Data lineage
From a stream data platform adoption point of view, we have multiple components working on data, with online and offline processing. The following figure illustrates the concepts and components we may need to consider as part of the data lineage discussion:
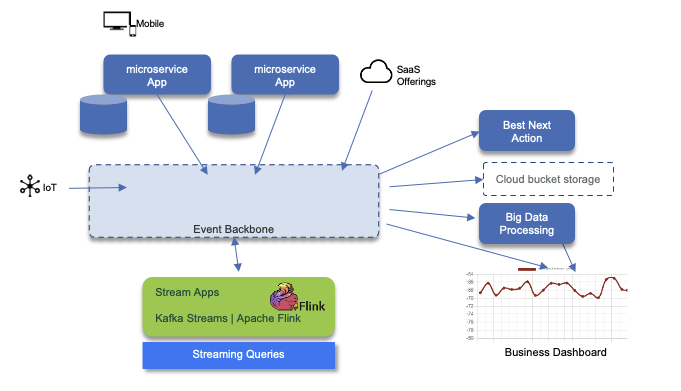
- Mobile, web single page application, IoT, microservice app, change data capture (not presented here) and SaaS offering applications are source of events. Event backbone persists those events in append log with long retention time (days).
- Stream applications are running statefule operations to compute real time analytics or doing complex event processing. Kafka Streams and Apache Flinks are the technology of choices.
- On the right side, consumer can trigger what will be the next best action to perform on a specific event. Those action can be a business process, a product recommendations, an alert...
- Often data can be persisted on a longer retention storage, with full cloud availability like S3 buckets (Cloud Object storage on IBM Cloud or on Premise).
- Big data processing plaform like Sparks can run batch processing, map reduce type, on data at rest, that comes from the data ingestion layer supported but the event backbone.
- Finally business dashboard can integrate queries on data at rest and in motion via interactive / streaming queries.
With those simple component view we can already see data lineage will be complex, so we need practices and tools to support it. As more data is injected into the data platform, the more you need to be able to answer a set of questions like:
- Where the data is coming from
- Who create the data
- Who own it
- Who can access those data and where
- How can we ensure data quality
- Who modify data in motion
Data lineage requirements¶
Data lineage describes data origins, movements, characteristics, ownership and quality. As part of larger data governance initiative, it may encompass data security, access control, encryption and confidentiality.
Contracts¶
In the REST APIs, or even SOA, worlds request/response are defined via standards like OpenAPI or WSDL. In the event and streaming processing the AsynchAPI is the specification to define schema and middleware binding.
OpenAPI¶
We do not need to present OpenAPI but just the fact that those APIs represent request/response communication and may be managed and integrated with the development life cycle. Modern API management platform should support their life cycle end to end but also support new specifications like GraphQL and AsynchAPI.
AsynchAPI¶
Without duplicating the specification is the specification to define schema and middleware binding. we want to highlight here what are the important parts to consider in the data goverance:
- The Asynch API documentation which includes:
- The server definition to address the broker binding, with URL and protocol to be used. (http, kafka, mqtt, amqp, ws)
- The channel definition which represents how to reach the brokers. It looks like a Path definition in OpenAPI
- The message definition which could be of any value. Apache Avro is one way to present message but it does not have to be.
- Security to access the server via user / password, TLS certificates, API keys, OAuth2...
- The message schema
The format of the file describing the API can be Yaml or Json.
Schema¶
Schema is an important way to ensure data quality by defining a strong, but flexible, contract between producers and consumers and to understand the exposed payload in each topics. Schema definitions improve applications robustness as downstream data consumers are protected from malformed data, as only valid data will be permitted in the topic. Schemas need to be compatible from version to version and Apache Avro supports defining default values for non existing attribute of previous versioned schema. Schema Registry enforces full compatibility when creating a new version of a schema. Full compatibility means that old data can be read with the new data schema, and new data can also be read with a previous data schema.
Here is an example of such definition:
Remarks: if you want backward compatibility, being able to read old messages, you need to add new fields with default value.To support forward compatibility you need to add default value to deleted field, and if you want full compatibility you need to add default value on all fields.Metadata about the event can be added as part of the field definition, and should include source application reference, may be a unique identifier created at the source application to ensure traceability end to end, and when intermediate streaming application are doing transformation on the same topic, the transformer app reference. Here is an example of such data:
"fields": [
{ "name": "metadata",
"type": {
"name": "Metadata",
"type": "record",
"fields": [
{"name": "sourceApp", "type": "string"},
{"name": "eventUUID", "type": "string"},
{"name": "transformApps", "type":
{ "name" : "TransformerReference",
"type": "array",
"items": "string"
}
}
]
}
}
]
The classical integration with schema registry is presented in the figure below:
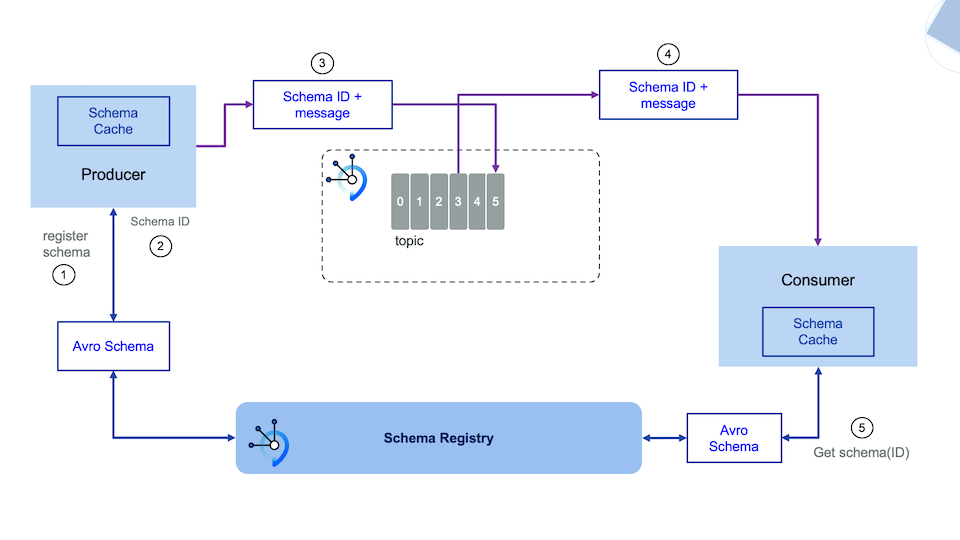
Schema registry can be deployed in different data centers and serves multi Kafka clusters. For DR, you need to use a 'primary' server and one secondary in different data center. Both will receive schema update via DevOps pipeline. One of the main open source Schema Registry is Apicurio, which is integrated with Event Streams and in most of our implementation. Apicurio can persist schema definition inside Kafka Topic and so schema replication can also being synchronize via Mirror Maker 2 replication. If Postgresql is used for persistence then postgresql can be used for replicating schemas.
We recommend reading our schema registry summary and our OpenShift lab or Event Streams on Cloud schema registry lab.
Integrating schema management with code generation and devOps pipeline is addressed in this repository.