Command-Query Responsibility Segregation (CQRS)¶
Problems and Constraints¶
A domain model encapsulates domain data with the behavior for maintaining the correctness of that data as it is modified, structuring the data based on how it is stored in the database and to facilitate managing the data. Multiple clients can independently update the data concurrently. Different clients may not use the data the way the domain model structures it, and may not agree with each other on how it should be structured.
When a domain model becomes overburdened managing complex aggregate objects, concurrent updates, and numerous cross-cutting views, how can it be refactored to separate different aspects of how the data is used?
An application accesses data both to read and to modify it. The primitive data tasks are often expressed as create, read, update, and delete (CRUD); using them is known as CRUDing the data. Application code often does not make much distinction between the tasks; individual operations may mix reading the data with changing the data as needed.
This simple approach works well when all clients of the data can use the same structure and contention is low. A single domain model can manage the data, make it accessible as domain objects, and ensure updates maintain its consistency. However, this approach becomes inadaquate when different clients want different views across multiple sets of data, when the data is too widely used, and/or when multiple clients updating the data my unknowlingly conflict with each other.
For example, in a microservices architecture, each microservice should store and manage its own data, but a user interface may need to display data from several microservices. A query that gathers bits of data from multiple sources can be inefficient (time and bandwidth consumed accessing multiple data sources, CPU consumed transforming data, memory consumed by intermediate objects) and must be repeated each time the data is accessed.
Another example is an enterprise database of record managing data required by multiple applications. It can become overloaded with too many clients needing too many connections to run too many threads performing too many transactions--such that the database becomes a performance bottleneck and can even crash.
Another example is maintaining consistency of the data while clients concurrently make independent updates to the data. While each update may be consistent, they may conflict with each other. Database locking ensures that the updates don't change the same data concurrently, but doesn't ensure multiple independent changes result in a consistent data model.
When data usage is more complex than a single domain model can facilitate, a more sophisticated approach is needed.
Solution and Pattern¶
Refactor a domain model to separate operations for querying data and operations for updating data so that they may be handled independently.
The CQRS pattern strictly segregates operations that read data from operations that update data. An operation can read data (the R in CRUD) or can write data (the CUD in CRUD), but not both.
This separation can make using data much more manageable in several respects. The read operations and the write operations are simpler to implement because their functionality is more finely focused. The operations can be developed independently, potentially by separate teams. The operations can be optimized independently and can evolve independently, following changing user requirements more easily. These optimized operations can scale better, perform better, and security can be applied more precisely.
The full CQRS pattern uses separate read and write databases. In doing so, the pattern segregates not just the APIs for accessing data or the models for managing data, but even segregates the database itself into two, a read/write database that is effectively write-only and one or more read-only databases.
The adoption of the pattern can be applied in phases, incrementally from existing code. To illustrate this, we will use four stages that could be used incrementally or a developer can go directly from stage 0 to 3 without considering the others:
- Stage 0: Typical application data access
- Stage 1: Separate read and write APIs
- Stage 2: Separate read and write models
- Stage 3: Separate read and write databases
Typical application data access¶
Before even beginning to apply the pattern, let’s consider the typical app design for accessing data. This diagram shows an app with a domain model for accessing data persisted in a database of record, i.e. a single source of truth for that data. The domain model has an API that at a minimum enables clients to perform CRUD tasks on domain objects within the model.
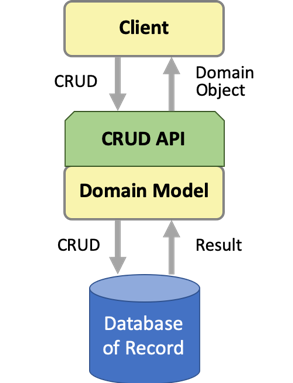
The domain model is an object representation of the database documents or records. It is comprised of domain objects that represent individual documents or records and the business logic for managing and using them. Domain-Driven Design (DDD) models these domain objects as entities—“objects that have a distinct identity that runs through time and different representations”—and aggregates—“a cluster of domain objects that can be treated as a single unit”; the aggregate root maintains the integrity of the aggregate as a whole.
