Avro Schema
Updates 6/20/2022
This chapter describes what and why Avro and Schema registry are important elements of any event-driven solutions.
Why this is important¶
Loosely coupling and asynchronous communication between applications does not mean there is no contract to enforce some constraint between producer and consumer. When we talk about contract we can first think about schema as we did with XSD. In the world of JSON, JSON schema and Avro schemas can be used to define data structure of the message. As there is a need to get metadata around messaging, cloudevents is well accepted and adopted as a specification to describe event data. Also AsyncAPI establishes standards for events and messaging in the asynchronous world with an API view, so combining message schema, channels and binding definitions so we have most of the needed information for a consumer to access a data stream or queue.
So the contract is defined with a schema. From an EDA design point of view, the producer owns the definition of the schema as it owns the main business entity life cycle, events are generated from. Producer will make sure the message complies with the schema at hand for serializing.
On top of those specifications, there are technologies to support the contract management in the form of schema registry and API manager. The following figure gives us the foundations for integration between producer, schema registry and consumers.
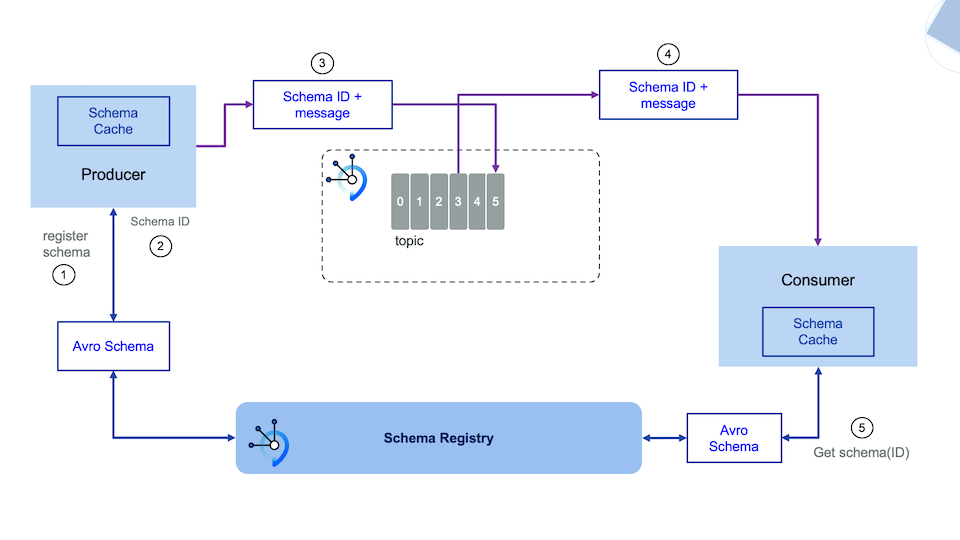
Schema Registry provides producer and consumer APIs so that these can project whether the event they are about to produce or consume is compatible with previous versions or compatible with the version they are expecting. For that, both producers and consumers require the schema definition at hand at serialization and deserialization time. This can be done either by:
- Reading the schema from a local local resource to your producer such as a file, variable, property (or kubernetes construct such as configmap or secret).
- Retrieving the schema definition from the Schema Registry given a name/ID.
When the producer wants to send an event to a Kafka topic, two things happen:
- The producer makes sure the event to be sent complies to the schema. Otherwise, it errors out.
- Project whether the event they are about to produce or consume is compatible with previous versions or compatible with the version they are expecting.
For the first action, the producer already holds the two things it needs: the schema definition the event to be sent needs to comply with and the event itself. The producer is therefore able to carry out that compliance check. However, for the second action, where the producer needs to make sure the schema definition your event complies with is compatible with the existing schema definition for the topic in question (if any), the producer might need to contact the schema registry.
Producers (and consumers) maintain a local cache with the schema definitions (and their versions) along with their unique global IDs (all of these retrieved from the schema registry) for the topics they want to produce/consume events to/from. If the producer has a schema definition in its local cache that matches the schema definition at hand for the serialization of the event, it simply sends the event as the schema definitions match and the event complies with such schema definition. However, if the producer does not have any schema definition in its local cache that matches the schema defintion at hand for the serialization of the event, whether because these are different versions or the producer simply does not have any schema definition in its cache, it contacts the schema registry.
-
If a schema defintion for the topic in question that matches the schema definition at hand at serialization time in the producer already exists in the schema registry, the producer simply retrieves the global unique ID for that schema definition to locally cache it along with the schema definition itself for future events to be sent so that it avoids contacting the schema registry again.
