Real-time inventory demonstration¶
This repository uses OpenShift GitOps to manage the deployment of the real-time inventory demonstration.
What you will learn¶
- Use Quarkus, with reactive programming API like Mutiny, and Kafka API to produce messages to Kafka
- Same Quarkus app can generate messages to RabbitMQ using the AMQP API
- Same Quarkus app can generate messages to IBM MQ using JMS
- Use Quarkus and Kafka Streams to compute aggregates to build an inventory view from the stream of sale order events
- Use IBM Event Streams, Kafka Connector
- Use the RabbitMQ source connector from IBM Event messaging open source contribution
- Use the IBM MQ source connector from IBM Event messaging open source contribution
Why to consider¶
This project can be a good foundation to discuss GitOps deployment, and reuse scripts, makefile... to deploy any event-driven solution.
As a developer you will use Microprofile reactive messaging, Kafka Streams API, Quarkus and OpenLiberty. Kafka IBM MQ source connector from IBM Event messaging github, Elastic search sink connector...
Use Case Overview¶
Today, a lot of companies which are managing item / product inventory are facing real challenges to get a close to real-time view of item availability and global inventory view. The solution can be very complex to implement while integrating Enterprise Resource Planning products and other custom legacy systems.
Any new solutions are adopting events as a source to exchange data, to put less pressure on existing ERP servers, and to get better visibility into inventory positions while bringing agility to develop new solution with streaming components.
This scenario implements a simple near real-time inventory management solution based on real life MVPs we developed in 2020 for different customers. The demonstration illustrates how event streaming processing help to build inventory views.
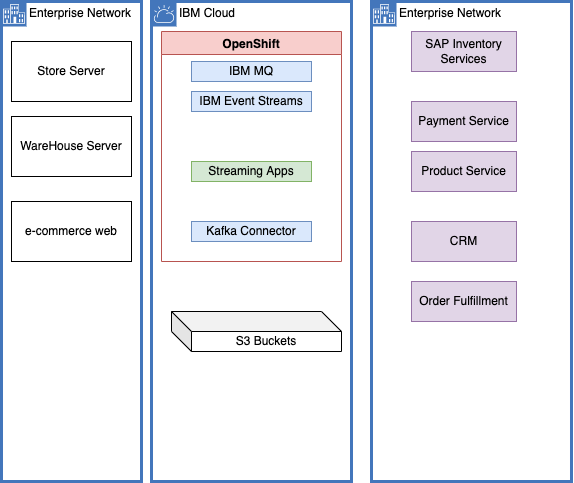
A production deployment will implement different level of store and warehouse inventory aggregators that will push results as events to an event backbone, which in our case is IBM Event Streams.
Servers in the Store are sending sale transactions to a central messaging platform, where streaming components are computing the different aggregates. This is a classical data streaming pipeline. Sink connectors, based on Kafka Connect framework, may be used to move data to long persistence storage like object storage or a Database, to integrate results back to Legacy ERP, to use indexing product like Elastic Search, or to propagate events to dashboards.
In real life, an as-is solution will include back-end applications to manage the warehouses inventory, connected to a home-built fulfillment application, combined with store applications and servers, e-commerce suite, and a set of SOA services exposing backend systems. This is the larger view of the following figure:
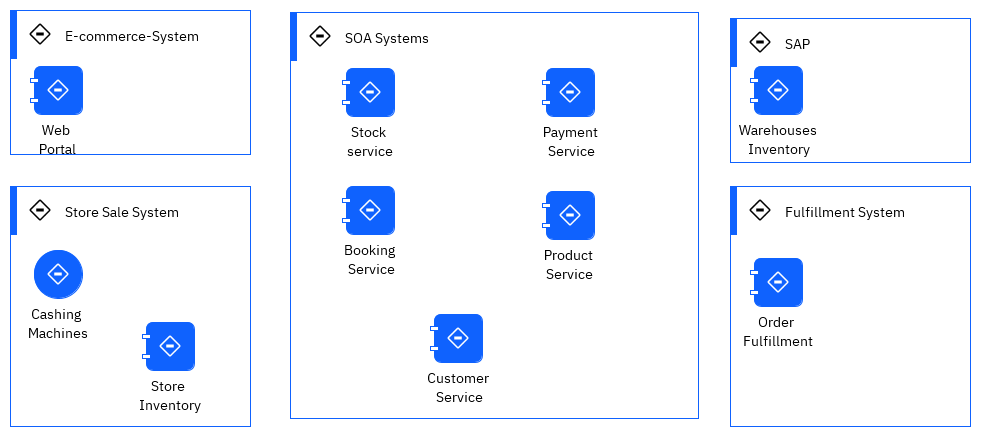
We may have integration flows to do data mapping, but most of those calls are synchronous. To get item availability, a lot of SOAP calls are done, increasing latency, and the risk of failure. There is an interesting video from Scott Havens explaining the needs from transitioning from a synchronous architecture to an event-driven asynchronous architecture when scaling, and low latency are must have. This lab reflects this approach.