Ideally, the domain model’s API should be more domain-specific than simply CRUDing of data. Instead, it should expose higher-level operations that represent business functionality like findCustomer(), placeOrder(), transferFunds(), and so on. These operations read and update data as needed, sometimes doing both in a single operation. They are correct as long as they fit the way the business works.
Separate read and write APIs¶
The first and most visible step in applying the CQRS pattern is splitting the CRUD API into separate read and write APIs. This diagram shows the same domain model as before, but its single CRUD API is split into retrieve and modify APIs.
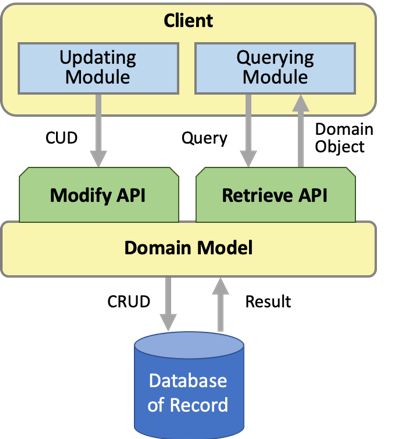
The two APIs share the existing domain model but split the behavior:
- Read: The retrieve API is used to read the existing state of the objects in the domain model without changing that state. The API treats the domain state as read only.
- Write: The modify API is used to change the objects in the domain model. Changes are made using CUD tasks: create new domain objects, update the state in existing ones, and delete ones that are no longer needed. The operations in this API do not return result values, they return success (ack or void) or failure (nak or throw an exception). The create operation might return the primary of key of the entity, which can be generated either by the domain model or in the data source.
This separation of APIs is an application of the Command Query Separation (CQS) pattern, which says to clearly separate methods that change state from those that don’t. To do so, each of an object’s methods can be in one of two categories (but not both):
- Query: Returns a result. Does not change the system’s state nor cause any side effects that change the state.
- Command (a.k.a. modifiers or mutators): Changes the state of a system. Does not return a value, just an indication of success or failure.
With this approach, the domain model works the same and provides access to the data the same as before. What has changed is the API for using the domain model. Whereas a higher-level operation might previously have both changed the state of the application and returned a part of that state, now each such operation is redesigned to only do one or the other.
When the domain model splits its API into read and write operations, clients using the API must likewise split their functionality into querying and updating functionality. Most new web based applications are based in the single page application, with components and services that use and encapsulate remote API. So this separation of backend API fits well with modern web applications.
This stage depends on the domain model being able to implement both the retrieve and modify APIs. A single domain model requires the retrieve and modify behavior to have similar, corresponding implementations. For them to evolve independently, the two APIs will need to be implemented with separate read and write models.
Separate read and write models¶
The second step in applying the CQRS pattern is to split the domain model into separate read and write models. This doesn’t just change the API for accessing domain functionality, it also changes the design of how that functionality is structured and implemented. This diagram shows that the domain model becomes the basis for a write model that handles changes to the domain objects, along with a separate read model used to access the state of the app.
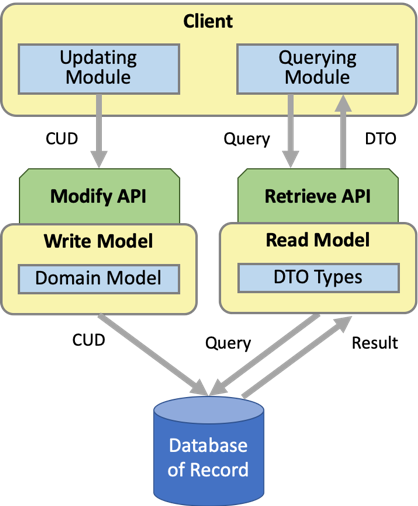
Naturally, the read model implements the retrieve API and the write model implements the modify API. Now, the application consists not only of separate APIs for querying and updating the domain objects, there’s also separate business functionality for doing so. Both the read business functionality and the write business functionality share the same database.
The write model is implemented by specializing the domain model to focus solely on maintaining the valid structure of domain objects when changing their state and by applying any business rules.
Meanwhile, responsibility for returning domain objects is shifted to a separate read model. The read model defines data transfer objects (DTOs) designed specifically for the model to return just the data the client wants in a structure the client finds convenient. The read model knows how to gather the data used to populate the DTOs. DTOs encapsulate little if any domain functionality, they just bundle data into a convenient package that can easily be transmitted using a single method call, especially between processes.
The read model should be able to implement the retrieve API by implementing the necessary queries and executing them. If the retrieve API is already built to return domain objects as results, the read model can continue to do so, or better yet, implements DTO types that are compatible with the domain objects and returns those. Likewise, the modify API was already implemented using the domain model, so the write model should preserve that. The write model may enhance the implementation to more explicitly implement a command interface or use command objects.
This phase assumes that the read and write models can both be implemented using the same database of record the domain model has been using. To the extent this is true, the implementations of reading and writing can evolve independently and be optimized independently. This independence may become increasingly limited since they are both bound to the same database with a single schema or data model. To enable the read and write models to evolve independently, they may each need their own database.
Separate read and write databases¶
The third step in applying the CQRS pattern—-which implements the complete CQRS pattern solution—-is splitting the database of record into separate read and write databases. This diagram shows the write model and read model, each supported by its own database. The overall solution consists of two main parts: the write solution that supports updating the data and the read solution that supports querying the data. The two parts are connected by the event bus.
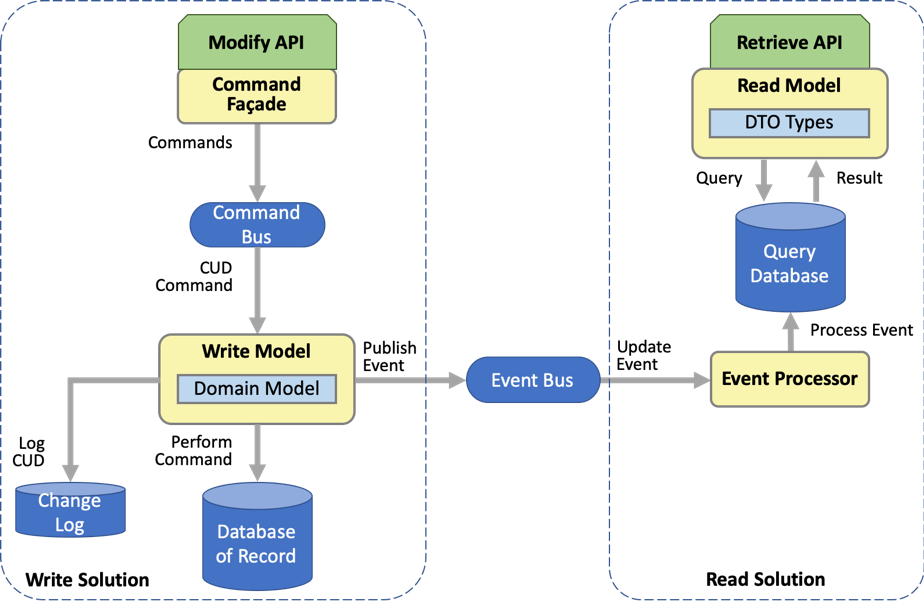
The write model has its own read/write database and the read model has its own read-only database. The read/write database still serves as the database of record (the single source of truth for the data) but is mostly used write-only: mostly written to and rarely read. Reading is offloaded onto a separate read database that contains the same data but is used read-only.
The query database is effectively a cache of the database of record, with all of the inherit benefits and complexity of the Caching pattern. The query database contains a copy of the data in the database of record, with the copy structured and staged for easier access by the clients using the retrieve API. As a copy, overhead is needed to keep the copy synchronized with changes in the original. Latency in this synchronization process creates eventual consistency, during which the data copy is stale.