-
If a schema definition for the topic in question that matches the schema definition at hand at serialization time in the producer does not already exist in the schema registry, the producer must be able to register the schema definition it has got at hand for the topic in question at serialization time in the schema registry so that such schema definition is now available for any consumer wanting or needing to consume events that comply with such schema definition. For that, the producer must be configured to be able to auto-register schemas and also be provided with the appropriate credentials to register schema definitions from the schema registry perspective if this implements any type of RBAC mechanism (as it is the case for IBM Event Streams).
- If the producer is not configured to auto-register schema definitions or its credentials does not allow it to register schema definitions, then the send event action will fail until there is a schema definition for the topic in question that mateches the schema definition at hand at serialization time in the producer registered in the schema registry.
- If the producer is configured to auto-register schema definitions and its credentials allows it to register schema definitions, the schema registry validates the compatibility of the schema definition at hand at serialization time in the producer with existing schema definitions for the topic in questions (if any) to make sure that, if this schema definition to be registered is a newer version of any existing schema definition, it is complatible so that no consumer gets affected by this new schema definition version. Afer the schema definition or newer version of an exisint schema definition is registered in the schema registry, the producer retrieves its global unique ID to mantain its local cache up to date.
Warning
We stongly recommend that producers are not allowed to register schema definitions in the schema registry for better governance and management of schema definitions. It is highly recommended that schema definitions registration is done by someone responsible for such task with appropriate role (such as an admin, an API manager, an asynchronous API manager, a development manager, an operator, etc).
Once the producer has a schema definition in its local cache, along with its global unique id, that matches the schema definition at hand for serialization of the event to be sent, it produces the event to the Kafka topic using the appropriate AvroKafkaSerializer class. The schema definition global unique ID gets serialized along with the event so that the event does not need to travel along with its schema definition as it was the case in older messaging or eventing techonolgies and systems.
By default, when a consumer reads an event, the schema definition for such event is retrieved from the schema registry by the deserializer using the global unique ID, which is specified in the event being consumed. The schema definition for an event is retrieved from the schema registry only once, when an event comes with a global unique ID that can not be found in the schema definition cache the consumer maintains locally. The schema definition global unique ID can be located in the event headers or in the event payload, depending on the configuration of the producer application. When locating the global unique ID in the event payload, the format of the data begins with a magic byte, used as a signal to consumers, followed by the global unique ID, and the message data as normal. For example:
Be aware that non Java consumers use a C library that might require the schema definition at hand for the deserializer too (see https://github.com/confluentinc/confluent-kafka-python/issues/834) as opposed to letting the deserializer retrieve the schema definition from the schema registry as explained above. The strategy would be to have the schema loaded from the schema registry via API.
Schema Registry¶
With a pure open-source strategy, Event Streams within Cloud Pak for integration is using Apicu.io as schema registry. The Event Streams product documentation is doing an excellent job to present the schema registry, we do not need to rewrite the story, just give you some summary from Apicur.io and links to code samples.
Apicurio¶
Apicur.io includes a schema registry to store schema definitions. It supports Avro, json, protobuf schemas, and an API registry to manage OpenApi and AsynchAPI.
It is a Cloud-native Quarkus Java runtime for low memory footprint and fast deployment times. It supports different persistences like Kafka, Postgresql, Infinispan and supports different deployment models.
Registry Characteristics¶
- Apicurio Registry is a datastore for sharing standard event schemas and API designs across API and event-driven architectures. In the messaging and event streaming world, data that are published to topics and queues often must be serialized or validated using a Schema.
- The registry supports adding, removing, and updating the following types of artifacts: OpenAPI, AsyncAPI, GraphQL, Apache Avro, Google protocol buffers, JSON Schema, Kafka Connect schema, WSDL, XML Schema (XSD).
- Schema can be created via Web Console, core REST API or Maven plugin
- It includes configurable rules to control the validity and compatibility.
- Client applications can dynamically push or pull the latest schema updates to or from Apicurio Registry at runtime. Apicurio is compatible with existing Confluent schema registry client applications.
- It includes client serializers/deserializers (Serdes) to validate Kafka and other message types at runtime.
- Operator-based installation of Apicurio Registry on OpenShift
- Use the concept of artifact group to collect schema and APIs logically related.
- Support search for artifacts by label, name, group, and description
When using Kafka as persistence, special Kafka topic <kafkastore.topic> (default _schemas), with a single partition, is used as a highly available write ahead log. All schemas, subject/version and ID metadata, and compatibility settings are appended as messages to this log. A Schema Registry instance therefore both produces and consumes messages under the _schemas topic. It produces messages to the log when, for example, new schemas are registered under a subject, or when updates to compatibility settings are registered. Schema Registry consumes from the _schemas log in a background thread, and updates its local caches on consumption of each new _schemas message to reflect the newly added schema or compatibility setting. Updating local state from the Kafka log in this manner ensures durability, ordering, and easy recoverability.
The way Event Streams / Apicur.io has to handle schema association to topics is by schema name. Given we have a topic called orders, the schemas that will apply to it are avros-key (when using composite key) and orders-value (most likely based on cloudevents and then custom payload).
Apache Avro¶
Avro is an open source data serialization system that helps with data exchange between systems, programming languages, and processing frameworks. Avro helps define a binary format for your data, as well as map it to the programming language of your choice.
Why Apache Avro¶
There are several websites that discuss the Apache Avro data serialization system benefits over other messaging data protocols. A simple google search will list dozens of them. Here, we will highlight just a few from a Confluent blog post:
- It has a direct mapping to and from JSON
- It has a very compact format. The bulk of JSON, repeating every field name with every single record, is what makes JSON inefficient for high-volume usage.
- It is very fast.
- It has great bindings for a wide variety of programming languages so you can generate Java objects that make working with event data easier, but it does not require code generation so tools can be written generically for any data stream.
- It has a rich, extensible schema language defined in pure JSON
- It has the best notion of compatibility for evolving your data over time.
Data Schemas¶
Avro relies on schemas. When Avro data is produced or read, the Avro schema for such piece of data is always present. This permits each datum to be written with no per-value overheads, making serialization both fast and small. An Avro schema defines the structure of the Avro data format.
How does a data schema look like?¶
Let's see how a data schema to define a person's profile in a bank could look like:
{
"namespace": "banking.schemas.demo",
"name": "profile",
"type": "record",
"doc": "Data schema to represent a profile for a banking entity",
"fields ": [
{
"name": "name",
"type": "string"
},
{
"name": "surname",
"type": "string"
},
{
"name": "age",
"type": "int"
},
{
"name": "account",
"type": "banking.schemas.demo.account"
},
{
"name": "gender",
"type": {
"type": "enum",
"name": "genderEnum",
"symbols": [
"male",
"female"
]
}
}
]
}
Notice:
- There are primitive data types like
stringandintbut also complex types likerecordorenum. - Complex type
recordrequires anameattribute but it also can go along with anamespaceattribute which is a JSON string that qualifies the name. - Data schemas can be nested as you can see for the
accountdata attribute. See below.
{
"namespace": "banking.schemas.demo",
"name": "account",
"type": "record",
"doc": "Data schema to represent a customer account with the credit cards associated to it",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "savings",
"type": "long"
},
{
"name": "cards",
"type": {
"type": "array",
"items": "int"
}
}
]
}
In the picture below we see two messages, one complies with the above Apache Avro data schema and the other does not:

You might start realising by now the benefits of having the data flowing into your Apache Kafka event backbone validated against a schema. See next section for more.
For more information on the Apache Avro Data Schema specification see https://avro.apache.org/docs/current/spec.html
Benefits of using Data Schemas¶
- Clarity and Semantics: They document the usage of the event and the meaning of each field in the "doc" fields.
- Robustness: They protect downstream data consumers from malformed data, as only valid data will be permitted in the topic. They let the producers or consumers of data streams know the right fields are need in an event and what type each field is (contract for microservices).
- Compatibility: model and handle change in data format.
Avro, Kafka and Schema Registry¶
In this section we try to put all the pieces together for the common flow of sending and receiving messages through an event backbone such as kafka having those messages serialized using the Apache Avro data serialization system and complying with their respective messages that are stored and managed by a schema registry.
Avro relies on schemas. When Avro data is produced or read, the Avro schema for such piece of data is always present. An Avro schema defines the structure of the Avro data format. Schema Registry defines a scope in which schemas can evolve, and that scope is the subject. The name of the subject depends on the configured subject name strategy, which by default is set to derive subject name from topic name.
In this case, the messages are serialized using Avro and sent to a kafka topic. Each message is a key-value pair. Either the message key or the message value, or both, can be serialized as Avro. Integration with Schema Registry means that Kafka messages do not need to be written with the entire Avro schema. Instead, Kafka messages are written with the schema id. The producers writing the messages and the consumers reading the messages must be using the same Schema Registry to get the same mapping between a schema and schema id.
More reading¶
Articles and product documentation¶
- IBM Event Streams- Schemas overview
- Apicur.io schema registry documentation
- Confluent schema registry overview
- Producer code with reactive messaging and apicurio schema registry
- Consumer code with reactive messaging and apicurio schema registry
Labs¶
We have developed two labs, one for the IBM Event Streams product that comes with the IBM CloudPak for Integration installed on a RedHat OpenShift cluster and the other for the IBM Event Streams on IBM Cloud offering, to get hands-on experience working with Apache Avro, data schemas and the IBM Event Streams Schema Registry: