Service mesh
Updated 06/18/2022
In this note we are grouping the studies around microservice to microservice communication with Kubernetes deployment. We are addressing:
- how ingress controller helps inside Kubernetes
- how API gateway helps for API management and service integration
- how to expose service in hybrid cloud
- how to discover service
All come back to the requirements, skill set and fit to purpose.
Definitions¶
Service meshes provide visibility, resiliency, traffic, and security control of distributed application services. They deliver policy-based networking for microservices in the contraints of virtual network and continuous topology updates. Externalizing, via declarations, the logic to support network potential issues, like resiliency, simplifies dramatically developers work.
Some misconception to clarify around microservice and APIs:
- microservices are not fine grained web services
- APIs are not equivalent to microservices
- microservices implement APIs in the scope of their domain. Separation between queries and commands may lead to two different services so the APIs will be splitted.
- microservice implements business logic
API is an interface, a way to make a request to get or change data in an application. In modern use API refers to REST web APIs using HTTP protocol, with JSON format (sometime XML is still used). Interface decouples the caller from the implementation. The caller has no idea how API is implemented.
A microservice is in fact a component. Micro refers to the granularity of the component not of the exposed interface. The following diagram illustrates all those concepts.
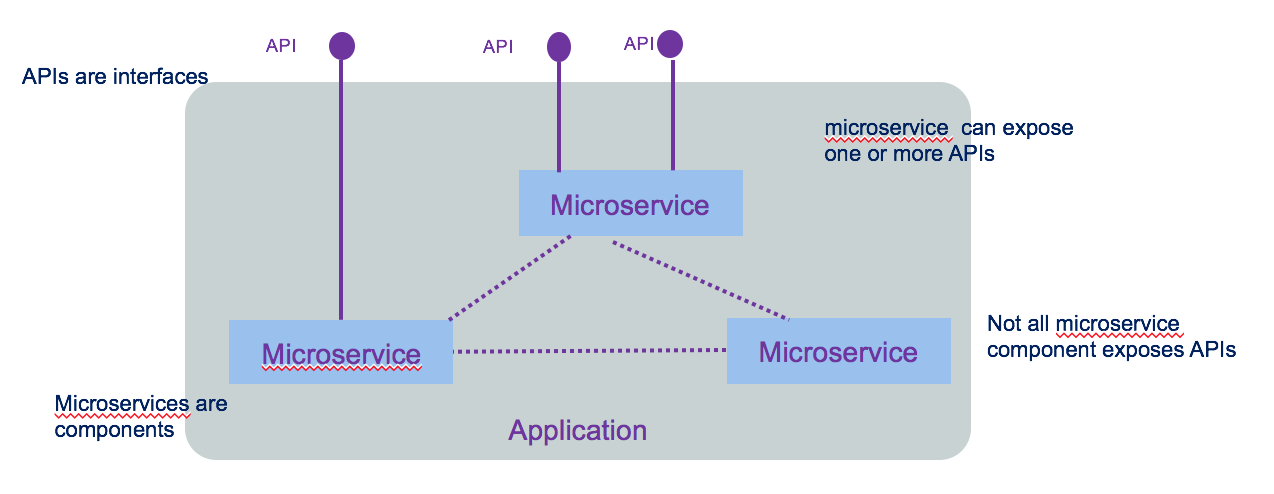
We encourage you to go to read integration design and architecture series.
Container orchestration like Kubernetes are mainly doing application scheduling, cluster management, resource provisioning, platform and workload monitoring and service discovery.
When application solutions are growing in size and complexity, you need to addres the following subjects:
- visibility on how traffic is flowing between microservices, how routing is done between microservices based on requests content or the origination point or the end point
- how to support resiliency by handling failure in a graceful manner
- how to ensure security with identity assertion
- how to enforce security policy
Addressing those subjects help defining the requirements for service mesh.
Service mesh architecture defines a data and control planes:
- Control plane: supports policy and configuration for services in the mesh, and provides aggregation for telemetry. It has API and CLI to centralize control to the services deployed. In Kubernetes control planes are deployed in a system namespace.
- Data plane: handles the actual inspection, transit, and routing of network traffic. It is responsible for health checking, load balancing, authentication, authorization, inbound (ingress) and outbound (egress) cluster network traffic.
Applications / microservices are unaware of data plane.
