applications may impact cluster performance?¶
- They may use internal hidden topics to persist their states for Ktable and GlobalKTable.
- Process input and output topics
How message schema version is propagated?¶
The record includes a byte with the version number from the schema registry.
Consumers do not see message in topic, what happens?¶
The brokers may have an issue on this partition. If a broker, part of the ISR list fails, then new leader election may delay the broker commit from a producer.
The consumer has a communication issue, or fails, so the consumer group rebalance is underway.
How compression schema used is known by the consumer?¶
The record header includes such metadata. So it is possible to have different schema per record.
What does out-of-synch partition mean and when it occurs?¶
With partition leader and replication to the followers, the number of in-synch replicas is at least the number of expected replicas. For example for a replicas = 3 the in-synch is set to 2, and it represents the minimum number of replicas that must acknowledge a write for the write to be considered successful. The record is considered “committed” when all ISRs for a partition wrote to their log. Only committed records are readable from consumer.
So out-of-synch will happen if the followers are not able to send their acknowledge to the replica leader as quickly as expected.
Run Kafka Test Container with TopologyTestDriver¶
Topology Test Driver is used without kafka, so there is no real need to use test container.
How to remove personal identifying information?¶
From the source connector, it is possible to add processing class to process the records before publishing them to Kafka topic, so that any Kafka Streams apps will not see PII.
How to handle variable workload with Kafka Connector source connector?¶
Increase and decrease the number of Kafka connect workers based upon current application load.
Derived products related questions¶
Competitors to Kafka¶
- NATS
- Redpanda a Modern streaming platform for mission critical workloads, and is compatible with Kafka API. It is a cluster of brokers without any zookeepers. It also leverage the SSD technology to improve I/O operations.
-
- Cloud service, managed by AWS staff, paid as you go, proportional to the shard (like partition) used.
- 24h to 7 days persistence
- Number of shards are adaptable with throughput.
- Uses the concept of Kinesis data streams, which uses shards: data records are composed of a sequence number, a partition key and a data blob.
- restrictions on message size (1 MB) and consumption rate of messages (5 reads /s, < 2MB per shard, 1000 write /s)
- Server side encryption using master key managed by AWS KMS
-
GCP Pub/sub
- Solace
-
Active MQ:
- Java based messaging server to be the JMS reference implementation, so it supports transactional messaging.
- various messaging protocols including AMQP, STOMP, and MQTT
- It maintains the delivery state of every message resulting in lower throughput.
- Can apply JMS message selector to consumer specific message
- Point to point or pub/sub, but servers push messages to consumer/subscribers
- Performance of both queue and topic degrades as the number of consumers rises
-
Rabbit MQ:
- Support queues, with messages removed once consumed
- Add the concept of Exchange to route message to queues
- Limited throughput, but can send large message
- Support JMS, AMQP protocols, and participation to transaction
- Smart broker / dumb consumer model that focuses on consistently delivering messages to consumers.
Differences between AMQ Streams and Confluent¶
AMQ Streams and Confluent are based on the open source Kafka, but Confluent as the main contributer to Kafka, is adding proprietary features to make the product more marketable, so we will not do a pure features comparison a generic features comparison:
| Feature | Confluent | AMQ Streams |
|---|---|---|
| Kafka open source | Aligned within a month to the Kafka release | Within 2 months after Kafka release |
| Kafka API | Same | Same |
| k8s / OpenShift deployment | Helm "operator" | Real Kubernetes Operator based on open source Strimzi |
| Kafka Connectors | Connectors hub to reference any connectors on the market, with some certified for Confluent. | Open source connectors supported. Apache Camel offers a set of connectors not directly supported by Red Hat but useful in a BYO connectors. Fuse and Debezium can be used. |
| Schema registry | Proprietary API and schema | Solution may leverage open source Apicur.io schema registry which is compatible with Confluent API. |
| Cruise control for auto cluster balancing | Adds on | Available via Operator |
| Mirroring between clusters | Replicator tool | Mirror Maker 2 deployable and managed by Strimzi operator |
| Multi region cluster | Supported | Supported |
| Role Based access control | Supported | Supported with explicit user manifest, integrated with Red Hat SSO and OPA. |
| ksql | Open sourced licensed by Confluent | Customer can use open source version of kSQL but meed to verify licensing for cloud deployment. SQL processing on Kafka Records may also being done with Apache Flink |
| Kafka Streams | Supported from Kafka Open Source | Supported from Kafka Open Source. Also moving CEP and Streams processing to an external tool makes a lot more sense. Apache Flink should be considered. Not directly supported by Red Hat |
| Storage | NFS and tiered storage | Block storage with replication to s3 buckets for long persisence using Kafka connector. S3 Connector is not supported by Red Hat. |
| As a managed service | Proprietary solution | Same with: IBM Event Streams and Red Hat AMQ streams as a service |
| Integration with IBM mainframe | Not strategic - Weak | Strong with IBM connector and deployment on Z and P |
| Admin User Interface | Control center | Operator in OpenShift and 3nd party open-source user interface like Kafdrop, Kowl, work with AMQ Streams but without direct support from Red Hat |
As Kafka adoption is a strategic investment, it is important to grow the competency and skill set to manage kafka clusters. Zookeeper was an important element to complexify the cluster management, as 2.8 it is removed, so it should be simpler to manage cluster.
With customers cann influence the product roadmap, but it will kill the open source approach if only Confluent committers prioritize the feature requets. It is important to keep competitions and multi committers.
Event streams resource requirements¶
See the detailed tables in the product documentation.
Differences between Akka and Kafka?¶
Akka is a open source toolkit for Scala or Java to simplify multithreading programming and makes application more reactive by adopting an asynchronous mechanism to access to io: database or HTTP request. To support asynchronous communication between 'actors', it uses messaging, internal to the JVM. Kafka is part of the architecture, while Akka is an implementation choice for one of the component of the business application deployed inside the architecture.
vert.x is another open source implementation of such internal messaging mechanism but supporting more language: Java, Groovy, Ruby, JavaScript, Ceylon, Scala, and Kotlin.
Is is possible to stream video to kafka?¶
Yes it is possible, but need to do that with care and real justification. If the goal is to classify streamed images, then it is possible to do so, and need to assess if it will be important to be streams versus video at rest.
The following article, from Neeraj Krishna illustrates a python implementation to send video frame every 3 images, do image classification using ResNet50 model trained on ImageNet, embbeded in python consumer. The results are saved in mongodb with the metadata needed to query after processing.