Demonstration components¶
The demonstration may be used with different level of integration, and you can select those a la carte. The following diagram illustrates the current components:
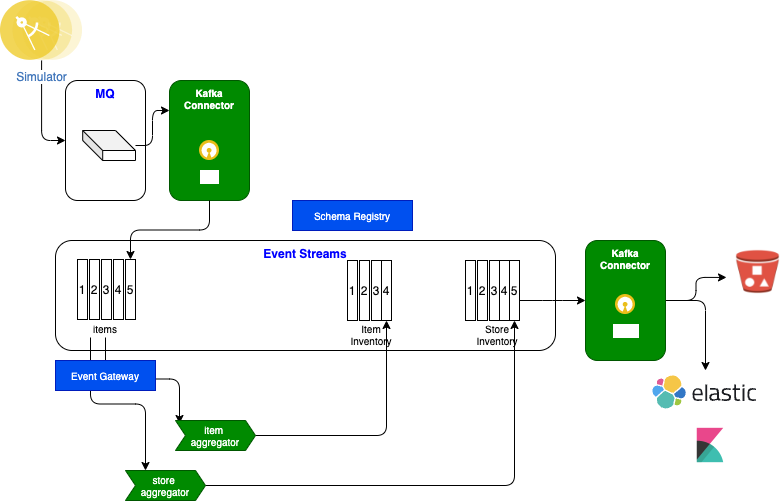
Diagram source: rt-inventory diagram
- The store simulator application is a Quarkus based microservice, used to generate item sales to different possible messaging middlewares ( RabbitMQ, IBM MQ or directly to IBM Event Streams). If you want to browse the code, the main readme of this project includes how to package and run the app with docker compose. A code explanation section may give you some ideas to developers. The docker image is quay.io/ibmcase/eda-store-simulator/ and can be used for demonstration.
- The item inventory aggregator is a stateful application, done with Kafka Stream API. The source code is in the refarch-eda-item-inventory project. Consider this more as a black box in the context of the scenario, it consumes items events, aggregate them, expose APIs on top of Kafka Streams interactive queries and publishes inventory events on
item.inventorytopic. As a developer you may want to understand the Kafka Stream programming with the following labs, and then considering looking at the classes: ItemProcessingAgent.java. - The store inventory aggregator is a Kafka Stream application, also done with Kafka Stream API. The source code is in the refarch-eda-store-inventory project. The output is in
store.inventorytopic. - When messages are sourced to Queues, then a Kafka Source Connector is used to propagate message to
itemstopics. The MQ to Kafka Kafka connect cluster is defined in the eda-rt-inventory-GitOps repository under the kconnect folder, and the source connector in environments/rt-inventory-dev/apps/mq-source - The Kafka to Cloud Object Storage Kafka (S3 bucket) connector is defined in the environments/rt-inventory-dev/apps/cos-sink folder.
- The Sink connector to Elastic Search is defined in environments/rt-inventory-dev/apps/elastic-sink folder.
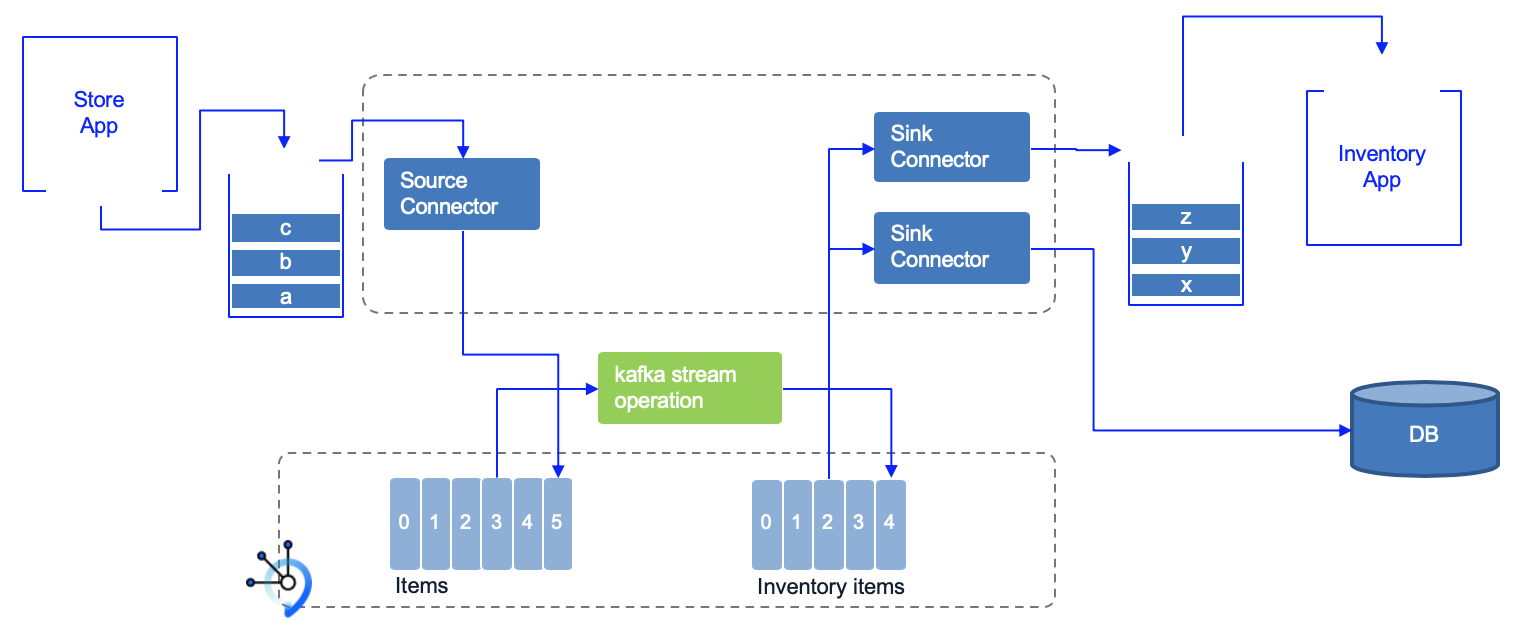
Kafka Connect is used to integrate external systems into Kafka. For example external systems can inject item sale messages to queue, from which a first MQ source Kafka connector publishes the messages to the items Kafka topic. Items sold events are processed by a series of streaming microservices which publishes aggregation results to different topics. Those topics content could be which will be used by Sink connectors to send records to other external systems.
General pre-requisites¶
- Get access to an OpenShift Cluster. All the CLI commands must be performed by a Cluster administrator. You need
oc cliand thejqJSON stream editor installed. - OpenShift CLI on your local environment.
- jq on your local environment.
- Docker and docker compose to run the solution locally.
- git CLI.
- Clone this repository
For OpenShift deployment, you need access to a cluster with storage capabilities to support Event Streams deployments like block storage configured to use the XFS or ext4 file system, as described in Event Streams storage.
You need to have at least one volume per broker and one per zookeeper instance.
See also the interactive Installation Guide for cloud pak for integration.
A GitOps approach for solution deployment¶
As any cloud-native and kubernetes based solution, we use continuous integration and continuous deployment practices. From a demonstration point of view, the most interesting part is to execute continuous deployment using a GitOps approach as presented in the EDA reference.
See the specific explanation in this section.
Choose a runtime option¶
We try to make the business scenario, easily demonstrable by enablind developer's laptop execution with docker compose or use a simple free OpenShift Cluster on IBM cloud.