Context¶
Traditional modern architecture involves having different components exposing reusable APIs, addressing different channels (mobile, single page application, traditional server pages or B2B apps), consuming APIs (mobile APIs, back end for front end, shared common apis like authentication, authorization,...) and backend services addressing reusable business services:
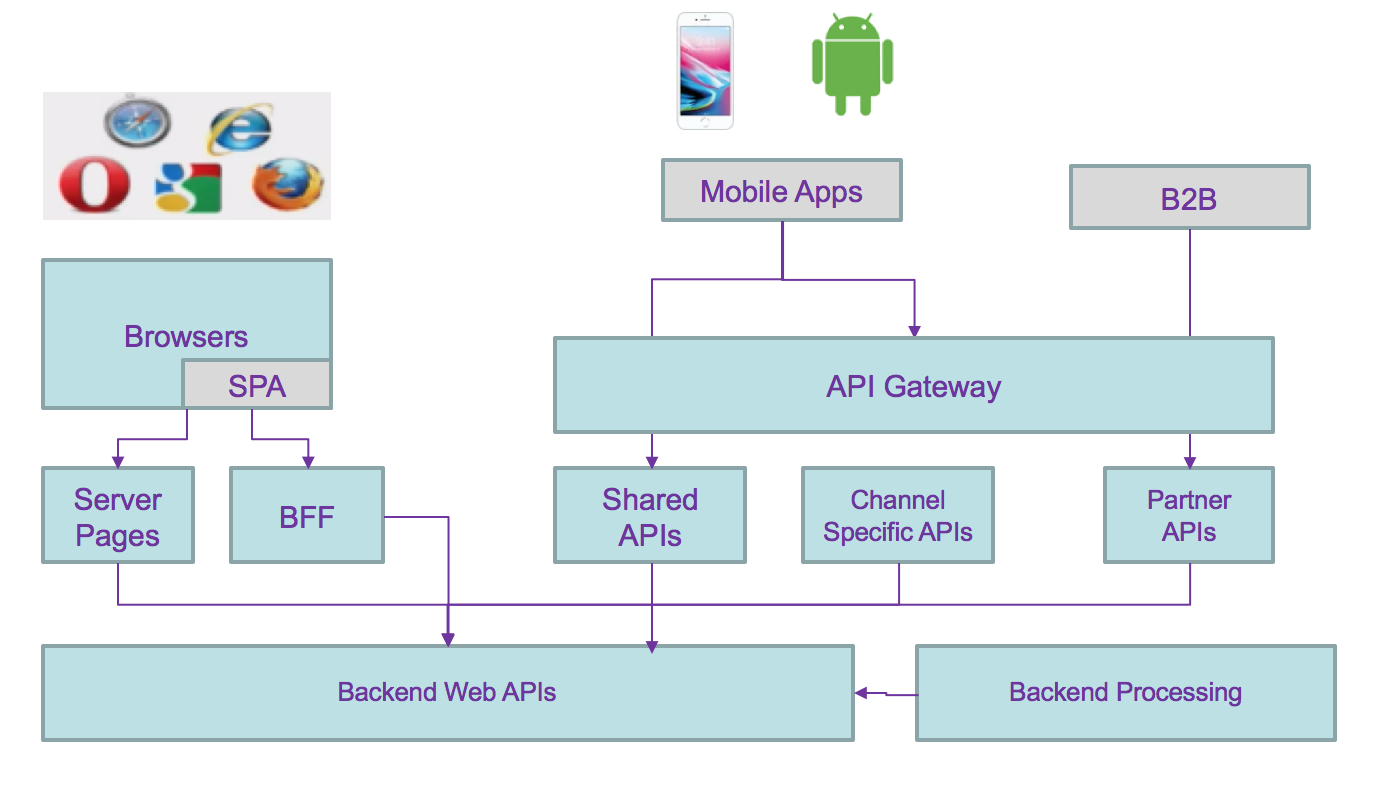
API management can be added via API gateway. This is a distributed application with cross related communication channels, where any changes to the service interface characteristics impact any of the components.
Moving to microservices architecture style adds more communication challenges and DevOps complexity but provides a lot of business values such as:
- rapid deployment of new business capabilities, co-evolving in parallel of other services.
- focusing on business domain with clear ownership of the business function and feature roadmap
- better operation procedure, automated, and with easy rollout and continuous delivery.
- A/B testing to assess how new feature deployed improve business operations
- improve resiliency by deploying on multi language cluster
As an example we can use the a classical web application with the following capabilities:
- user authentication
- user management: add / delete new user
- user self registration, reset password
- user permission control
- user profile
- asset management
- risk assessment service
Each capability could be grouped by business domain like the user management, asset management, and application access control. So domain separation can be a good microservice boundary. This is the Domain Driven Design Bounded context construct. But if the number of user reach millions then we may need to optimize the runtime processing of reading user credential, and scale the service differently, leading to a service map like the diagram below, where runtime and management are separated services.
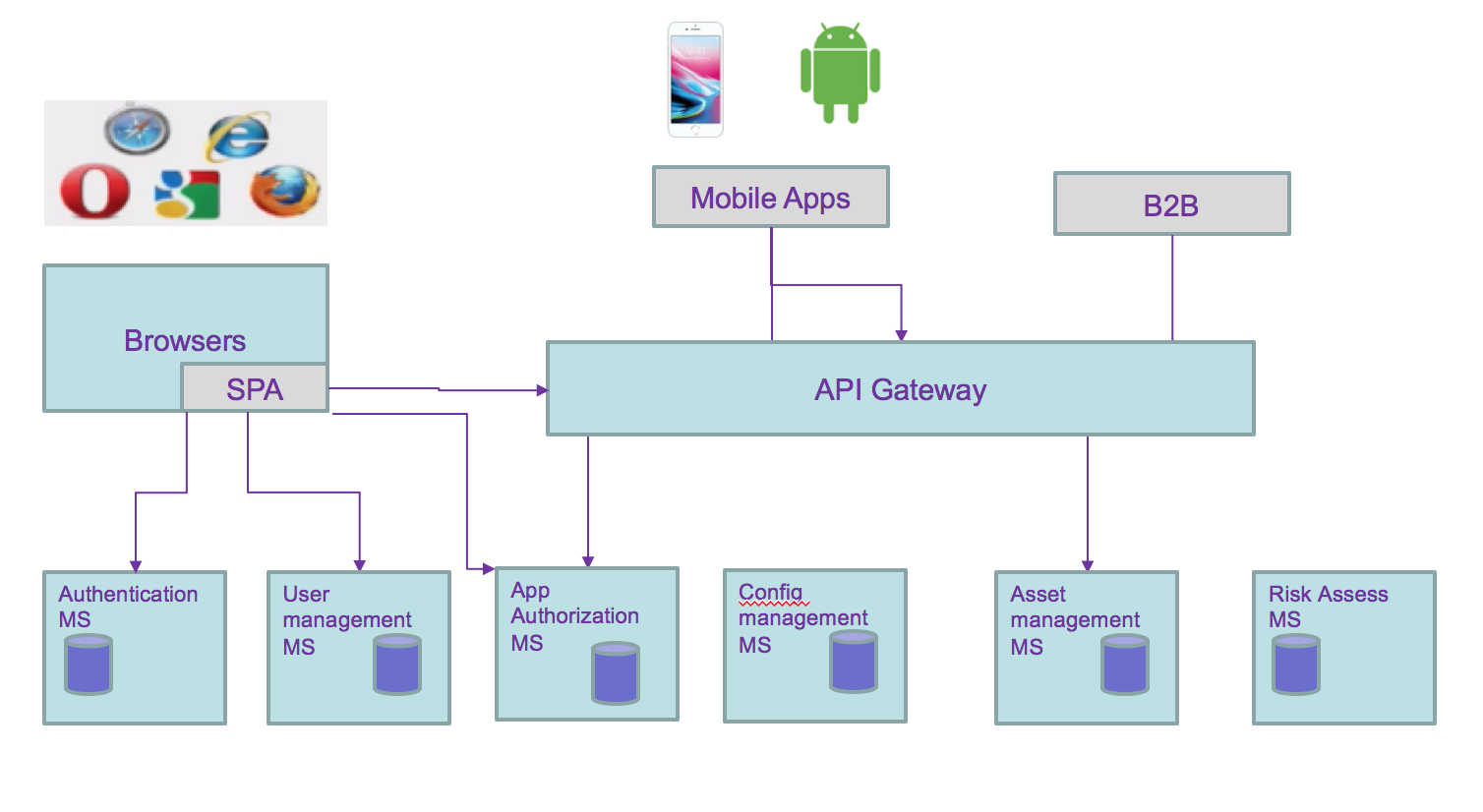
All of these still does not address the fact that data are distributed and even more with microservices owning their data persistence. As developers and architects, we still have to address the following data integrity problems:
- two phases commit
- compensating operation
- eventual data consistency: some microservice updating data may share those updates with other microservices.
- data aggregation: adding new views on data, owned by a microservice, to support new aggregates. Examples are preparing data view for machine learning modeling, analytics, or business intelligence...
