Real-time inventory solution design¶
This use case is coming from four customer's engagements since the last three years.
Duration: 30 minutes
Pre-requisites - MAC Users¶
- Have a git client installed
- Have a git account into IBM Internal github or public github.
- A JDK 11.
-
Install the make tool:
brew install make
-
Have oc cli installed. It can be done once connected to the OpenShift cluster using the <?> icon on the top-right and "Command Line Tool" menu.

-
Get a Java development IDE, we use Visual Code in our group.
- Install Java Coding Pack for Visual Studio. This will download JDK and the necessary plugins.
-
OCP access with CP4I installed, could be ROKS, TechZone with CP4I cluster, we are using CoC environment as a base for our deployments See environment section for your assigned cluster
-
To access to the git repository click on the top right icon from the documentation page:

ibm-cloud-architecture/eda-tech-academy
Fork this repository to your own git account so you can modify content and deploy code from your repository when using GitOps.
and then clone it to your local laptop:
Environments¶
We have two OpenShift clusters available with 25 userids each.
- Finn cluster is console-openshift-console.apps.finn.coc-ibm.com
-
Cody cluster is console-openshift-console.apps.cody.coc-ibm.com
-
Userids will be finn1 to finn25 for Finn cluster
- Userids will be cody1 to cody25 for the Cody cluster.
Scripts¶
All the scripts and configurations were developed from a Mac so no problem for you.
Pre-requisites - Windows Users¶
- Have a git client installed
- Have a git account into IBM Internal github or public github.
- Clone https://github.com/ibm-cloud-architecture/eda-tech-academy/ repositary:
In GitHub Desktop, Choose to clone a URL. Enter the above URL.
Clone to a local folder (e.g. C:\GitHub).
Ensure the C:\Github folder and sub folders do not have the ‘Read Only’ turned on. - Install Visual Code.
https://code.visualstudio.com/ .
Ignore the warning about installing as an Admin user and continue.
In the ‘Additional Tasks’ screen, pick all the tasks. - Install Java Coding Pack for Visual Studio.
https://aka.ms/vscode-java-installer-win .
This will download JDK and the necessary plugins. -
Setup Windows Subsystem For Linux.
Enable WSL. Open a PowerShell screen and run this command. Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux. This step will require a Reboot of the machine. Proceed to reboot. Enable Virtual Machine Feature dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart. [May require restart for Windows 11] Download and install the Linux kernel update package. [https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi] If you are in a Windows 11 environment, you may have to set the default WSL version to 1. wsl --set-default-version 1. Download and install Ubuntu Linux distribution from Microsoft Store. https://aka.ms/wslstore Search for Ubuntu and click on ‘Get’. This will download and install Ubuntu terminal environment with WSL. Once installed Click on ‘Open’. The first time, it will take some time to decompress some files. Wait for this step to complete. At the end, you’ll be asked to create a username and password to be used to login. Finally, you will be in the Linux shell prompt. Subsequently, open a CMD (or PowerShell) terminal and enter ‘bash’ to get access to the Linux shell. -
Setup a few tools in the Ubuntu system. Run these commands in the Ubuntu Shell screen.
Install dos2unix. sudo apt-get update. sudo apt-get install dos2unix. Install 'oc' CLI. wget https://downloads-openshift-console.apps.cody.coc-ibm.com/amd64/linux/oc.tar --no-check-certificate. tar -xvf oc.tar. sudo mv oc /usr/local/bin. Install 'make' sudo apt install make. Install 'zsh' shell. sudo apt install zsh. -
OCP access with CP4I installed, could be ROKS, TechZone with CP4I cluster, we are using CoC environment as a base for our deployments See environment section for your assigned cluster
-
To access to the git repository click on the top right icon from the documentation page:
ibm-cloud-architecture/eda-tech-academy
Fork this repository to your own git account so you can modify content and deploy code from your repository when using GitOps.
and then clone it to your local laptop:
Environments¶
We have two OpenShift clusters available with 25 userids each.
- Finn cluster is console-openshift-console.apps.finn.coc-ibm.com
-
Cody cluster is console-openshift-console.apps.cody.coc-ibm.com
-
Userids will be finn1 to finn25 for Finn cluster
- Userids will be cody1 to cody25 for the Cody cluster.
Problem statement¶
Today, a lot of companies which are managing item / product inventory are facing real challenges to get a close to real-time view of item availability and global inventory view. The solution can be very complex to implement while integrating Enterprise Resource Planning products and other custom legacy systems.
Acme customer is asking you to present how to address this problem using an event-driven architecture and cloud native microservices.
Normally to do MVP, we propose to use an Event Storming workshop to discover the problem statment, the stakeholders, the business goals, and the business process from an event point of view. The image below is an example of the outcomes of such event storming session.