- Run on your laptop
- Use GitOps on a new OpenShift Cluster
- Use Gitops on existing Cloud Pak Integration (multi-tenant)
- Without GitOps, just yaml, on a new OpenShift Cluster
- Without GitOps, just yaml, on existing Cloud Pak Integration (multi-tenant)
A non gitops approach¶
Deploy on a brand new OpenShift cluster¶
The makefile in this repository supports the minimum commands to use to deploy the different components:
# [optional]: prepare entitlementkey, IBM catalog
make prepare
# [optional]: install the different cp4i operators
make install_cp4i_operators
# Deploy the dev environment
make deploy_rt_inventory
Deploy on multi-tenant environment¶
The same makefile supports also to deploy to an existing Cloud Pak for Integration deployment with Event Streams being part of a namespace named cp4i-eventstreams:
Two different streaming approaches¶
We propose two approaches to develop the streaming processing.
- One using Kafka Streams with two applications
- One using Apache Flink
Kafka Streams implementation¶
- The Item-aggregator, based on Kafka Stream APIs, is in this project: refarch-eda-item-inventory
- The Store-aggregator, also based on Kafka Stream APIs, is in this project: refarch-eda-store-inventory
Fink implementation¶
See the refarch-eda-item-inventory-sql-flink repository for more information.
Run the solution locally¶
As a developer or technical seller, you could demonstrate this scenario on your laptop using MQ and Event Streams docker images. The docker images for each custom microservices used in this solution are in public registry (Quay.io).
Under this repository the local-demo/kstream folder has different docker compose files to run different components:
- docker-compose.yaml for Event Streams, IBM MQ, Kafka Connector the Store Simulator App, the Item aggregator App, the Store aggregator App, and KafDrop to get a user interface to Kafka.
- docker-compose-all.yaml same as above plus ElasticSearch (1 node) and Kibana
Once you have cloned the gitops repository (see pre-requisites section), go under the local-demo/kstreams
- Start local kafka, with the 3 apps, MQ and ElasticSearch services run
- As an alternate to only start Kafka, MQ and the 3 apps run:
- As another alternate without MQ and elasticSearch:
Demonstration script for local¶
The demonstration script is the same as the one described in this chapter, except that we use Kafdrop to visualize the content of Event Streams topics.
Use the simulator the console is: http://localhost:8080/#/.
If you run the controlled scenario the data are:
| Store | Item | Action |
|---|---|---|
| Store 1 | Item_1 | +10 |
| Store 1 | Item_2 | +5 |
| Store 1 | Item_3 | +15 |
| Store 2 | Item_1 | +10 |
| Store 3 | Item_1 | +10 |
| Store 4 | Item_1 | +10 |
| Store 5 | Item_1 | +10 |
| Store 1 | Item_2 | -5 |
| Store 1 | Item_3 | -5 |
Inventory should be at the store level: {"stock":{"Item_3":10,"Item_2":0,"Item_1":10},"storeName":"Store_1"} and at the item level:
| Item | Stock |
|---|---|
| Item_1 | 50 |
| Item_2 | 0 |
| Item_3 | 10 |
The store inventory API is at http://localhost:8082
The item inventory API is at http://localhost:8081
Kafdrop UI to see messages in items, store.inventory and item.inventory topics is at http://localhost:9000
- Verify Events are in
itemstopic using Kafdrop:
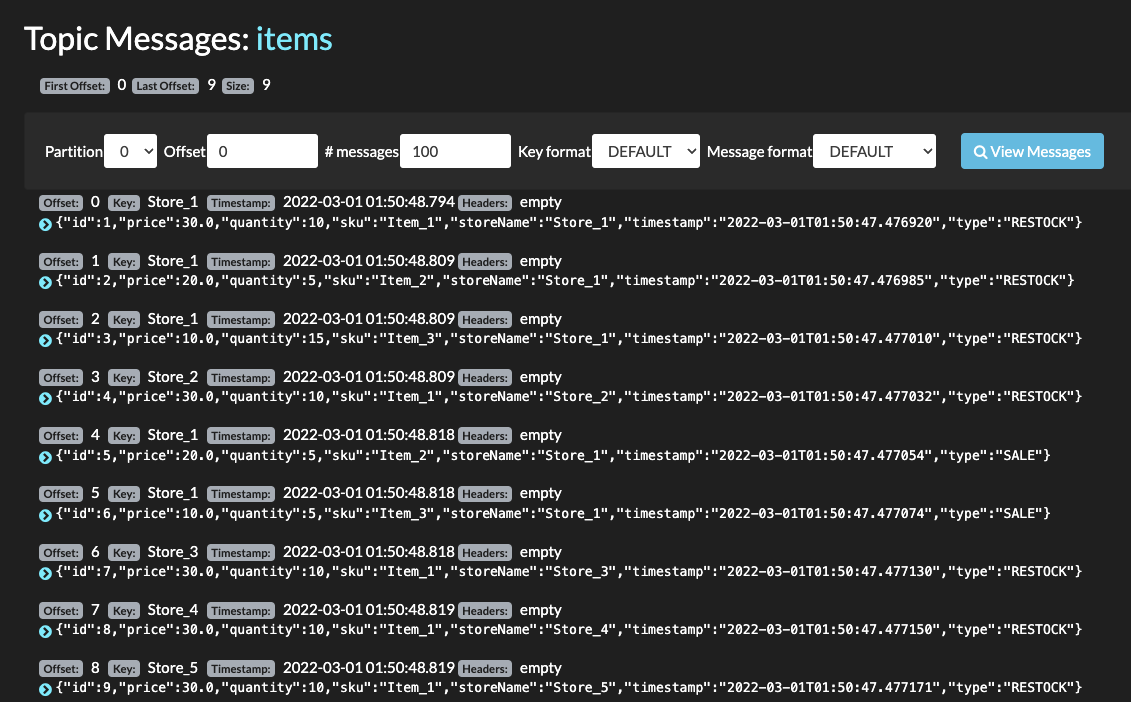
- Verify item inventory events are in
item-inventory
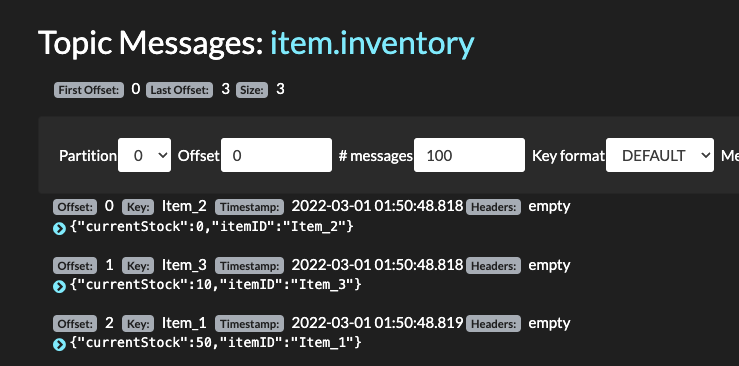
- Finally verify item inventory events are in
store-inventory
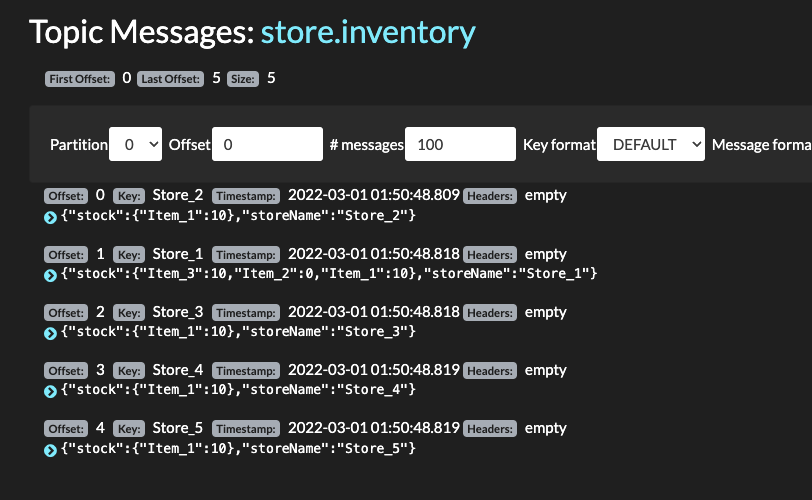
-
If using ElasticSearch go to Kibana UI at localhost:5601
-
Stop the demo: select one of the following command: