Devising the data models
Updated 06/18/2022
The development of modern business application using cloud native microservices, long running business processes, decision services, different data stores, events, existing software as service like CRM or ERP applications, AI,... are adding complexity on the data view, data transformation and the data modeling. Some older approaches of adopting a unique canonical model, has some advantages and some counter productive ones.
With microservice adoption, and applying domain driven design, it is easier to define a bounded context for microservice, but as soon as you start coding you immediately encounter questions about your information model and what shapes it should have. Canonical model is kept at the messaging or integration layer to do a one to one mapping between models.
This note presents the reality view of the different data model to consider. The goal is still to apply clear separation of concern, focus on data needed for implementing business logic, and adapt interface for easy consumption and reuse.
The following figure illustrates a potential business automation solution using different components, supported on top of different software products.
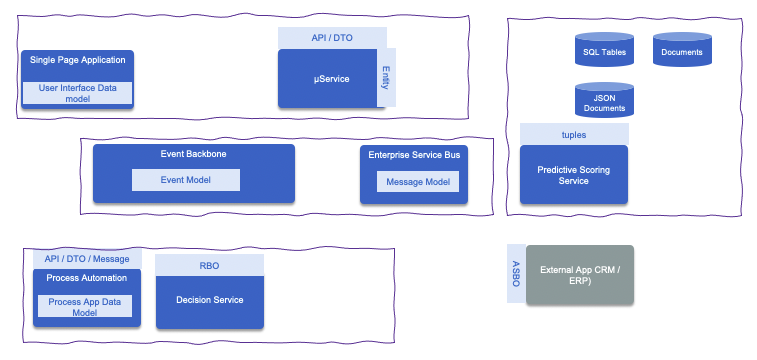
From Top-Left bottom right:
- Single Page applications are running in Web Browser and use different javascript library to support HTML rendering, business logic implementation and data model as JSON document. The model view is focusing to expose data to user and to support form entries. The app interacts with one Backend For Frontend app's REST API or other services with CORS support. The model and API are designed for this user centric application.
- Microservices are exposing model via their APIs, in Java EE, it used to be named Data Transfer Object, and it is still used, named this way in microservice. The focus on this model is to enforce reusability, and expose APIs about the main business entity or aggregate (Domain Driven Design - Aggregate). This entity is persisted in different formats, and when using traditional SQL based technology, Object Relational Mapping is needed. In Java, hibernate ORM is used with JPA to support transaction and entity annotation. Quarkus Panache is a nice way to map business entity transparently to DB. But still we need to design those models. Within the microservice, we will also find specific implementation model used to support the business logic the service implements.
- The adoption of JSON document to get a more flexible, schemaless model, helps at the technology selection to be more agile as the model can evolve easily, but still we need to think and design such models.
- Modern business applications are using Artificial Intelligence model. To make it more generic, we defined a predictive scoring service which computes a score between 0 to 1, given a feature set represented as tuples. It does not have to be a predictive scoring and can be anything a machine learned model can support, but it is exposed with an API and a flat data model.
In the middle we have an integration layer:
- The modern event backbone to support event streaming. The event model is also defined with schemas, and any application producing such events, needs to have a specific model to represent fact, of what happens in their boundary.
- Enterprise service buses are still in scope, as service gateway, interface mapping, and heteregeonous integration are needed. The model definition will better fit to the adoption of canonical model to facilitate the one to one mapping between source and destination models.
- Those integration can do data mapping with application like CRM, ERP running as system. The name ASBO, for application specific business object, was used in the past, and it still applies in modern solutions. We need to consider them as-is or by using mapping to internal models.
- Some business applications need to get human involved, in the form of workflow, where process application implements the workflow and define process variables to keep data between process tasks. Those data are persisted with process instances within the Business Process Management datasource. The business process can be triggered by user interface (claiming to start a process), by exposing a service, in this case we are back to the DTO definition, or triggered asynchronously via messages (back to a message model).
- Externalizing business rules, is still a relevant pattern, and in the case of decision modeling, a specific data model to support the rules inference and simplify the rule processing is needed. This is what we called RBO: Rule Business Object in the Agile Business Rule Development methodology.
The persisted information model (in system of records or DB) is different than the process variables in BPM, which is different than the rule business object model used to make decisions.
A good architecture leverages different information model views to carry the data to the different layers of the business application: the user interface, the database, the service contract, the business process data, the messaging structure, the events, the business rules, the raw document, the AI scoring input data.... There is nothing new in this, but better to keep that in mind anyway when developing new solutions.
The information model for such service has to be designed so there is minimum dependency between consumers and providers. The approach of trying to develop a unique rich information model to support all the different consumers, may lead having the consumers dealing with complex data structure sparsely populated, and will increase coupling between components.
When defining service specifications it is important to assess if each business entities supported by the service operations is going to have different definitions or if the same definition applies to the whole service portfolio?
The scope of reuse of data types is an important architecture decision; there is no one-size-fits-all solution. However, a few different patterns are emerging:
- One object model per interface: Using an independent data model for every service interface assures the highest level of decoupling between services. As negative, the consumers have to understand different representations of the same business entities across multiple services and have to cope with all the relative data transformations. This strategy can be very effective for coarse-grained service operations that do not exchange large amount of data with consumers.
- One object model per business domain: the service information models are organized in domains, every domain sharing the same data model. The downside of this approach, is once domains are defined, changing their boundaries can be costly.
- A single object model for the whole enterprise: the approach is to define a single common set of data structures shared across all the enterprise service interfaces. The amount of model customization is kept to a minimum and its management is centralized. The negatives are having overly complicated model the consumers need to process. As of now it becomes a bad practices to adopt such canonical model at the API, persistence and eventing level.