From the previous microservice allocation we can see the needs to propagate data update between services. Adding or unsubscribing a user involves updating the asset the user owns and the authentication runtime service:
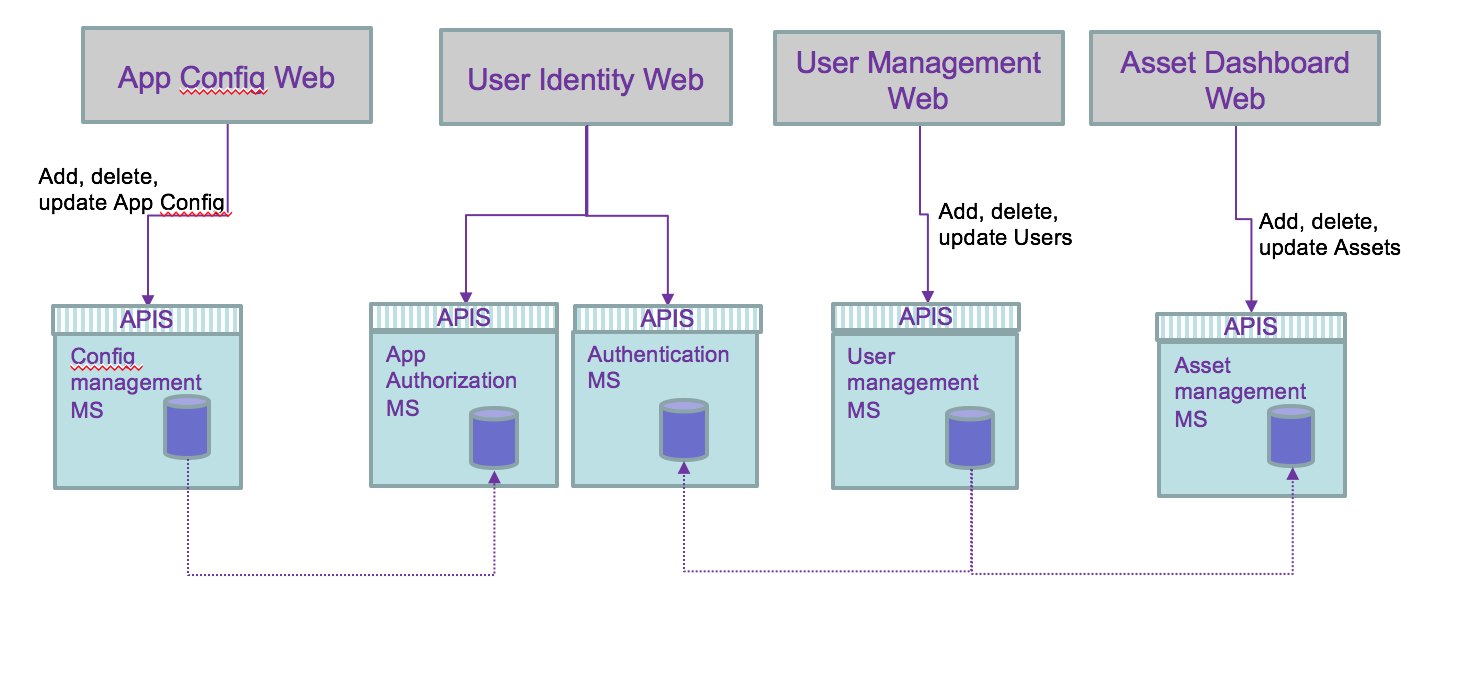
Adding a new application changes the authorization runtime service.
We are now looking at the following questions:
- how does webapp access APIs for their main service, of back end for front end service.
- how does deployed microservice access other service: discover and access?
- How data consistency can be ensured?
- is there a simpler way to manage cross microservice dependency?
The answers depend on the existing infrastructure and environment, and deployment needs.
Service routing¶
We have to dissociate intra-cluster communication versus inter clusters or cluster to external services. Without getting into too much detail of IP routing within Kubernetes some important elements of the cluster are important to remember:
- microservices are packaged as docker image and expose port. When deployed they run in a pod within a node (physical or virtual machine)
- containers can talk to other containers only if they are on the same machine, or when they have exposed port.
- Kubernetes is configured with a large flat subnet (e.g. 172.30.0.0/16) which is used for internal application traffic inside of the cluster. Each worker node in the Kubernetes cluster is assigned one or more non-overlapping slices of this network, coordinated by the Kubernetes master node. When a container is created in the cluster, it gets assigned to a worker node and is given an IP address from the slice of the subnet for the worker node.
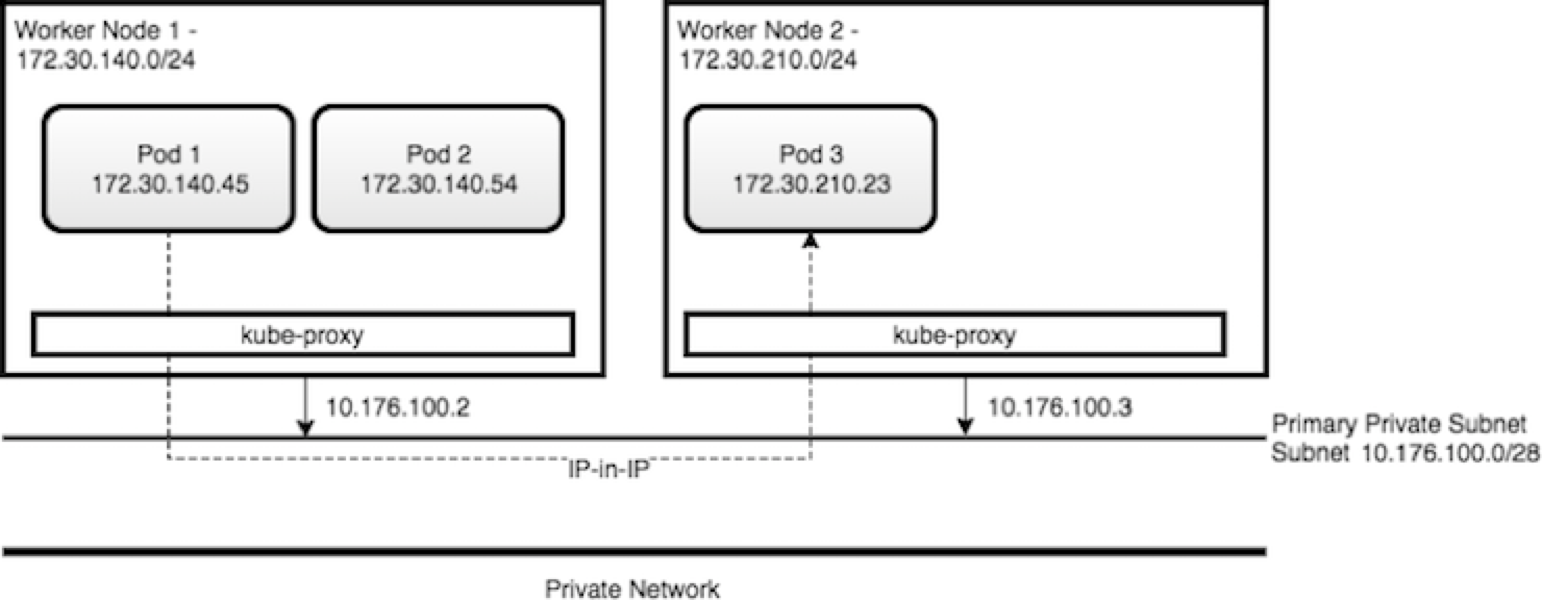
- Kube-proxy intercepts and controls where to forward the traffic, either to another worker node running your destination pod, or outside of the cluster
- Kube-proxy watches the API Server on the Master Node for the addition and removal of Services endpoints. It configures the IPtable rules to capture the traffic for its ClusterIP and forwards it to one of the endpoints.
- Worker nodes have internal DNS service and load balancer
Within Kubernetes, Ingress is a service that balances network traffic workloads in your cluster by forwarding public or private requests to your apps. You use ingress when you need to support HTTP, HTTPS, TLS, load balancing, expose app outside of the cluster, and custom routing rules...
One ingress resource is required by namespace. So if microservices are in the same namespace you can define a domain name for those services (e.g. assetmanagement.greencompute.ibmcase.com) and defined path for each service:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: assetmanagement
spec:
rules:
- host: assetmanagement.greencompute.ibmcase.com
http:
paths:
- path: /assetconsumer
backend:
serviceName: asset-consumer-svc
servicePort: 8080
- path: /assetdashboard
backend:
serviceName: asset-dashboard-bff-svc
servicePort: 8080
- path: /assetmgrms
backend:
serviceName: asset-mgr-ms-svc
servicePort: 8080
serviceName matches the service exposed for each components. The following diagram presents how an external application accesses deployed microservice within Kubernetes pod. The following diagram shows how Ingress directs communication from the internet to a deployed microservice:
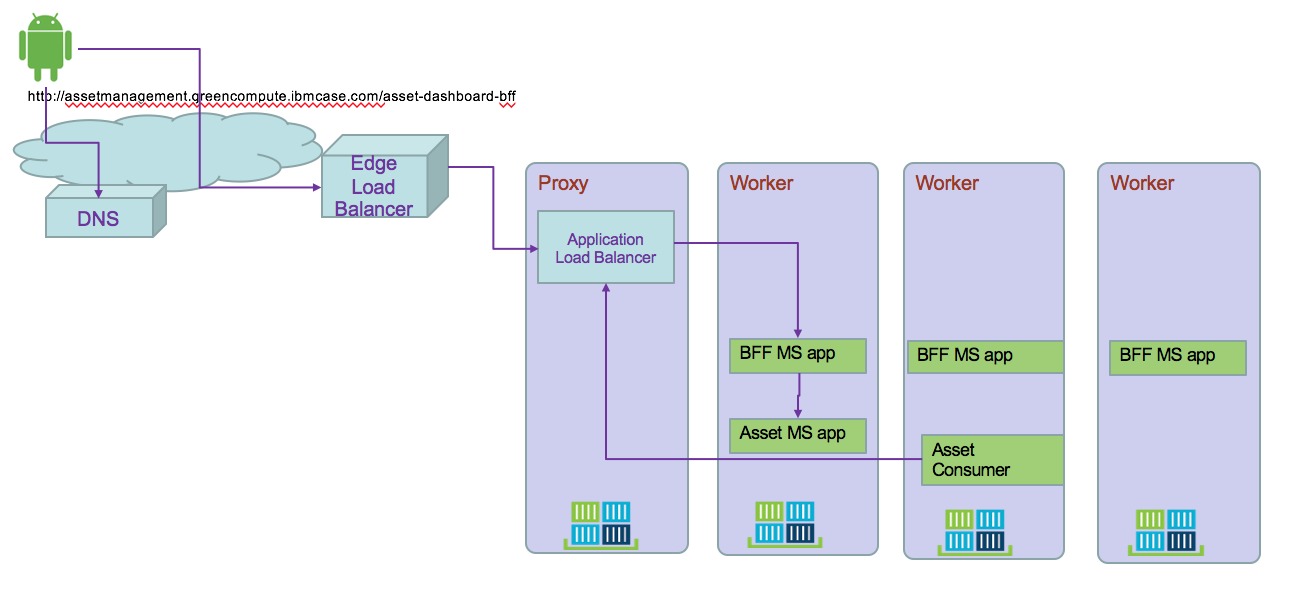
- A user sends a request to your app by accessing your app's URL. DNS name abstracts the application from the underlying infrastructure. Inter clusters microservice to microservice should use the same approach
- A DNS system service resolves the hostname in the URL to the portable public IP address of the load balancer
- Based on the resolved IP address, the client sends the request to the load balancer service that exposes the Application Load Balancer (ALB)
- The ALB checks if a routing rule for the app path in the cluster exists. If a matching rule is found, the request is forwarded according to the rules that you defined in the Ingress resource to the pod where the app is deployed. If multiple app instances are deployed in the cluster, the ALB load balances the requests between the app pods. To also load balance incoming HTTPS connections, you can configure the ALB to you can use your own TLS certificate to decrypt the network traffic.