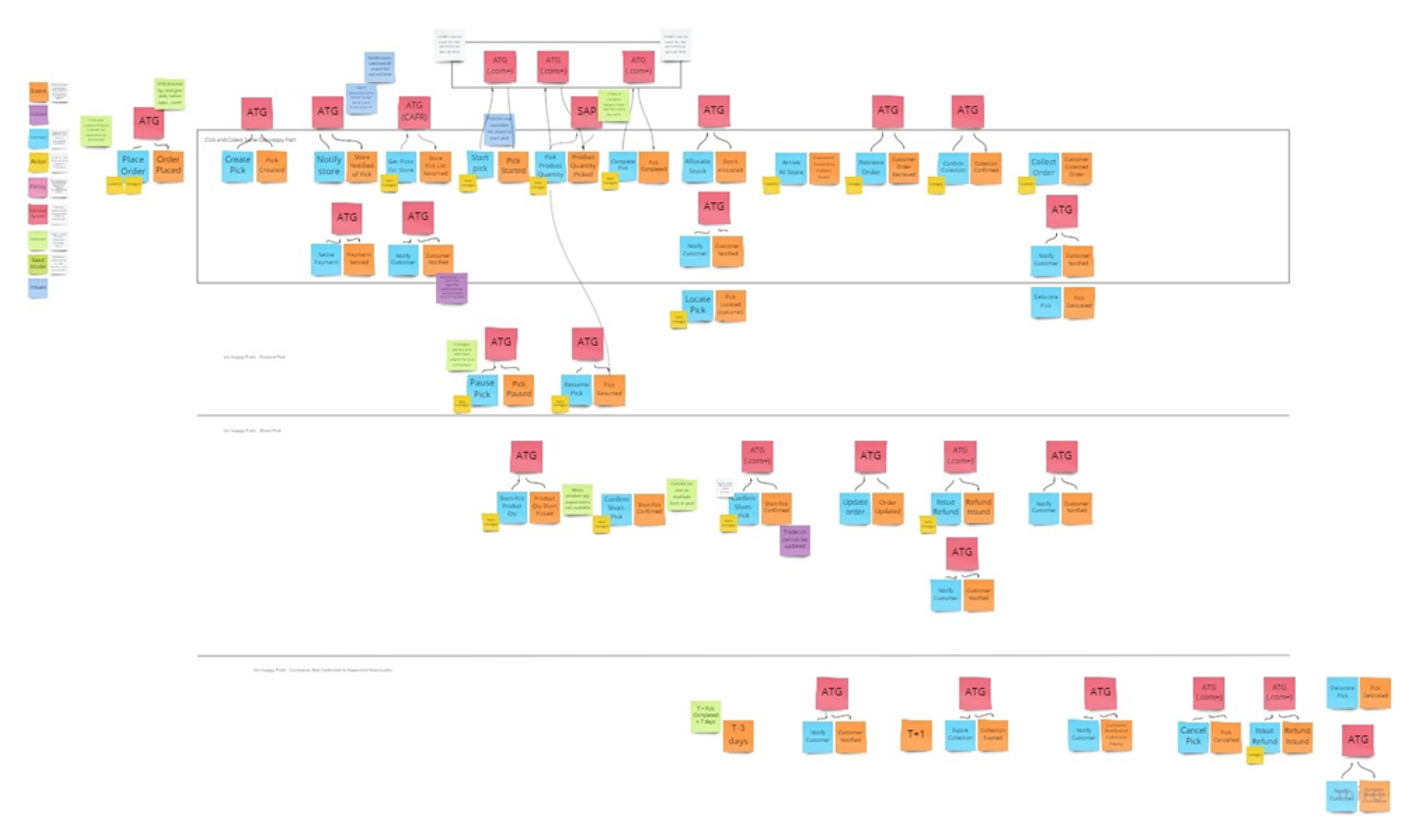
A MVP will be complex to implement, but the customer wants first to select a technology, so a proof of concept needs to be done to guide them on how our product portfolio will address their problems.
How to start?
Exercise 1: system design¶
Giving the problem statement:
How to design a near real-time inventory view of Stores, warehouses, scaling at millions of transactions per minutes?
how do you design a solution, that can get visibility of the transactions, at scale, and give a near-real time consistent view of the items in store, cross stores and what do you propose to the customer as a proof of concept.
Start from a white page, design components that you think will be relevant.
Duration: 30 minutes
Expected outcome
- A diagram illustrating the design. If you use Visual Code you can get the drawio plugin
- A list of questions you would like to see addressed
Some information you gathered from your framing meeting¶
- SAP is used to be the final system of record
- Company has multiple stores and warehouses
- Sale and restock transactions are in a TLOG format
- Stores and warehouses have local view of their own inventory on local servers and cash machines.
- Some inventory for warehouses and transactions are done in mainframe and shared with IBM MQ
- Item has code bar and SKU so people moving stock internally can scan item so local system may have visibility of where items are after some small latency.
- The volume of transactions is around 5 millions a day
- Deployment will be between 3 data centers to cover the territory the company work in.
- Customer has heard about kafka, but they use MQ today, CICS, Java EE applications on WebSphere
- Architect wants to deploy to the cloud and adopt flexible microservice architecture
- SAP system will stay in enterprise
- Architect wants to use data lake solution to let data scientists develop statistical and AI models.
Guidances
- Think about enterprise network, cloud providers, stores and warehouses as sources.
- SAP - Hana is one of the system of record and will get data from it
- It is also possible to get data before it reaches SAP
- SAP has database tables that can be used as source of events
- As warehouse systems are using MQ, queue replication is something to think about
What could be a PoC scope?
- You may want to demonstrate Event Streams capabilities as Kafka backbone
- You want to demonstrate MQ source connector to get message from MQ to Kafka
- You may want to explain how messages are published from a microservice using Microprofile Reactive Messaging
- The real-time aggregation to compute store inventory can be done with streaming processing, and Kafka Streams APIs can be used for that.
- For Data lake integration, you can illustrates messages landing in S3 buckets in IBM Cloud Object Storage using Kafka Sink connector.