The separate databases enable the separate read and write models and their respective retrieve and modify APIs to truly evolve independently. Not only can the read model or write model’s implementation change without changing the other, but how each stores its data can be changed independently.
This solution offers the following advantages:
- Scaling: The query load is moved from the write database to the read database. If the database of record is a scalability bottleneck and a lot of the load on it is caused by queries, unloading those query responsibilities can significantly improve the scalability of the combined data access.
- Performance: The schemas of the two databases can be different, enabling them to be designed and optimized independently for better performance. The write database can be optimized for data consistency and correctness, with capabilities such as stored procedures that fit the write model and assist with data updates. The read database can store the data in units that better fit the read model and are better optimized for querying, with larger rows requiring fewer joins.
Notice that the design for this stage is significantly more complex than the design for the previous stage. Separate databases with copies of the same data may make data modeling and using data easier, but they require significant overhead to synchronize the data and keep the copies consistent.
CQRS employs a couple of design features that support keeping the databases synchronized:
- Command Bus for queuing commands (optional): A more subtle and optional design decision is to queue the commands produced by the modify API, shown in the diagram as the command bus. This can significantly increase the throughput of multiple apps updating the database, as well as serialize updates to help avoid--or at least detect--merge conflicts. With the bus, a client making an update does not block synchronously while the change is written to the database. Rather, the request to change the database is captured as a command (Design Patterns) and put on a message queue, after which the client can proceed with other work. Asynchronously in the background, the write model processes the commands at the maximum sustainable rate that the database can handle, without the database ever becoming overloaded. If the database becomes temporarily unavailable, the commands queue and will be processed when the database becomes available once more.
- Event Bus for publishing update events (required): Whenever the write database is updated, a change notification is published as an event on the event bus. Interested parties can subscribe to the event bus to be notified when the database is updated. One such party is an event processor for the query database, which receives update events and processes them by updating the query database accordingly. In this way, every time the write database is updated, a corresponding update is made to the read database to keep it in sync.
The connection between the command bus and the event bus is facilitated by an application of the Event Sourcing pattern, which keeps a change log that is suitable for publishing. Event sourcing maintains not only the current state of the data but also the history of how that current state was reached. For each command on the command bus, the write model performs these tasks to process the command:
- Logs the change
- Updates the database with the change
- Creates an update event describing the change and publishes it to the event bus
The changes that are logged can be the commands from the command bus or the update events published to the event bus
Considerations¶
Keep these decisions in mind while applying this pattern:
- Client impact: Applying CQRS not only changes how data is stored and accessed, but also changes the APIs that clients use to access data. This means that each client must be redesigned to use the new APIs.
- Riskiness: A lot of the complexity of the pattern solution involves duplicating the data in two databases and keeping them synchronized. Risk comes from querying data that is stale or downright wrong because of problems with the synchronization.
- Eventual consistency: Clients querying data must expect that updates will have latency. In a microservices architecture, eventual data consistency is a given and acceptable in many of cases.
- Command queuing: Using a command bus as part of the write solution to queue the commands is optional but powerful. In addition to the benefits of queuing, the command objects can easily be stored in the change log and easily be converted into notification events. (In the next section, we illustrate a way to use event bus to queue commands as well.)
- Change log: The log of changes to the database of record can be either the list of commands from the command bus or the list of event notifications published on the event bus. The Event Sourcing pattern assumes it’s a log of events, but that pattern doesn’t include the command bus. An event list may be easier to scan as a history, whereas a command list is easier to replay.
- Create keys: Strick interpretation of the Command Query Separation (CQS) pattern says that command operations do not have return types. A possible exception is commands that create data: An operation that creates a new record or document typically returns the key for accessing the new data, which is convenient for the client. However, if the create operation is invoked asynchronously by a command on a command bus, the write model will need to perform a callback on the client to return the key.
- Messaging queues and topics: While messaging is used to implement both the command bus and event bus, the two busses use messaging differently. The command bus guarantees exactly once delivery. The event bus broadcasts each event to all interested event processors.
- Query database persistence: The database of record is always persistent. The query database is a cache that can be a persistent cache or an in-memory cache. If the cache is in-memory and is lost, it must be rebuilt completely from the database of record.
- Security: Controls on reading data and updating data can be applied separately using the two parts of the solution.
Combining event sourcing and CQRS¶
The CQRS application pattern is frequently associated with event sourcing: when doing event sourcing and domain driven design, we event source the aggregates or root entities. Aggregate creates events that are persisted. On top of the simple create, update and read by ID operations, the business requirements want to perform complex queries that can't be answered by a single aggregate. By just using event sourcing to be able to respond to a query like "what are the orders of a customer", then we have to rebuild the history of all orders and filter per customer. It is a lot of computation. This is linked to the problem of having conflicting domain models between query and persistence.
As introduced in previous section, creations and updates are done as state notification events (change of state), and are persisted in the event log/store. The following figure, presents two separate microservices, one supporting the write model, and multiple other supporting the queries:
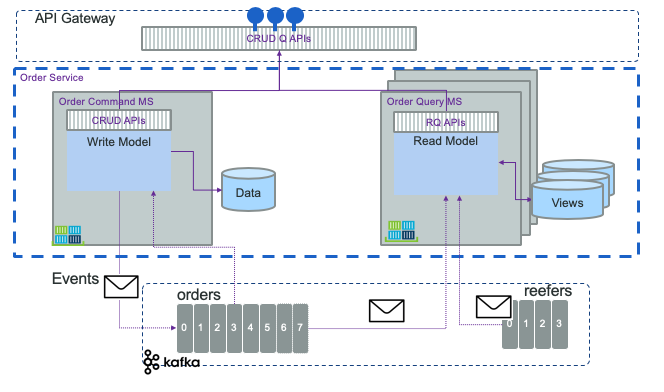
The query part is separate processes that consume change log events and build a projection for future queries. The "write" part may persist in SQL while the read may use document oriented database with strong indexing and query capabilities. Or use in-memory database, or distributed cache... They do not need to be in the same language. With CQRS and ES the projections are retroactives. New query equals implementing new projection and read the events from the beginning of time or the recent committed state and snapshot. Read and write models are strongly decoupled and can evolve independently. It is important to note that the 'Command' part can still handle simple queries, primary-key based, like get order by id, or queries that do not involve joins.
The event backbone, use a pub/sub model, and Kafka is a good candidate as an implementation technology.
With this structure, the Read model microservice will most likely consume events from multiple topics to build the data projection based on joining those data streams. A query, to assess if the cold-chain was respected on the fresh food order shipment, will go to the voyage, container metrics, and order to be able to answer this question. This is where CQRS shines.
We can note that, we can separate the API definition and management in a API gateway.
The shipment order microservice is implementing this pattern.
Some implementation items to consider:
- Consistency (ensure the data constraints are respected for each data transaction): CQRS without event sourcing has the same consistency guarantees as the database used to persist data and events. With Event Sourcing the consistency could be different, one for the write model and one for the read model. On write model, strong consistency is important to ensure the current state of the system is correct, so it leverages transaction, lock and sharding. On read side, we need less consistency, as they mostly work on stale data. Locking data on the read operation is not reasonable.
- Scalability: Separating read and write as two different microservices allows for high availability. Caching at the read level can be used to increase performance response time, and can be deployed as multiple standalone instances (Pods in Kubernetes). It is also possible to separate the query implementations between different services. Functions as service / serverless are good technology choices to implement complex queries.
- Availability: The write model sacrafices consistency for availability. This is a fact. The read model is eventually consistent so high availability is possible. In case of failure the system disables the writing of data but still is able to read them as they are served by different databases and services.
With CQRS, the write model can evolve over time without impacting the read model, as long as the event model doesn't change. The read model requires additional tables, but they are often simpler and easier to understand.
CQRS results in an increased number of objects, with commands, operations, events,... and packaging in deployable components or containers. It adds potentially different type of data sources. It is more complex.
Some challenges to always consider:
- How to support event structure version management?
- How much data to keep in the event store (history)?
- How to adopt data duplication which results to eventual data consistency?.
The CQRS pattern was introduced by Greg Young, and described in Martin Fowler's work on microservices.
As you can see in previous figure, as soon as we see two arrows from the same component, we have to ask ourselves how does it work: the write model has to persist Order in its own database and then sends OrderCreated event to the topic... Should those operations be atomic and controlled with transaction? We detail this in next section.
Keeping the write model on Mainframe¶
It is very important to note that the system of records and transaction processing is still easier to run on mainframe to support strong consistency. But with the move to cloud native development, it does not mean we have to move all the system of records to the cloud. Data pipelines can be put in place, but CQRS should help by keeping the write model on the current system of records and without impacting the current MIPS utilization move data in the eventual consistency workd of the cloud native, distributed computing world.
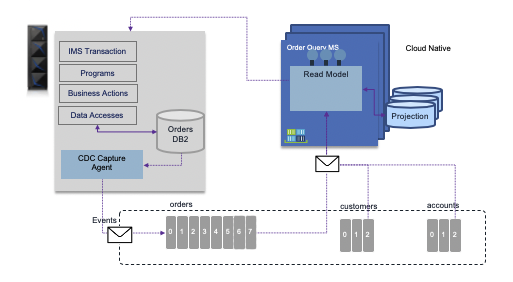
In the figure above, the write model follows the current transaction processing on the mainframce, change data capture push data to Event backbone for getting real time visibility into the distributed world. The read is the costly operation, dues to the joins to be done to build the projection views needed to expose data depending of the business use cases. This is more true with distributed microservices. All the write operations for the business entities kept in the mainframe's system of records are still done via the transaction. Reference data can be injected in one load job to topic and persisted in the event store so streaming applications can leverage them by joining with transactional data.
The consistency challenges¶
As introduced in the previous section, there is a potential problem of data inconsistency: once a command saves changes into the database, the consumers do not see the new or updated data until event notification completes processing.
With traditional Java service, using JPA and JMS, the save and send operations can be part of the same XA transaction and both succeed or fail.
With event sourcing pattern, the source of trust is the event source, which acts as a version control system, as shown in the diagram below.
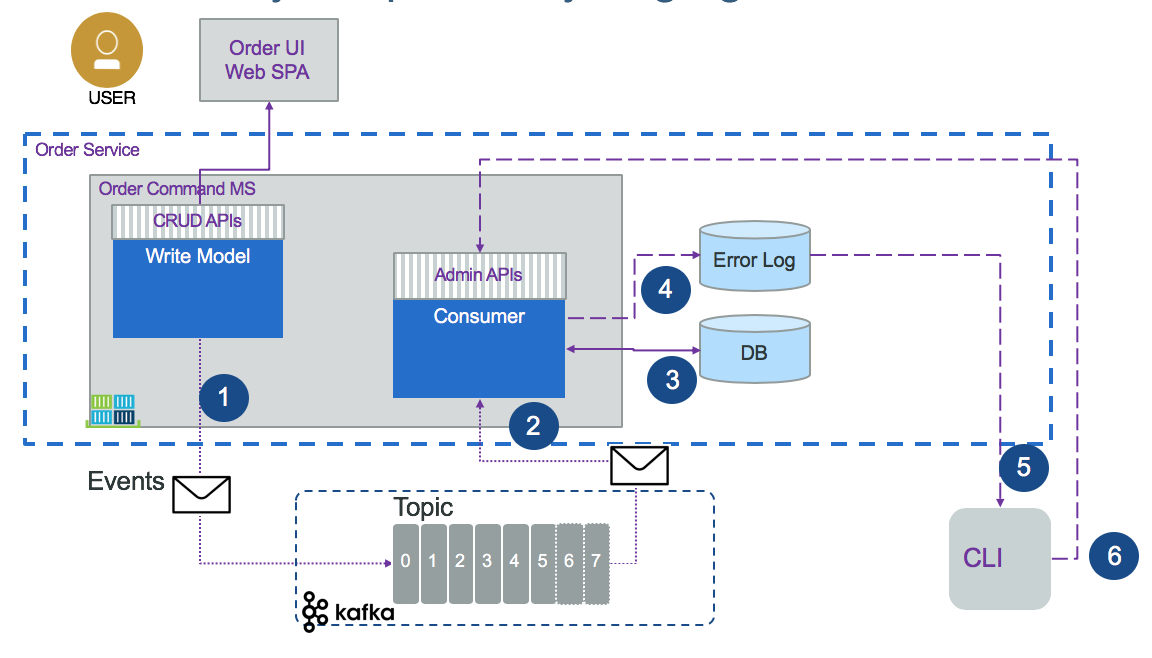
The steps for syncronizing changes to the data are:
- The write model creates the event and publishes it
- The consumer receives the event and extracts its payload
- The consumer updates its local datasource with the payload data
- If the consumer fails to process the update, it can persist the event to an error log
- Each error in the log can be replayed
- A command line interface replays an event via an admin API, which searches in the topic using this order id to replay the save operation
This implementation causes a problem for the createOrder(order): string operation: The Order Service is supposed to return the new order complete with the order id that is a unique key, a key most likely created by the database. If updating the database fails, there is no new order yet and so no database key to use as the order ID. To avoid this problem, if the underlying technology supports assigning the new order's key, the service can generate the order ID and use that as the order's key in the database.
It is important to clearly study the Kafka consumer API and the different parameters on how to support the read offset. We are addressing those implementation best practices in our consumer note.
CQRS and Change Data Capture¶
There are other ways to support this dual operations level:
- When using Kafka, Kafka Connect has the capability to subscribe to databases via JDBC, allowing to poll tables for updates and then produce events to Kafka.
- There is an open-source change data capture solution based on extracting change events from database transaction logs, Debezium that helps to respond to insert, update and delete operations on databases and generate events accordingly. It supports databases like MySQL, Postgres, MongoDB and others.
- Write the order to the database and in the same transaction write to an event table ("outbox pattern"). Then use a polling to get the events to send to Kafka from this event table and delete the row in the table once the event is sent.
- Use the Change Data Capture from the database transaction log and generate events from this log. The IBM Infosphere CDC product helps to implement this pattern. For more detail about this solution see this product tour.
The CQRS implementation using CDC will look like in the following diagram:
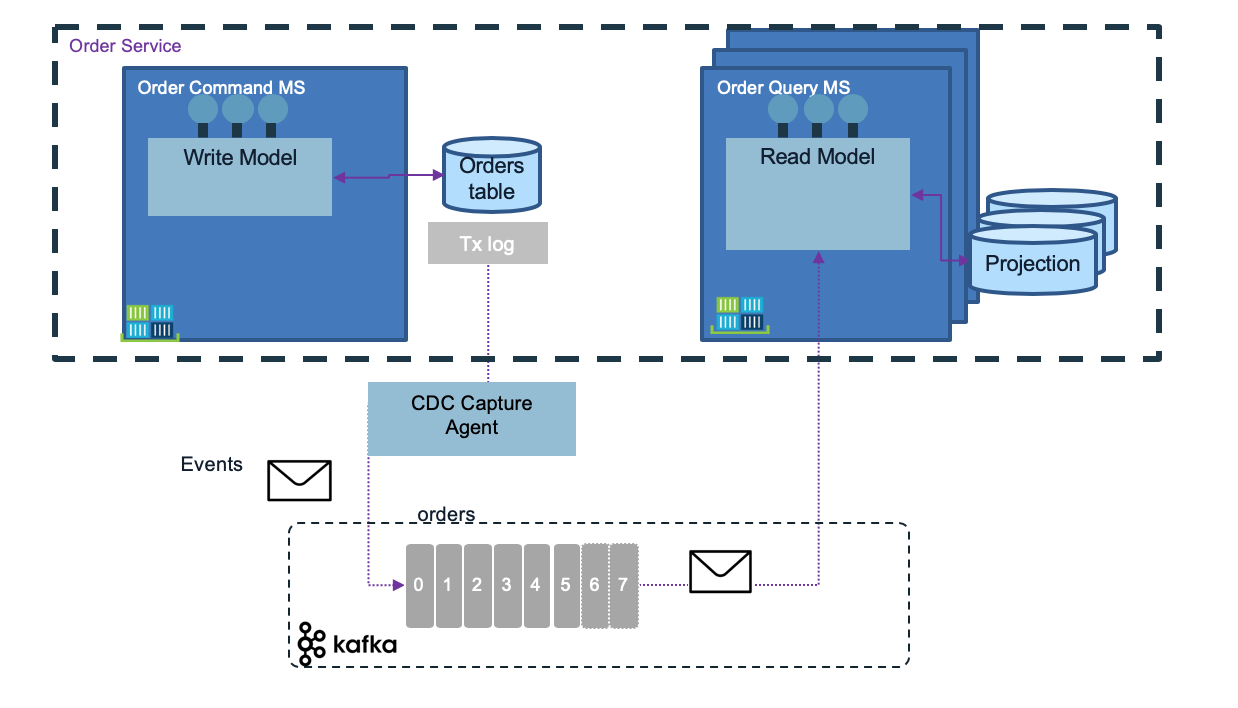
What is important to note is that the event needs to be flexible on the data payload. We are presenting a event model in the reference implementation.
On the view side, updates to the view part need to be idempotent.
Delay in the view¶
There is a delay between the data persistence and the availability of the data in the Read model. For most business applications, it is perfectly acceptable. In web based data access most of the data are at stale.
When there is a need for the client, calling the query operation, to know if the data is up-to-date, the service can define a versioning strategy. When the order data was entered in a form within a single page application like our kc- user interface, the "create order" operation should return the order with its unique key freshly created and the Single Page Application will have the last data. Here is an example of such operation:
@POST
public Response create(OrderCreate dto) {
Order order = new Order(UUID.randomUUID().toString(), dto.getProductID(),...);
// ...
return Response.ok().entity(order).build()
}
Schema change¶
What to do when we need to add attribute to event?. So we need to create a versioninig schema for event structure. You need to use flexible schema like json schema, Apache Avro or protocol buffer and may be, add an event adapter (as a function?) to translate between the different event structures.
Code reference¶
- The following project includes two sub modules, each deployable as a microservice to illustrate the command and query part: https://github.com/ibm-cloud-architecture/refarch-kc-order-ms
Further readings
- https://www.codeproject.com/Articles/555855/Introduction-to-CQRS
- http://udidahan.com/2009/12/09/clarified-cqrs
- https://martinfowler.com/bliki/CQRS.html
- https://microservices.io/patterns/data/cqrs.html
- https://community.risingstack.com/when-to-use-cqrs
- https://dzone.com/articles/concepts-of-cqrs
- https://martinfowler.com/bliki/CommandQuerySeparation.html
- https://www.martinfowler.com/eaaCatalog/domainModel.html
- https://dddcommunity.org/learning-ddd/what_is_ddd/
- https://martinfowler.com/bliki/EvansClassification.html
- https://martinfowler.com/bliki/DDD_Aggregate.html
- https://martinfowler.com/eaaCatalog/dataTransferObject.html
- https://en.wikipedia.org/wiki/Command_pattern
- https://www.pearson.com/us/higher-education/program/Gamma-Design-Patterns-Elements-of-Reusable-Object-Oriented-Software/PGM14333.html