- Microservice to microservice can use this DNS name to communicate between them.
Using Ingress, the global load balancer can support parallel, cross region clusters.
Service exposition¶
There is an architecture style focusing on APIs which proposes to have different SLA and semantic for external, internet facing API versus internal back end APIs only exposed within intranet.
Backend data services are not exposed directly to internet. API Gateway provides a secure end point for external web app to access those business functions.
So the decisions on how to expose service are linked to:
- do you need to do API management
- do you need to secure APIs
- do you need to expose to internet
- do you need to support other protocol then HTTP
- do you need to have multiple instances of the application
When deploying a microservice to Kubernetes it is recommended to use Ingress rule as presented above.. The following yaml file exposes the BFF service using ClusterIP:
apiVersion: v1
kind: Service
metadata:
name: asset-consumer-svc
labels:
chart: asset-consumer
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
protocol: TCP
name: asset-consumer-svc
selector:
app: asset-consumer
Service discovery¶
When deploying on Kubernetes cluster, microservices use the DNS lookup to discover deployed microservice.
ISTIO¶
ISTIO provides an easy way to create a network of deployed services with load balancing, service-to-service authentication, traffic flow management, monitoring, etc... By deploying a special sidecar proxy (called Envoy) throughout your environment, all network communication between microservices is intercepted and controlled by ISTIO control panel.
The control plane manages the overall network infrastructure and enforces the policy and traffic rules.
More reading
- Istio and Kubernetes 101
- Advanced traffic management with ISTIO
- Istio workshop for IBM Cloud Container service for inspiration but this repository was not touched since 4 years.
Asynchronous loosely coupled solution using events¶
If we change of paradigm and use a messaging approach or better an event approach of the data update requirements, we will implement a loosly coupled solution with a pub/sub communication protocol. We need to think about the activities that apply within each service and how they can be of interest to other components. Internal microservice tasks are becoming facts about something happened and those facts may be published as events for others to consume. The first level of refactoring may become:
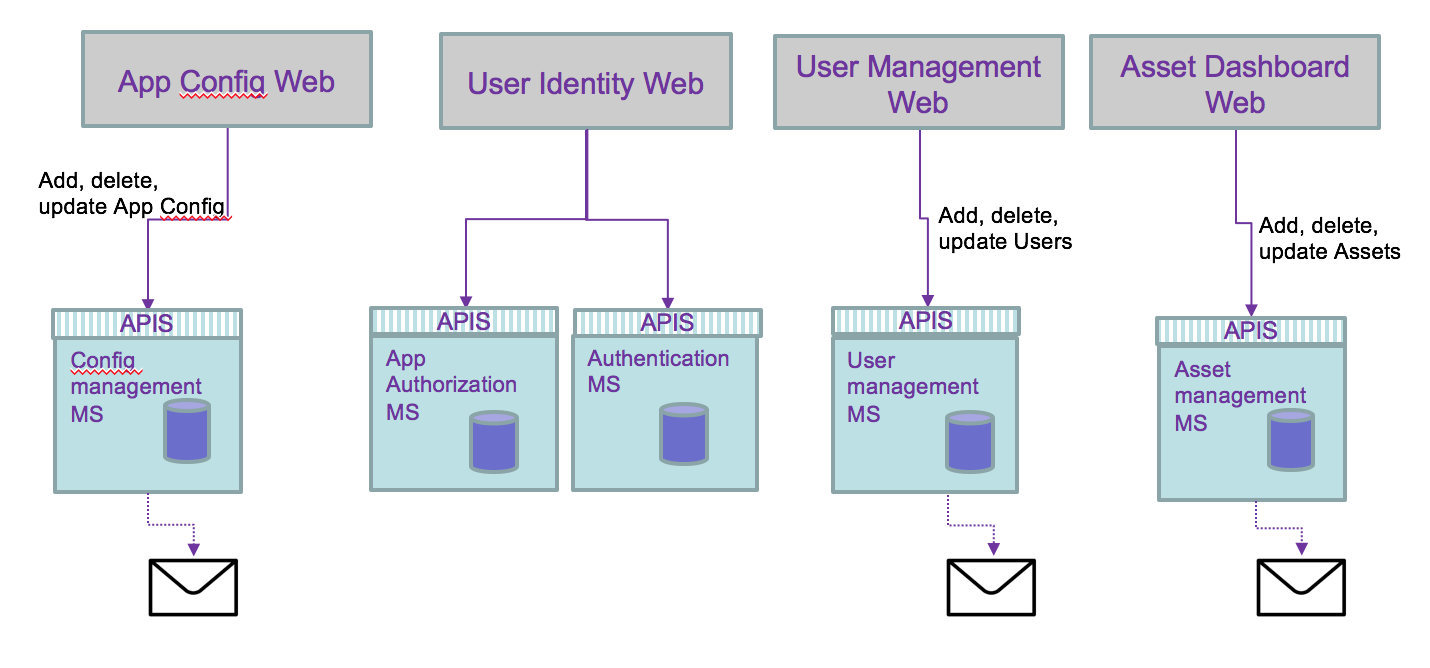
An event is a fact that happens in the past and carry all the data needed, and it becomes a source of record. It becoming consistent if it is played in a messaging backbone via topics.
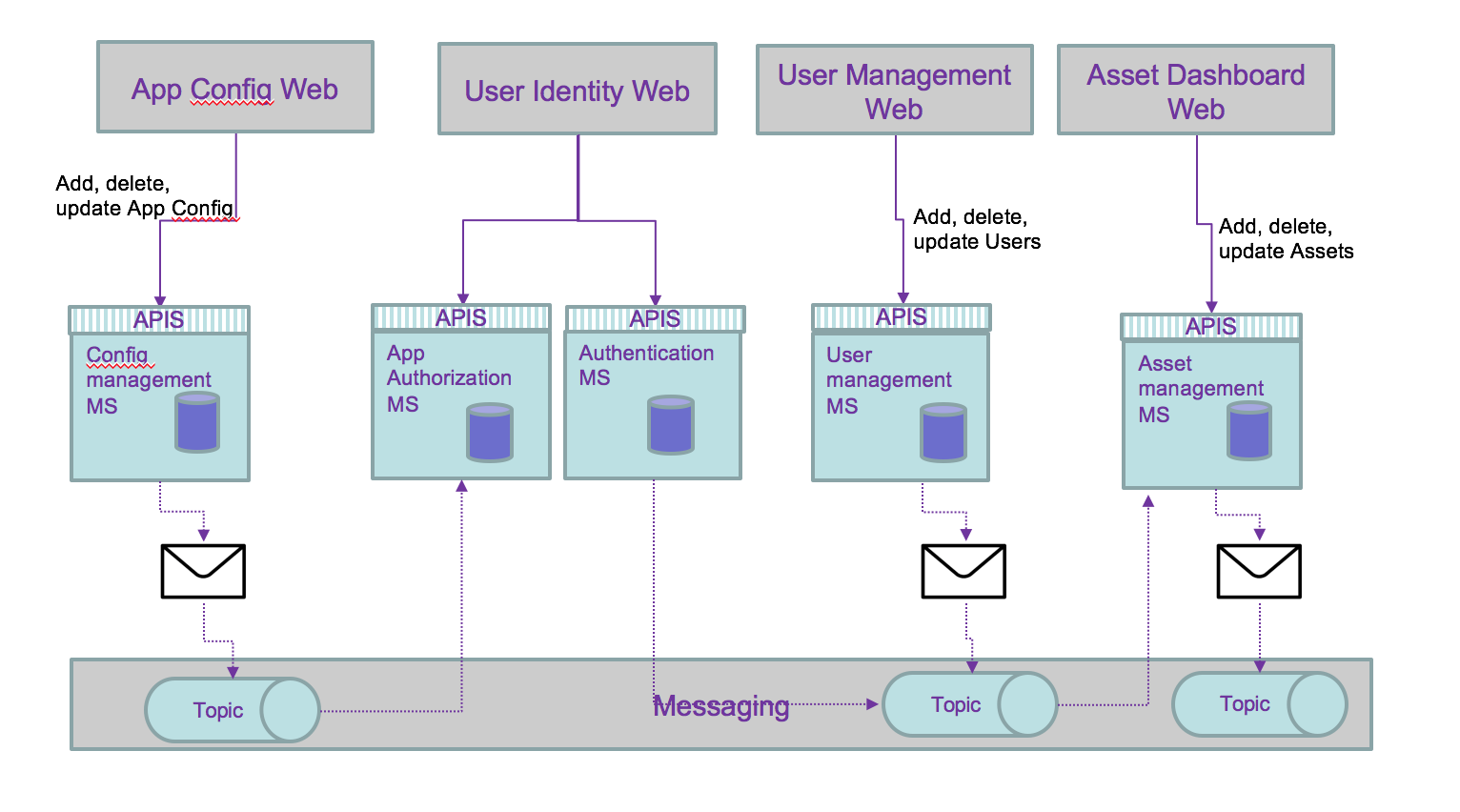
But the persistence of data can be externalized to consumer and then simplify the architecture:
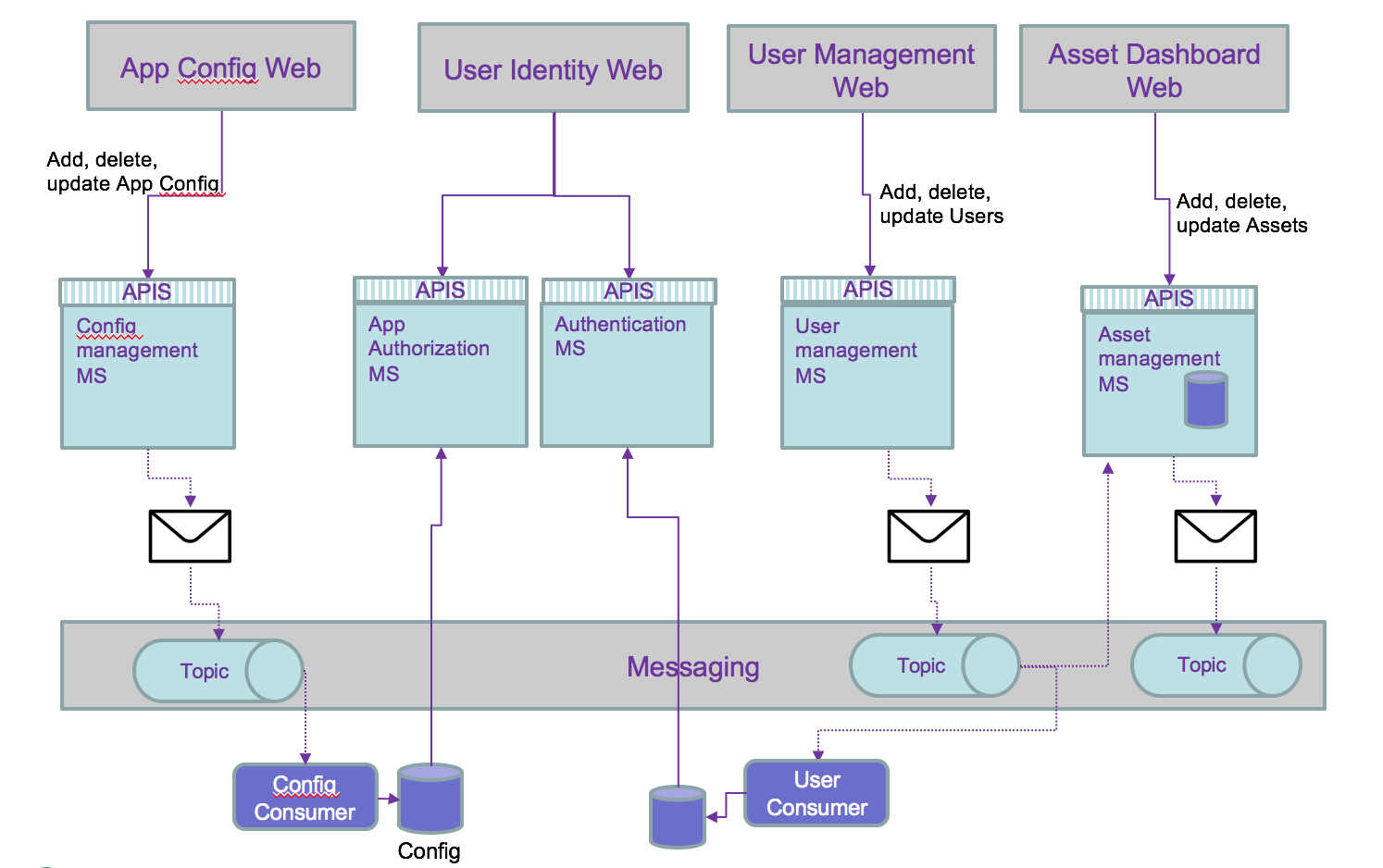
Then we can use the history of the persisted events to add features not address before, and outside of the direct scope of a microservice. For example to compute the number of users added last month, just a query on the users topic will get the answer: no or very limited coding needed.
We recommend to go deeper in event driven architecture with this site